Reading 13F SEC filings with python
Last updated January 30, 2018
Update: This project has been updated, please see this article to read about the most recent updates.
- https://opensecdata.ga (project staging website, deployed to docker swarm cluster running on DigitalOcean)
- https://gitlab.com/briancaffey/sec-filings-app (main repository, requires GitLab account)
- https://github.com/briancaffey/sec-filings-app (mirror, no account required to view)
The SEC Form 13F is a filing with the Securities and Exchange Commission (SEC) also known as the Information Required of Institutional Investment Managers Form. It is a quarterly filing required of institutional investment managers with over $100 million in qualifying assets. -Investopedia
In this article I will show how to collect and parse 13F filing data from the SEC.
First, use EDGAR to search the company of interest.
EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system, performs automated collection, validation, indexing, acceptance, and forwarding of submissions by companies and others who are required by law to file forms with the U.S. Securities and Exchange Commission (the "SEC"). -Wikipedia
Click on the Central Index Key (CIK) of the company you are search for, and then click on Documents.
You'll want to grab the HTML version of the Information Table. I have saved them in a folder with their file names cooresponding to their dates (YYYY-MM-DD format).
For this example, I have manually collected the files for a few years of data filed by a hedge fund. Here are the files I'll be working with:
files = os.listdir("13f/")
print(*sorted(files), sep="\n")
2014-02-14.html
2014-05-15.html
2014-08-14.html
2014-11-14.html
2015-02-17.html
2015-05-14.html
2015-08-14.html
2015-11-12.html
2016-02-16.html
2016-05-16.html
2016-08-12.html
2016-11-14.html
2017-02-14.html
2017-05-15.html
2017-08-10.html
2017-10-30.html
Here's a quick script we can use to parse information from each filing document:
def scrape_13f(file):
date = file
html = open("13f/"+file).read()
soup = BeautifulSoup(html, 'lxml')
rows = soup.find_all('tr')[11:]
positions = []
for row in rows:
dic = {}
position = row.find_all('td')
dic["NAME_OF_ISSUER"] = position[0].text
dic["TITLE_OF_CLASS"] = position[1].text
dic["CUSIP"] = position[2].text
dic["VALUE"] = int(position[3].text.replace(',', ''))*1000
dic["SHARES"] = int(position[4].text.replace(',', ''))
dic["DATE"] = date.strip(".html")
positions.append(dic)
df = pd.DataFrame(positions)
return df
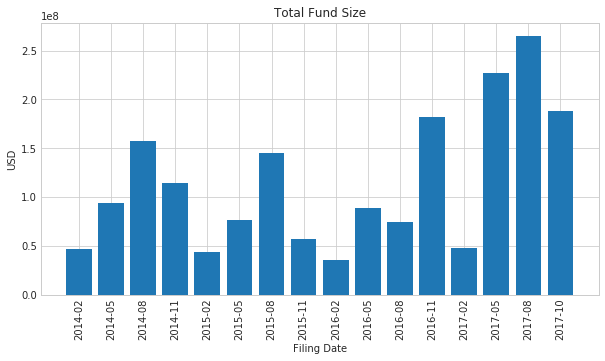
Using this function we can get a quick snapshot of this hedge fund by filing total over the last 4 years:
fund_growth = [sum(scrape_13f(file).VALUE) for file in sorted(files)]
dates = [f.strip('.html') for f in sorted(files)]
plt.figure(figsize=(10,5))
plt.title('Total Fund Size')
