
Related subreddit graph exploration with NetworkX
Last updated March 3, 2017
Graphing Subreddits
This notebook explores some basic concepts of graph theory. A few weeks ago I set up a script to scrape data from reddit.com with the goal of visualizing the network of related subreddits (forums on specific topics) and related data.
Reddit is home over 600,000 communities, known as subreddits, where people come to share information, opinions, links, etc. and discuss things in a open forum. Most subreddits display links to related subreddits. For example, /r/apple (the Apple subreddit) links to /r/iPhone, a subreddit all about the iPhone, and over a dozen other Apple-related subreddits.
If you visit reddit.com as a guest, you will see a list of popular subreddits. This list is located inside an html tag called drop-choices. Here it is:
from selenium import webdriver
import re
import time
import numpy as np
from bs4 import BeautifulSoup
driver = webdriver.PhantomJS()
driver.get('https://www.reddit.com/')
time.sleep(4 + np.random.random())
html = driver.page_source.encode('utf-8')
s = BeautifulSoup(html)
defaults = s.find('div', attrs={'class':'drop-choices'})
subs = re.compile(r"\/r\/[\w.]+\/?")
default_subreddits = list(set(subs.findall(str(defaults))))
for x in default_subreddits: print '[' + x + '](https://reddit.com'+ x + '), ',
Here are the elements of default_subreddits:
/r/LifeProTips/, /r/Futurology/, /r/OldSchoolCool/, /r/mildlyinteresting/, /r/askscience/, /r/UpliftingNews/, /r/aww/, /r/GetMotivated/, /r/personalfinance/, /r/gadgets/, /r/science/, /r/dataisbeautiful/, /r/DIY/, /r/AskReddit/, /r/space/, /r/nosleep/, /r/Documentaries/, /r/todayilearned/, /r/television/, /r/IAmA/, /r/Art/, /r/EarthPorn/, /r/books/, /r/gifs/, /r/Showerthoughts/, /r/blog/, /r/news/, /r/Jokes/, /r/TwoXChromosomes/, /r/videos/, /r/philosophy/, /r/nottheonion/, /r/explainlikeimfive/, /r/movies/, /r/Music/, /r/WritingPrompts/, /r/worldnews/, /r/pics/, /r/history/, /r/listentothis/, /r/sports/, /r/food/, /r/creepy/, /r/announcements/, /r/gaming/, /r/tifu/, /r/funny/, /r/photoshopbattles/, /r/InternetIsBeautiful/,
My goal here is to see how many subreddits we can reach as we branch off of these "default" subreddits into their related subreddits.
First, we need to set up data structures to hold data for subreddits and their related subreddits. And we need to define an algorithm for collecting data.
Here's an intrdoduction to graphs from python.org:
Few programming languages provide direct support for graphs as a data type, and Python is no exception. However, graphs are easily built out of lists and dictionaries. For instance, here's a simple graph (I can't use drawings in these columns, so I write down the graph's arcs):
A -> B
A -> C
B -> C
B -> D
C -> D
D -> C
E -> F
F -> C
This graph has six nodes (A-F) and eight arcs. It can be represented by the following Python data structure:
graph = {'A': ['B', 'C'],
'B': ['C', 'D'],
'C': ['D'],
'D': ['C'],
'E': ['F'],
'F': ['C']}
First let's define how we would go only one branch deep into this graph (i.e. find the related subreddits for only the default subreddits). To collect the data, I first looped through the default subreddits and save the html of each subreddit to its own text file. Here's a script with comments:
#first we navigate to the correct folder where we will store the first level of related subreddits
os.chdir(os.path.expanduser('~/Documents/Projects/Data/Subreddits/one/'))
#next we instantiate the webdriver we will be using: PhantomJS
driver = webdriver.PhantomJS()
#loop through the list of default subreddits
for num, subreddit in enumerate(default_subreddits):
#for each subreddit, we append the /r/subreddit path to the base URL (reddit.com)
driver.get('https://www.reddit.com'+subreddit)
#wait for two seconds
time.sleep(2 + np.random.random())
#save the html of the loaded page to a variable: html
html = driver.page_source.encode('utf-8')
#remove '/r/' from the subreddit name string
name = subreddit.split('/')[2]
#open a new file and give it the name of the subreddit we just scraped
subreddit_html_file = open(name+'.txt', 'w+')
#write the html contents to the file
subreddit_html_file.write(html)
#clost the file
subreddit_html_file.close()
#print out the number and name of the subreddit we just scrapped to make sure things are working
print str(num) + ' ' + subreddit,
Next, we want to go through each file and extract the information we want. Here's what we will be getting:
- Number of subscribers
- Subreddit description
- Date created
- Related subreddits
For this type of project, I prefer to loop through each page and creating several small dictionaries for each data point, then combine the small dictionaries into a large dictionary, and then append the dictionary to a list of dictionaries. Once I have looped through all of the pages, I can create a pandas DataFrame from the list of dictionaries. This allows me to easily manipulate the data. Here's the script that I used to do this:
#navigate to where the html files are stored (I moved them around a bit so it is not consistent with the script above)
os.chdir('E://DATA/Subreddits/subreddits_html/')
#generate a list of files that we will loop through
files = os.listdir('E://DATA/Subreddits/subreddits_html/')
#set up an empty list that we will append dictionaries to
dict_list = []
#loop through the files
for file_ in files:
#print out the name of the current file in the loop
print file_,
#open the file
f = open(file_, 'r')
#read the file contents to a local variable
html = f.read()
#create a BeautifulSoup object that we will use to parse the HTML
b = BeautifulSoup(html, 'lxml')
#get the subreddit name that we are working with (from the `file` variable)
subreddit_name = '/r/' + file_[:-4].lower()
#put the name into a dictionary
subreddit_name_dict = {'subreddit':subreddit_name}
#get number of subscribers
subs = b.find('span', attrs={'class':'subscribers'})
#if the number of subscribers is displayed on the page, then we find it and add it to a dictionary
if subs:
subs = b.find('span', attrs={'class':'subscribers'}).find('span', attrs={'class':'number'}).text.replace(',', '')
subs_dict = {'subscribers':int(subs)}
#if the number of subscribers is not displayed on the page, then we set the number of subscribers in the dictionary to None
else:
subs_dict = {'subscribers':None}
#similar process for the description: if the description is displayed, get it and save it to desc
#if it is not available, then desc will be set to `None`
desc = b.find('div', attrs={'class':'md'})
if desc:
desc = b.find('div', attrs={'class':'md'}).text
desc = desc.replace('\n', ' ')
desc_dict = {'description':desc}
#here we use regular expressions to find links anywhere on the page that have the structure: "/r/something/"
rel_subr = re.compile(r"\/r\/[\w.]+\/?")
