Using AWS CDK, GitLab, Fargate and CloudFront for Django + Vue.js applications
Last updated June 2, 2020
This article was originally posted on https://dev.to/briancaffey/building-a-django-vue-js-application-with-aws-cdk-and-gitlab-ci-also-how-to-scale-celery-workers-to-zero-1o6i. It is also available on the documentation site for the project: https://verbose-equals-true.gitlab.io/django-postgres-vue-gitlab-ecs/start/overview/
Project Overview
This is an overview of a Proof-of-Concept web application I'm working on called django-postgres-vue-gitlab-ecs. This project aims to demonstrate the development and deployment of a web application using some of my favorite tools, languages and frameworks including:
- Python
- Django
- JavaScript
- Vue.js/Quasar Framework
- GitLab
- AWS
- and last but not least, AWS Cloud Development Kit (CDK)
This README will start by describing some features of the application I'm building and how the different technologies are used together. I also share my experience in adopting CDK for managing cloud infrastructure on AWS. Finally, I discuss my solution to a specific question I have been trying to answer: what's the best way to scale Celery workers to zero to reduce Total Cost of Ownership?
Development Philosophies and Best Practices
Here are some of the best practices that this project aims to use:
- Open-source, MIT-Licensed
- 12 Factor App
- Infrastructure as Code
- Containerization with Docker
- Testing
- GitOps
- Serverless* 1
- Project documentation
- Cost containment and tracking
- KISS & DRY
- Initial AWS console interaction is strictly limited to what can only be done through the AWS console, otherwise AWS CDK and AWS CLI (preferably in CI/CD pipelines) are the primary means of interacting with AWS resources and the AWS Console is treated as a "read-only" convenience.
Topics
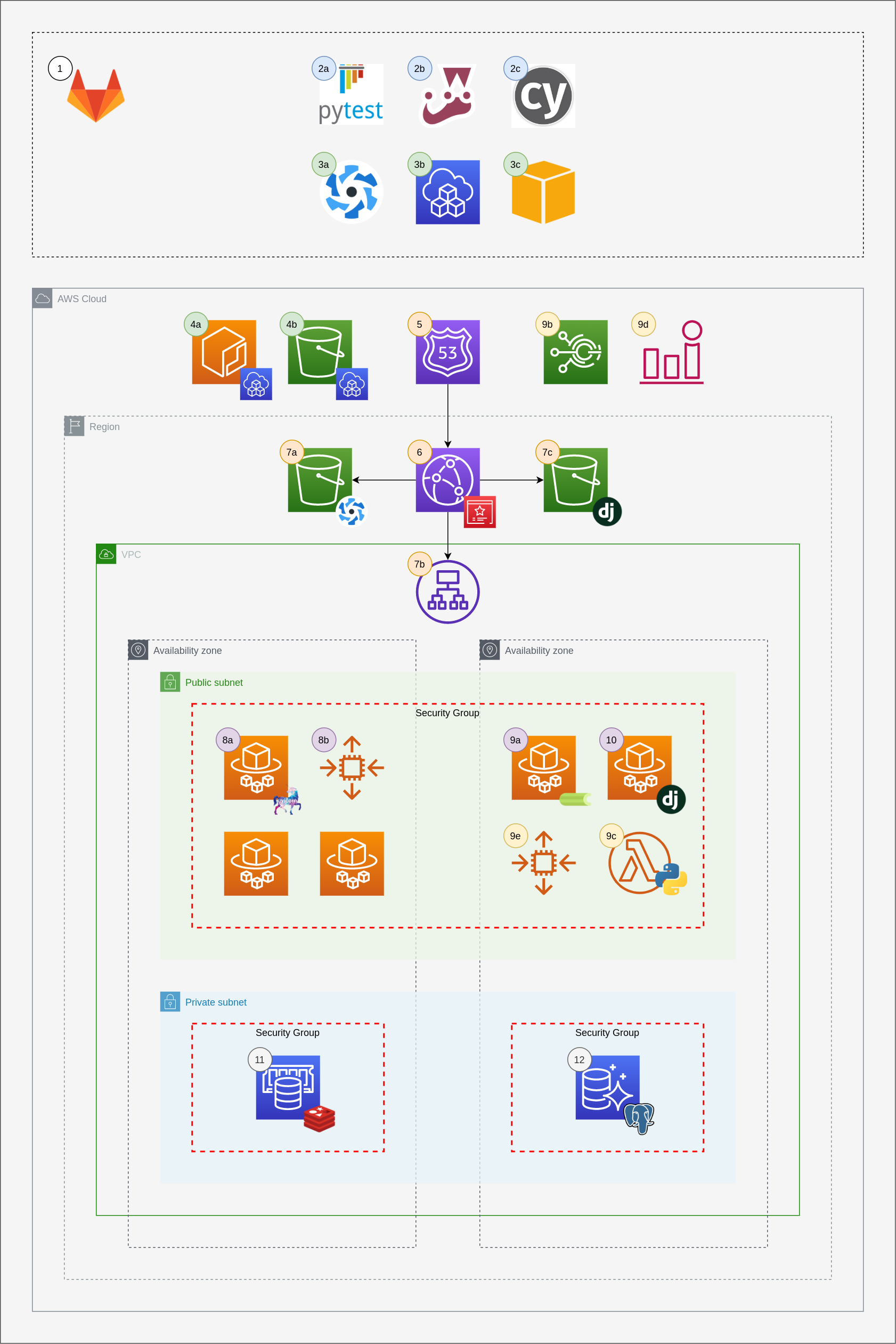
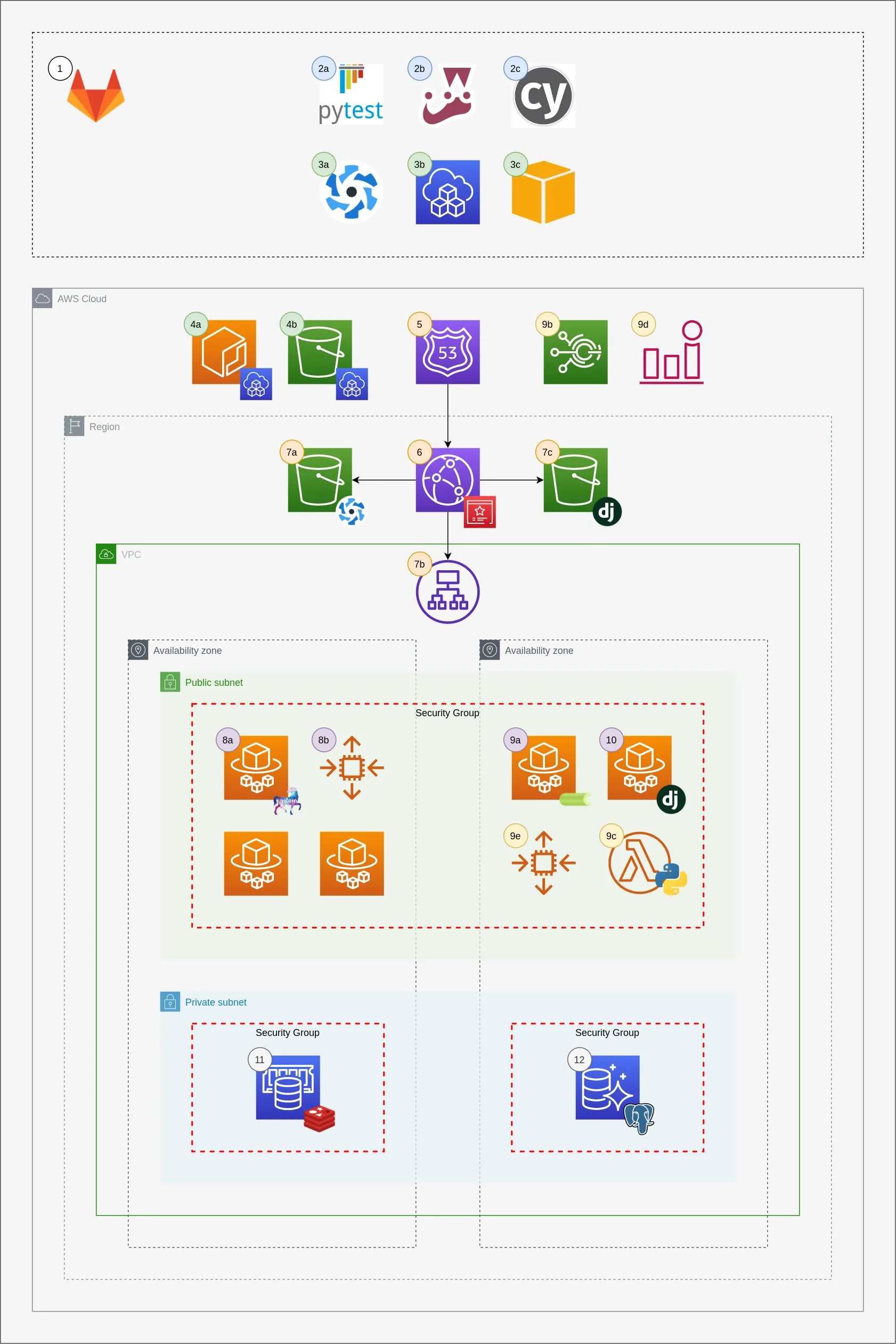
Legend
This diagram was created with draw.io. Here's the link to the a read-only version of the diagram on draw.io: https://drive.google.com/file/d/1gU61zjoW80fCusUcswU1zhEE5VFB1Z5U/view?usp=sharing
1 - GitLab is used to host the source code, test the source code and deploy the application to AWS.