plt.xlabel('Filing Date')
plt.ylabel('USD')
plt.bar(dates, fund_growth)
plt.yticks()
plt.xticks(rotation='vertical')
Fund Positions with Bubble Chart
Next, it would be great to get a snapshot of the stocks owned by this fund in a given year. Let's use a D3 bubble chart. The names for each stock are quite long, so first let's convert them to stock ticker values. Here's a quick script I hacked together using a Fidelity lookup service:
cusip_nums = set()
for file in files:
cusip_nums = cusip_nums | set(scrape_13f(file).CUSIP)
ticker_dic = {c:"" for c in cusip_nums}
for c in list(ticker_dic.keys()):
url = "http://quotes.fidelity.com/mmnet/SymLookup.phtml?reqforlookup=REQUESTFORLOOKUP&productid=mmnet&isLoggedIn=mmnet&rows=50&for=stock&by=cusip&criteria="+c+"&submit=Search"
html = requests.get(url).text
soup = BeautifulSoup(html, 'lxml')
ticker_elem = soup.find('tr', attrs={"bgcolor":"#666666"})
ticker = ""
try:
ticker = ticker_elem.next_sibling.next_sibling.find('a').text
ticker_dic[c] = ticker
except:
pass
time.sleep(1)
I couldn't get all the CUSIP numbers, but I was able to get most of them. Some of the CUSIP numbers have changed for certain stocks and couldn't be looked up with this service. For now I won't fill these in. With the ticker_dic dictionary, we can make a quick edit to our scrape_13f function to populate ticker data for each holding:
ticker_dict = {'00206R102': 'T', '00507V109': 'ATVI', '00724F101': 'ADBE', ... }
def scrape_13f(file):
date = file
html = open("13f/"+file).read()
soup = BeautifulSoup(html, 'lxml')
rows = soup.find_all('tr')[11:]
positions = []
for row in rows:
dic = {}
position = row.find_all('td')
dic["NAME_OF_ISSUER"] = position[0].text
dic["TITLE_OF_CLASS"] = position[1].text
dic["CUSIP"] = position[2].text
dic["VALUE"] = int(position[3].text.replace(',', ''))*1000
dic["SHARES"] = int(position[4].text.replace(',', ''))
dic["DATE"] = date.strip(".html")
dic["TICKER"] = ticker_dict[position[2].text]
positions.append(dic)
df = pd.DataFrame(positions)
return df
Let's check this:
df = scrape_13f(files[2])
print(df[["CUSIP", "NAME_OF_ISSUER", "TICKER"]].head())
CUSIP NAME_OF_ISSUER TICKER
0 88579Y101 3M CO MMM
1 G1151C101 ACCENTURE PLC IRELAND ACN
2 02209S103 ALTRIA GROUP INC MO
3 03076C106 AMERIPRISE FINL INC AMP
4 035710409 ANNALY CAP MGMT INC NLY
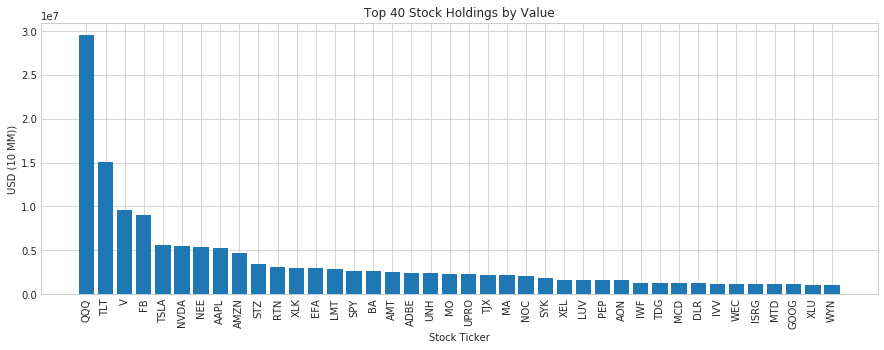
Let's take a look at the last filing, Q4 2017.
q4_2017 = sorted(files)[-1]
df_q4_2017 = scrape_13f(q4_2017)
top_20 = df_q4_2017.sort_values(by="VALUE", ascending=False)[["TICKER", "VALUE"]][:40]
a = top_20.TICKER
b = top_20.VALUE
c = range(len(b))
fig = plt.figure(figsize=(15,5))
ax = fig.add_subplot(111)
ax.bar(c, b)
plt.xticks(c, a, rotation=90)
plt.title('Top 40 Stock Holdings by Value')
plt.xlabel('Stock Ticker')
plt.ylabel('USD (10 MM))')
plt.show()