#make a list of these links based on the "/r/something/" pattern
related_subreddits = rel_subr.findall(html)
#save the list to a dictionary
subreddits_dict = {'related':related_subreddits}
#same processes for recording the date that the subreddit was created: get the date from an HTML element,
#then save it to a dictionary. There were two different formats available in the HTML so I grabbed both
age = b.find('span', attrs={'class':'age'})
if age:
time1 = age.find('time')['title']
time2 = age.find('time')['datetime']
#save the date to a dictionary
time_dict = {"date1":time1, "date2":time2}
#take all the dictionaries we just created and put them together into one big dictionary
dictionary = dict(subs_dict.items()+desc_dict.items()+subreddits_dict.items()+subreddit_name_dict.items()+time_dict.items())
#append the big dictionary to the list that we defined right before the beginning of the loop
dict_list.append(dictionary)
#deconstruct the Beautiful Soup object (this can eat up memory very quickly, so it is very important when processing lots of data)
b.decompose()
#clost the file
f.close()
Next, let's save the results into a csv file. This let's us load the results quickly without having to scrape everyting again. To do this we can use the pandas library.
import pandas as pd
df0 = pd.DataFrame(dict_list, index=None)
At this point, we can go through the related column in the DataFrame and put together a list of all the related subreddits. With this list, we can simply repeat the process over and over again. However, each time we start with a new list of subreddits, we want to make sure that they have not already been collected.
Next I will read in one DataFrame that represents related subreddits "three levels deep" relative to the default subreddits.
Default --> Related --> Related --> Related
This DataFrame represents the collection of subreddits from all of these "layers" of the graph.
import pandas as pd
master_df = pd.read_pickle('pickle/master_df.p')
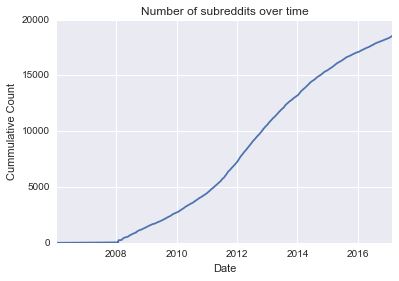
Now we can do a quick visualization of the growth in number of subreddits since the website's start in 2005.
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
master_df_ = master_df[master_df.notnull()]
master_df_.date1 = pd.to_datetime(master_df_['date1'])
list_of_dates = master_df_.date1.sort_values()
counts = np.arange(0, len(list_of_dates))
_ = plt.plot(list_of_dates, counts)
_ = plt.title('Number of subreddits over time')
_ = plt.xlabel('Date')
_ = plt.ylabel('Cummulative Count')
plt.savefig(os.path.expanduser('~/Documents/GitHub/briancaffey.github.io/img/subreddit_graph/subreddits_count.png'))
Setting up a graph with NetworkX
Next we can start to look at the collection of reddits and related subreddits as a graph. I will be using a Python package for network and graph analysis called NetworkX.
#Let's make sure that we have only unique entries in the dataframe.
master_df_u = master_df_.drop_duplicates('subreddit')
master_df_u = master_df_u.drop(master_df_u.index[master_df_u.subreddit=='/r/track__subreddits_'])
#here we define a dictionary where the keys are subreddits and the values are lists of related subreddits
graph = {x:y for x, y in zip(master_df_u.subreddit, master_df_u.related)}
#NetworkX comes with the python Anaconda distribution
import networkx as nx
G=nx.Graph()
G=nx.from_dict_of_lists(graph)
#making the graph undirected takes all of the vertices between nodes and makes them bi-directional
G1 = G.to_undirected()
choice = np.random.choice(master_df_u.subreddit, 2)
print choice
['/r/streetboarding' '/r/stephenking']
Let's test out some of the functions from NetworkX for graph analysis. First, let's take the two randomly selected nodes defined above and test to see if there exists a path between them:
nx.has_path(G1, choice[0], choice[1])
True
Shortest path
Now let's see (at least one of) the shortest path that exists between these nodes:
nx.shortest_path(G1, choice[0], choice[1])
['/r/streetboarding',
'/r/freebord',
'/r/adrenaline',
'/r/imaginaryadrenaline',
'/r/imaginarystephenking',
'/r/stephenking']
Let's write a function that selects two random subreddits and then prints a shortest path if it exists:
def short_path():
choices = np.random.choice(master_df_u.subreddit, 2)
if nx.has_path(G1, choices[0], choices[1]) == True:
path = nx.shortest_path(G1, choices[0], choices[1])
print choices[0] + ' and ' + choices[1] + ' are joined by: \n' + str(path)
else:
print "No path exists between " + choices[0] + ' and ' + choices[1]
Here's a collection of results from the short_path function defined above that start to paint a picuture of the broad set of topics covered by reddit.com:
short_path()
/r/personalizationadvice and /r/beautifulfemales are joined by:
['/r/personalizationadvice', '/r/coloranalysis', '/r/fashion', '/r/redcarpet', '/r/gentlemanboners', '/r/beautifulfemales']
short_path()
/r/caffeine and /r/shittyramen are joined by:
['/r/caffeine', '/r/toast', '/r/cooking', '/r/ramen', '/r/shittyramen']
short_path()
/r/watchingcongress and /r/iwantthatonashirt are joined by:
['/r/watchingcongress', '/r/stand', '/r/snowden', '/r/undelete', '/r/trees', '/r/iwantthatonashirt']
short_path()
/r/asksciencediscussion and /r/dogsonhardwoodfloors are joined by:
['/r/asksciencediscussion', '/r/badscience', '/r/badlinguistics', '/r/animalsbeingjerks', '/r/startledcats', '/r/dogsonhardwoodfloors']
short_path()
/r/randommail and /r/mini are joined by:
['/r/randommail', '/r/spiceexchange', '/r/cameraswapping', '/r/itookapicture', '/r/carporn', '/r/mini']
short_path()
/r/catsinsinks and /r/nzmovies are joined by:
['/r/catsinsinks', '/r/wetcats', '/r/tinysubredditoftheday', '/r/sheep', '/r/nzmetahub', '/r/nzmovies']
short_path()
/r/thoriumreactor and /r/sailing are joined by:
['/r/thoriumreactor', '/r/energy', '/r/spev', '/r/sailing']
short_path()
/r/deathnote and /r/vegetarianism are joined by:
['/r/deathnote', '/r/television', '/r/netflixbestof', '/r/naturefilms', '/r/environment', '/r/vegetarianism']
short_path()
/r/mississippir4r and /r/mathematics are joined by:
['/r/mississippir4r', '/r/mississippi', '/r/prisonreform', '/r/socialscience', '/r/alltech', '/r/mathematics']
short_path()
/r/britainsgottalent and /r/irelandbaldwin are joined by:
['/r/britainsgottalent', '/r/britishtv', '/r/that70sshow', '/r/mila_kunis', '/r/christinaricci', '/r/irelandbaldwin']
short_path()
/r/the_donald and /r/ladybusiness are joined by:
['/r/the_donald', '/r/shitliberalssay', '/r/trollxchromosomes', '/r/ladybusiness']
short_path()
/r/selfharm and /r/medlabprofessionals are joined by:
['/r/selfharm', '/r/adhd', '/r/neuroimaging', '/r/pharmacy', '/r/medlabprofessionals']
short_path()
/r/coverart and /r/phillycraftbeer are joined by:
['/r/coverart', '/r/nostalgia', '/r/upvotedbecausegirl', '/r/wtf', '/r/remindsmeofdf', '/r/beer', '/r/phillycraftbeer']
short_path()
/r/hotguyswithlonghair and /r/castles are joined by:
['/r/hotguyswithlonghair', '/r/majesticmanes', '/r/ladyboners', '/r/imaginaryladyboners', '/r/imaginarycastles', '/r/castles']
Taking a look under the hood of NetworkX and examining the algorith that finds the shortest path between any two nodes in a graph, we find that it simply boils down to:
def shortest_path(G, source=None, target=None, weight=None):
paths=nx.bidirectional_shortest_path(G,source,target)
return paths
You can read more about the bidirectional_shortest_path function here in the NetworkX documentation.
When I was first experimenting with graph algorithms, I had an interesting result using an algorithm intruduced here in the Python documentation. Here's the algorithm:
def find_path(graph, start, end, path=[]):
path = path + [start]
if start == end:
return path
if not graph.has_key(start):
return None
for node in graph[start]:
if node not in path:
newpath = find_path(graph, node, end, path)
if newpath: return newpath
return None
The above algorthim uses a process called backtracking to exaustively try all possibilities until it returns a solution. It creates an interesting "random walk" through groups of related subreddits. Here's the result of calling the above function on our graph (only 2 layers deep) with two random nodes: /r/persianrap and /r/nosleep:
/r/persianrap /r/middleeasternmusic /r/arabic /r/arabs /r/libyancrisis /r/syriancivilwar /r/yemenicrisis /r/sinaiinsurgency /r/jihadinfocus /r/credibledefense /r/geopolitics /r/forgottennews /r/libyanconflict /r/menaconflicts /r/iran /r/iranianlgbt /r/zoroastrianism /r/kurdistan /r/rojava /r/anarchism /r/imaginarypolitics /r/imaginaryimmortals /r/imaginaryclerics /r/imaginarylakes /r/imaginaryaliens /r/imaginarygnomes /r/imaginaryladyboners /r/imaginaryturtleworlds /r/imaginarysunnydale /r/imaginarydwarves /r/imaginarywizards /r/imaginaryvikings /r/imaginarycolorscapes /r/imaginarysteampunk /r/imaginarytemples /r/imaginaryblueprints /r/comicbookart /r/imaginarytechnology /r/mtgporn /r/imaginaryoldkingdom /r/imaginaryfactories /r/imaginaryfederation /r/imaginarylovers /r/imaginarynarnia /r/imaginarydwellings /r/imaginaryscience /r/imaginarytaverns /r/imaginarybattlefields /r/cityporn /r/japanpics /r/nationalphotosubs /r/austriapics /r/southkoreapics /r/taiwanpics /r/ghanapics /r/kenyapics /r/norwaypics /r/vzlapics /r/perupics /r/antarcticapics /r/greatlakespics /r/lakeporn /r/pornoverlords /r/thingscutinhalfporn /r/manufacturing /r/cnc /r/askengineers /r/sciencesubreddits /r/math /r/simulate /r/cosmology /r/reddittothefuture /r/scifi /r/lost /r/the100books /r/the100 /r/theblacklist /r/nbc /r/dundermifflin /r/sonsofanarchy /r/twentyfour /r/banshee /r/hbo /r/siliconvalleyhbo /r/siliconvalley /r/california /r/tahoe /r/skiing /r/snowshoeing /r/xcountryskiing /r/wintergear /r/skijumping /r/winter /r/bigmountain /r/mountaineering /r/campingandhiking /r/earthporn /r/nature /r/birding /r/invasivespecies /r/zoology /r/entomology /r/rainforest /r/botany /r/wildlife /r/allscience /r/earthscience /r/energy /r/biomass /r/renewablenews /r/syngas /r/climatenews /r/composting /r/vermiculture /r/organicfarming /r/livestock /r/animalwelfare /r/randomactsofpetfood /r/animalreddits /r/cockatiel /r/catpics /r/tortoises /r/whales /r/cetacea /r/lifeaquatic /r/hrw /r/green_peace /r/environmental_policy /r/conservation /r/depthhub /r/indepthsports /r/deeperhubbeta /r/lectures /r/spacepolicy /r/skylon /r/ula /r/isro /r/engineteststands /r/jupiters /r/imaginarystarscapes /r/spacequestions /r/spaceflight /r/moon /r/dione /r/europa /r/oortcloud /r/dwarfplanetceres /r/saturn /r/asteroidbelt /r/mars /r/rhea /r/venus /r/astrophys /r/spacevideos /r/transhuman /r/timereddits /r/virtualreality /r/vive /r/oculus /r/learnvrdev /r/unity3d /r/gamedev /r/crowdfunding /r/crowdsourcing /r/mturk /r/swagbucks /r/beermoney /r/flipping /r/shoplifting /r/thriftstorehauls /r/dvdcollection /r/televisionposterporn /r/concertposterporn /r/movieposterporn /r/lv426 /r/predator /r/arnoldschwarzenegger /r/alanpartridge /r/americandad /r/timanderic /r/homemovies /r/gravityfalls /r/homestarrunner /r/telltale /r/thewalkingdeadgame /r/thewalkingdeadgifs /r/twdnomansland /r/heycarl /r/twdroadtosurvival /r/thewalkingdead /r/zombies /r/guns /r/swissguns /r/opencarry /r/libertarian /r/geolibertarianism /r/basicincome /r/basicincomeactivism /r/mhoc /r/modelaustralia /r/rmtk /r/thenetherlands /r/tokkiefeesboek /r/nujijinactie /r/ik_ihe /r/youirl /r/fite_me_irl /r/2meirl4meirl /r/depression /r/randomactsofcards /r/philately /r/coins /r/coins4sale /r/ancientcoins /r/ancientrome /r/flatblue /r/bestofwritingprompts /r/writingprompts /r/promptoftheday /r/flashfiction /r/keepwriting /r/getmotivated /r/mentors /r/favors /r/recordthis /r/videography /r/animation /r/3dsmax /r/computergraphics /r/cinema4d /r/design /r/ui_design /r/designjobs /r/heavymind /r/wtfart /r/alternativeart /r/imaginaryninjas /r/imaginaryruins /r/isometric /r/imaginaryislands /r/imaginaryverse /r/icandrawthat /r/caricatures /r/imaginaryneweden /r/imaginaryequestria /r/imaginaryaww /r/imaginarycyberpunk /r/chinafuturism /r/scifirealism /r/inegentlemanboners /r/imaginarywtf /r/imaginaryelementals /r/imaginarydinosaurs /r/dinosaurs /r/speculativeevolution /r/hybridanimals /r/photoshopbattles /r/cutouts /r/battleshops /r/graphic_design /r/visualization /r/statistics /r/oncourtanalytics /r/nbaanalytics /r/nba /r/pacers /r/atlantahawks /r/basketball /r/mavericks /r/fcdallas /r/theticket /r/dallasstars /r/bostonbruins /r/patriots /r/tennesseetitans /r/nashvillesounds /r/predators /r/flyers /r/hockeyfandom /r/caps /r/nhl /r/detroitredwings /r/sabres /r/floridapanthers /r/habs /r/montrealimpact /r/alouettes /r/cfl /r/stadiumporn /r/nfl /r/madden /r/eurobowl /r/fantasyfb /r/fantasyfootball /r/49ers /r/footballgamefilm /r/footballstrategy /r/cfb /r/collegebaseball /r/mlbdraft /r/baseball /r/cubs /r/cardinals /r/saintlouisfc /r/stlouisblues /r/stlouis /r/stlouisbiking /r/mobicycling /r/bicycling /r/vintage_bicycles /r/miamibiking /r/fatbike /r/cycling /r/strava /r/phillycycling /r/wheelbuild /r/bikewrench /r/velo /r/bikepolo /r/bicycletouring /r/bicyclingcirclejerk /r/bikecommuting /r/ukbike /r/leedscycling /r/londoncycling /r/fixedgearbicycle /r/cyclingfashion /r/peloton /r/mtb /r/climbingporn /r/adrenaline /r/motocross /r/bmxracing /r/wake /r/snowboardingnoobs /r/freebord /r/snowboarding /r/sledding /r/outdoors /r/soposts /r/cordcutters /r/netflixviavpn /r/hulu /r/firetv /r/netflixbestof /r/raisinghope /r/madmen /r/earthsgottalent /r/bobsburgers /r/fringe /r/louie /r/theoriginals /r/iansomerhalder /r/kat_graham /r/indianaevans /r/janelevy /r/gagegolightly /r/sarahhyland /r/starlets /r/ninadobrev /r/kathrynnewton /r/arielwinter /r/ashleygreene /r/gentlemanboners /r/bandporn /r/musicpics /r/listentomusic /r/listentonew /r/subraddits /r/dtipics /r/damnthatsinteresting /r/interestingasfuck /r/unexpected /r/wtf /r/weird /r/animalsbeingderps /r/animalsbeingconfused /r/humansbeingbros /r/hulpdiensten /r/askle /r/protectandserve /r/good_cop_free_donut /r/bad_cop_follow_up /r/amifreetogo /r/copwatch /r/puppycide /r/underreportednews /r/mediaquotes /r/savedyouaclick /r/news /r/neutralnews /r/ask_politics /r/politicalopinions /r/gunsarecool /r/renewableenergy /r/web_design /r/somebodymakethis /r/somethingimade /r/crafts /r/kidscrafts /r/daddit /r/formulafeeders /r/boobsandbottles /r/csectioncentral /r/predaddit /r/dadbloggers /r/mombloggers /r/cutekids /r/bigfeats /r/scienceparents /r/lv9hrvv /r/sahp /r/tryingforababy /r/waiting_to_try /r/pcos /r/infertility /r/birthparents /r/tfabchartstalkers /r/firsttimettc /r/cautiousbtb /r/ttchealthy /r/xxketo /r/ketoscience /r/ketogains /r/leangains /r/gettingshredded /r/bulkorcut /r/gainit /r/decidingtobebetter /r/zen /r/buddhism /r/astralprojection /r/spirituality /r/hinduism /r/yoga /r/veganfitness /r/posture /r/health /r/ukhealthcare /r/pharmacy /r/nursing /r/doctorswithoutborders /r/humanitarian /r/assistance /r/paranormalhelp /r/paranormal /r/333 /r/askparanormal /r/intelligence /r/blackhat /r/netsec /r/technology /r/newyorkfuturistparty /r/rad_decentralization /r/massachusettsfp /r/opensource /r/alabamafp /r/darknetplan /r/torrents /r/i2p /r/privacy /r/badgovnofreedom /r/censorship /r/governmentoppression /r/descentintotyranny /r/wikileaks /r/dncleaks /r/hillaryforprison /r/the_donald /r/shitredditsays /r/srsmythos /r/srstrees /r/entwives /r/lesbients /r/actuallesbians /r/lesbianromance /r/lesbianerotica /r/l4l /r/dyke /r/ladyladyboners /r/bisexual /r/bisexy /r/biwomen /r/pansexual /r/genderqueer /r/transspace /r/lgbtlibrary /r/lgbtnews /r/dixiequeer /r/lgbt /r/sex /r/helpmecope /r/bpd /r/rapecounseling /r/trueoffmychest /r/suicidewatch /r/bipolarsos /r/bipolar /r/mentalpod /r/adhd /r/hoarding /r/declutter /r/thrifty /r/tinyhouses /r/leanfire /r/lowcar /r/zerowaste /r/simpleliving /r/livingofftheland /r/hunting /r/animaltracking /r/survival /r/vedc /r/4x4 /r/classiccars /r/automotivetraining /r/autodetailing /r/cartalk /r/mercedes_benz /r/motorsports /r/rallycross /r/worldrallycross /r/blancpain /r/nascarhometracks /r/arcaracing /r/stadiumsupertrucks /r/hydroplanes /r/sailing /r/boatbuilding /r/woodworking /r/cottage_industry /r/farriers /r/blacksmith /r/bladesmith /r/knives /r/swissarmyknives /r/switzerland /r/bern /r/sanktgallen /r/liechtenstein /r/erasmus /r/de /r/germanpuns /r/schland /r/rvacka /r/sloensko /r/slovakia /r/belarus /r/andorra /r/europe /r/hungary /r/francophonie /r/thailand /r/vietnam /r/vietnampics /r/travel /r/geography /r/climate /r/drought /r/waterutilities /r/drylands /r/irrigation /r/water /r/onthewaterfront /r/wetlands /r/marinelife /r/ocean /r/seasteading /r/frontier_colonization /r/arcology /r/retrofuturism /r/goldenpath /r/politics /r/moderationtheory /r/wdp /r/outoftheloop /r/wherearetheynow /r/entertainment /r/portlandia /r/themichaeljfoxshow /r/backtothefuture /r/bladerunner /r/filmnoir /r/vintageladyboners /r/classicfilms /r/foreignmovies /r/britishfilms /r/canadianfilm /r/newjerseyfilm /r/newzealandfilm /r/newzealand /r/wellington /r/nzmetahub /r/newzealandhistory /r/scottishhistory /r/scots /r/scottishproblems /r/britishproblems /r/swedishproblems /r/pinsamt /r/sweden /r/svenskpolitik /r/arbetarrorelsen /r/socialism /r/shittydebatecommunism /r/shittysocialscience /r/shittyideasforadmins /r/shittytheoryofreddit /r/shittybuildingporn /r/shittylifeprotips /r/shittyshitredditsays /r/shittyquotesporn /r/shittyama /r/askashittyparent /r/shittyprogramming /r/shittyaskalawyer /r/badlegaladvice /r/badscience /r/badeconomics /r/badhistory /r/historicalrage /r/metarage /r/ragenovels /r/fffffffuuuuuuuuuuuu /r/gaaaaaaayyyyyyyyyyyy /r/lgbteens /r/needafriend /r/rant /r/showerthoughts /r/markmywords /r/calledit /r/futurewhatif /r/sportswhatif /r/alternatehistory /r/maps /r/xkcd /r/kerbalspaceprogram /r/spacesimgames /r/eve /r/scifigaming /r/masseffect /r/imaginarymasseffect /r/imaginaryvampires /r/imaginarytowers /r/imaginarybestof /r/pics /r/spaceporn /r/auroraporn /r/weatherporn /r/sfwpornnetwork /r/fwepp /r/shittyearthporn /r/shittyaskreddit /r/askashittyphilosopher /r/shittyaskhistory /r/shittysuboftheweek /r/shittyaskcooking /r/shittyhub /r/coolguides /r/trendingsubreddits /r/monkslookingatbeer /r/beerporn /r/beerwithaview /r/shittybeerwithaview /r/shittyfoodporn /r/enttreats /r/trees /r/eldertrees /r/vaporents /r/crainn /r/eirhub /r/fairepublicofireland /r/gaeltacht /r/westmeath /r/tipperary /r/limerick /r/kilkenny /r/ireland /r/irejobs /r/resumes /r/careerguidance /r/flatone /r/centralillinois /r/chicubs /r/whitesox /r/minnesotatwins /r/minnesotavikings /r/greenbaypackers /r/jaguars /r/miamidolphins /r/nflroundtable /r/detroitlions /r/forhonor /r/vikingstv /r/hannibaltv /r/thepathhulu /r/batesmotel /r/hannibal /r/hitchcock /r/silentmoviegifs /r/moviestunts /r/bollywoodrealism /r/indiamain /r/indianews /r/asia /r/oldindia /r/explorepakistan /r/churchporn /r/medievalporn /r/castles /r/historyporn /r/thewaywewere /r/1970s /r/classicmovietrailers /r/warmovies /r/moviecritic /r/trailers /r/liveaction /r/animedeals /r/dbz /r/toonami /r/regularshow /r/thelifeandtimesoftim /r/aquajail /r/modern_family /r/supernatural /r/mishacollins /r/jaredpadalecki /r/fandomnatural /r/fangirls /r/trollxgirlgamers /r/trollmedia /r/trollgaming /r/trollmua /r/justtrollxthings /r/trollxmoms /r/trollmeta /r/trollychromosome /r/oney /r/askwomen /r/okcupid /r/relationship_advice /r/help /r/bugs /r/redditdev /r/enhancement /r/yoursub /r/horrorreviewed /r/truecreepy /r/metatruereddit /r/truepolitics /r/truehub /r/truegaming /r/askgames /r/freegamesonandroid /r/androidapps /r/apphookup /r/browsemyreddit /r/findareddit /r/trap /r/naut /r/militaryfinance /r/army /r/militarystories /r/nationalguard /r/uscg /r/usa /r/murica /r/lonestar /r/whataburger /r/fastfood /r/cocacola /r/kelloggs /r/kellawwggs /r/awwducational /r/marinebiologygifs /r/biologygifs /r/chemicalreactiongifs /r/homechemistry /r/holdmybeaker /r/holdmybeer /r/movieoftheday /r/sharknado /r/syfy /r/killjoys /r/theexpanse /r/truedetective /r/boardwalkempire /r/mobcast /r/1920s /r/1960s /r/beatles /r/minimaluminiumalism /r/ghostsrights /r/botsrights /r/totallynotrobots /r/robotics /r/manna /r/singularity /r/futureporn /r/singularitarianism /r/automate /r/darkfuturology /r/controlproblem /r/aiethics /r/ainothuman /r/neuraljokes /r/3amjokes /r/mommajokes /r/antijokes /r/absolutelynotme_irl /r/toomeirlformeirl /r/meirl /r/tree_irl /r/fishpost /r/mod_irl /r/pics_irl /r/teleshits /r/bitstrips /r/stopbullyingcomics /r/animalsbeingjerks /r/surfinganimals /r/unorthocat /r/catsubs /r/stuffoncats /r/catsinbusinessattire /r/catsinsinks /r/catsonkeyboards /r/mechanicalkeyboards /r/hackedgadgets /r/techsupportmacgyver /r/techsupport /r/programming /r/algorithms /r/datamining /r/datasets /r/wordcloud /r/datavizrequests /r/funnycharts /r/mapporn /r/mapmaking /r/worldbuilding /r/scificoncepts /r/apocalypseporn /r/imaginaryjerk /r/braveryjerk /r/circlejerk /r/politicaldiscussion /r/politicalfactchecking /r/moderatepolitics /r/truereddit /r/malelifestyle /r/fitness /r/swimming /r/freediving /r/bikeshop /r/climbing /r/climbharder /r/bouldering /r/climbergirls /r/womenshredders /r/skatergirls /r/girlsurfers /r/kiteboarding /r/longboarding /r/streetboarding /r/letsgosnowboarding /r/spliddit /r/backcountry /r/wjdbbl2 /r/caving /r/nationalparks /r/parkrangers /r/thesca /r/searchandrescue /r/wildernessbackpacking /r/campinggear /r/flashlight /r/camping /r/yellowstone /r/wmnf /r/pacificcresttrail /r/cdt /r/ultralight /r/backpacking /r/travelpartners /r/adventures /r/libraryofshadows /r/shortscarystories /r/shortscarystoriesooc /r/nosleepooc /r/nosleep
Centrality
Centrality is anohter important topic in graph theory. Here's a brief introduction to centrality from Wikipedia:
In graph theory and network analysis, indicators of centrality identify the most important vertices within a graph. Applications include identifying the most influential person(s) in a social network, key infrastructure nodes in the Internet or urban networks, and super-spreaders of disease.
There are several different methods of measuring centrality in a graph. Here I use eigenvector_centrality_numpy, a function included in NetworkX. It takes in a graph and returns a dictionary with graph nodes as keys and node centrality as values.
centrality = nx.eigenvector_centrality_numpy(G1)
Let's see which subreddit has the highest centrality:
print max(centrality, key=centrality.get), centrality[max(centrality, key=centrality.get)]
/r/imaginarybattlefields 0.0721530261127
len(centrality) == len(sorted(centrality.values(), reverse=True))
True
Since all of the centrality values are unique, we can look up nodes by their centrality values.
subr_list = []
for node in centrality:
subr_list.append((node, centrality[node]))
sorted_subr_list = subr_list.sort(key=lambda x: x[1])
for x in sorted(subr_list, key=lambda x: x[1], reverse=True)[:200]: print x[0],
/r/imaginarybattlefields /r/imaginarycityscapes /r/imaginarywastelands /r/imaginarywildlands /r/imaginaryleviathans /r/imaginarydragons /r/imaginarystarscapes /r/imaginarywesteros /r/imaginaryartifacts /r/imaginaryangels /r/imaginarymaps /r/imaginarybehemoths /r/imaginarydemons /r/imaginaryelves /r/imaginarycentaurs /r/imaginaryfuturewar /r/imaginarysoldiers /r/imaginaryhistory /r/imaginaryarmor /r/imaginarystarships /r/imaginarynetwork /r/imaginaryjedi /r/imaginarydinosaurs /r/imaginarysteampunk /r/imaginarycyberpunk /r/imaginaryarchers /r/imaginaryvehicles /r/imaginaryanime /r/imaginaryfallout /r/imaginaryastronauts /r/imaginarymusic /r/imaginaryfactories /r/imaginaryequestria /r/imaginarywarships /r/imaginaryazeroth /r/imaginaryarrakis /r/imaginarydisney /r/imaginarypolitics /r/imaginaryhorrors /r/imaginarywinterscapes /r/imaginaryseascapes /r/imaginarypirates /r/imaginarywarriors /r/imaginarymiddleearth /r/imaginarygallifrey /r/imaginarymechs /r/imaginarypropaganda /r/imaginarymerfolk /r/imaginaryvikings /r/imaginaryundead /r/imaginarybeasts /r/imaginarymutants /r/imaginaryruins /r/imaginarytamriel /r/imaginaryforests /r/imaginaryelementals /r/imaginaryskyscapes /r/imaginarymonuments /r/imaginarywaterfalls /r/imaginaryworlds /r/imaginarywizards /r/imaginaryinteriors /r/imaginaryhogwarts /r/imaginarytowers /r/imaginaryarchitecture /r/imaginaryweaponry /r/imaginarygaming /r/imaginarycastles /r/imaginaryrobotics /r/imaginarybooks /r/imaginarygnomes /r/imaginaryvillages /r/imaginarydeserts /r/imaginarywerewolves /r/imaginarydieselpunk /r/imaginaryvampires /r/imaginaryadrenaline /r/imaginarykanto /r/imaginarynatives /r/imaginaryrivers /r/imaginarytemples /r/imaginaryassassins /r/imaginaryvolcanoes /r/imaginaryclerics /r/imaginaryprisons /r/imaginarygiants /r/imaginarycowboys /r/imaginaryhumans /r/imaginarydwarves /r/imaginarycaves /r/imaginarytrolls /r/imaginarywalls /r/imaginarylakes /r/imaginarywitches /r/imaginaryorcs /r/imaginarycanyons /r/imaginaryasylums /r/imaginaryimmortals /r/imaginaryaliens /r/imaginarynobles /r/imaginaryspirits /r/imaginaryaetherpunk /r/imaginarytrees /r/imaginaryislands /r/imaginaryninjas /r/imaginaryscience /r/imaginarymountains /r/imaginaryknights /r/imaginarygoblins /r/imaginaryfaeries /r/imaginarygotham /r/imaginarycybernetics /r/imaginaryooo /r/imaginaryderelicts /r/imaginaryfood /r/imaginaryworldeaters /r/imaginarymindscapes /r/imaginaryaww /r/imaginarymarvel /r/imaginaryweather /r/imaginarynewnewyork /r/imaginaryspidey /r/imaginaryautumnscapes /r/imaginarywarhammer /r/imaginaryfeels /r/imaginarywitcher /r/imaginaryvessels /r/imaginarytaverns /r/imaginarybestof /r/imaginaryairships /r/imaginaryportals /r/imaginaryfashion /r/imaginarylovers /r/imaginarydc /r/imaginaryanimals /r/imaginaryhellscapes /r/imaginarycolorscapes /r/imaginarymonstergirls /r/imaginaryswamps /r/imaginarymythology /r/imaginaryscholars /r/imaginaryladyboners /r/imaginaryfuturism /r/imaginaryaviation /r/imaginarypathways /r/imaginarygatherings /r/imaginarybodyscapes /r/imaginaryoverwatch /r/imaginarydwellings /r/imaginarystephenking /r/specart /r/inegentlemanboners /r/comicbookart /r/imaginarymasseffect /r/imaginaryhalo /r/imaginaryjerk /r/backgroundart /r/futureporn /r/imaginarywallpapers /r/imaginaryfamilies /r/imaginarylibraries /r/imaginaryturtleworlds /r/imaginarydesigns /r/wallpapers /r/apocalypseporn /r/comicbookporn /r/isometric /r/imaginarybakerst /r/imaginaryverse /r/imaginarysunnydale /r/imaginaryfederation /r/imaginarysanctuary /r/starshipporn /r/imaginarystarcraft /r/imaginaryoldkingdom /r/imaginarynarnia /r/imaginarycybertron /r/gameworlds /r/imaginarycarnage /r/imaginaryboners /r/icandrawthat /r/imaginarycosmere /r/imaginaryaperture /r/armoredwomen /r/imaginarywtf /r/unusualart /r/imaginaryblueprints /r/alternativeart /r/sympatheticmonsters /r/adorabledragons /r/imaginarysummerscapes /r/imaginarygayboners /r/imaginarystash /r/artistoftheday /r/imaginaryglaciers /r/imaginaryhybrids /r/imaginaryadventurers /r/imaginarymetropolis /r/craftsoficeandfire /r/popartnouveau
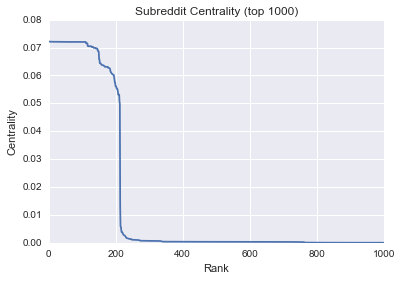
There seems to be a network of "imaginary" subreddits that have the highest centrality. The members of this network probably all link to themselves as well as many other subreddits as the "imaginary" topics span a wide range content. This network may be drowning out other nodes that would otherwise have a high centrality relative to the rest of the subreddits. It might be interesting to eliminate these nodes from the graph and recalculate centrality. Let's look at the distribution of centrality values:
_ = plt.plot(sorted(centrality.values(), reverse=True)[:1000])
_ = plt.title('Subreddit Centrality (top 1000)')
_ = plt.xlabel('Rank')
_ = plt.ylabel('Centrality')
plt.savefig(os.path.expanduser('~/Documents/GitHub/briancaffey.github.io/img/subreddit_graph/centrality.png'))
Connectedness
Let's take a look at the graph as a whole. One thing I'm not sure of is whether or not the entire graph is connected. This means that any node can be reached from any other node. Since we constructed the graph from 49 unrelated nodes, it is possible that the graph is unconnected. This would mean that one or more of the default subreddits and its subreddits is not connected with the rest of the graph. In searching for the shortest path I did not come across any pairs of nodes that did not have a path between themselves. I wouldn't be surprised if there are a handful of nodes that stand on their own.
#size of graph: nodes and edges (or, subreddits and connecting links)
print "Our graph has " + str(nx.number_of_nodes(G1)) + ' nodes and ' + str(nx.number_of_edges(G1)) + ' edges.'
Our graph has 29854 nodes and 149491 edges.
print "True of False: our graph is connected... " + str(nx.is_connected(G1)) + '!'
True of False: our graph is connected... False!
Gc = max(nx.connected_component_subgraphs(G1), key=len)
print "The largest connected component subgraph has " + str(nx.number_of_nodes(Gc)) + " nodes. "
The largest connected component subgraph has 29840 nodes.
There are 14 nodes that are not connected to the main connected component. Let's list them.
for x in list(set(nx.to_dict_of_lists(G1, nodelist=None).keys()) - set(nx.to_dict_of_lists(Gc, nodelist=None).keys())): print x,
/r/spacediscussions /r/wtfit.gif /r/space. /r/subreddit_graph /r/vidalia /r/listentothis. /r/history. /r/all. /r/ghostdriver /r/personalfinance. /r/toombscounty /r/gaming /r/science /r/books.
Some of the large communities on reddit include /r/books, /r/gaming and /r/science. These subreddits list related subreddits on separate wiki pages since there are many related subreddits for each one. They were most likely all captured in the subsequent levels of the graph, but they also did not link back to /r/science. Here's an example:
for x in master_df_u.loc[master_df_u.subreddit=='/r/physics'].related: print x
['/r/physicsjokes', '/r/gradadmissions', '/r/homeworkhelp', '/r/scienceimages', '/r/askacademia', '/r/physicsgifs', '/r/physicsstudents', '/r/gradschool', '/r/askphysics', '/r/physics']
I've got some additional ideas to explore in another post on this topic, such as finding cliques and maximual cliques, and doing graph visualizations with D3.js. If you are interested in playing with the data, you can clone my GitHub repo and load the pickled DataFrames like this:
import pandas as pd
df = pd.read_pickle('pickle/master_df.p')