2 - Unit testing (see .gitlab-ci.yml)
2a - Pytest
2b - Jest
2c - Cypress
3 - Deployment phase (see /gitlab-ci/aws/cdk.yml)
3a - Quasar PWA assets are built if there are changes in the quasar directory
3b - AWS Cloud Development Kit (CDK) defines all infrastructure in AWS (4a - 12)
3c - AWS CLI is used to run Fargate tasks through manual GitLab CI jobs
4 - CDK Assets (ECR and S3 buckets that CDK uses internally to manage build assets and artifacts)
4a - Elastic Container Repository is used to manage the Django docker image used in various parts of the application
4b - S3 bucket used to store files associated with CDK and CloudFormation
5 - Route53 is used to route traffic to the CloudFront distribution
6 - CloudFront distribution that serves as the "front desk" of the application. It routes requests to to the correct CloudFront Origin
7 - CloudFront Origin Configurations
7a - S3 bucket for Quasar PWA assets
7b - Application Load Balancer for Django application (/api/, /admin/, /flower/, /ws/, /graphql/)
7c - S3 bucket for Django assets (static files, public media and private media)
8 - Web server and websocket servers
8a - Fargate service running uvicorn process (REST, GraphQL, Django Channels)
8b - Autoscaling Group for Fargate Service that serves Django API
9 - Celery and celery worker autoscaling
9a - Fargate service that is autoscaled between 0 and N Fargate tasks for a given celery queue
9b - Scheduled Event that triggers a Lambda to make a request to Django backend which collects celery queue metrics and published metrics to CloudWatch using boto3
9c - Lambda event the makes a request to /api/celery-metrics/
9d - CloudWatch alarm that is used to scale the Fargate service for a celery queue
9e - Autoscaling group for celery Fargate service
10 - Fargate tasks that run Django management commands such as migrate and collectstatic. These are triggered from manual GitLab CI jobs using the AWS CLI (3c)
11 - ElastiCache for Redis, used for Caching, Celery Broker, Channels Layer, etc.
12 - Aurora Postgres Serverless
Here's a list of some of the major topics covered:
Local development
- Setting up a local development environment using docker with one easy command:
docker-compose up - Hot-reloading for all parts of the application in local development
- Structuring a Django application (apps, settings modules, environment variables)
- Automatic code formatting with black and prettier
- Monitoring services (flower, pgadmin4, redis-commander)
- VSCode settings and extensions
GitLab CI
- GitLab CI for running unit and integration tests
- GitLab CI configuration for deployment to multiple environments (dev, prod) using AWS CDK
- GitLab CI scheduled jobs for updating all project dependencies through automated merge requests with Renovate
- GitLab CI manual jobs for running admin and management commands (database migrations, collectstatic, etc.)
- How to deploy to multiple environments (master -> staging, tags -> prod pattern as well as optional ephemeral environments per commit) using the new GitLab CI
rulessyntax - Recording Cypress test videos with GitLab CI artifacts for manual review
AWS
- Initial account setup
- Generating keys used in GitLab CI for deployment
- Opting in to new ARN format for ECS services and tasks (used for resource tagging) and container insights
- AWS Cloud Development Kit (CDK) for Infrastructure as Code to manage all AWS resources with CloudFormation Stacks - Nested stacks for grouping related resources under parent tasks (one parent task represent on environment for the application, such as production)
AWS Resources
- Automated provisioning of Amazon Certificate Manager certificates for TLS (HTTPS)
- Multi-AZ VPC with security groups and NACLs (no NAT Gateways/NAT instances used* 2)
- S3 buckets for static site hosting and Django static and media assets
- CloudFront for serving Vue.js SPA (PWA) static assets, Django static/media files and proxy to Application Load Balancer which forwards to ECS
- Fargate for multiple Django processes: gunicorn for backend API, daphne for Django Channels, celery for asynchronous tasks and celery beat for scheduled tasks
- Autoscaling (between 0 and N Fargate tasks) for infrequent, compute/memory intensive and long-running celery tasks with custom CloudWatch metrics
- Hosted Redis with ElastiCache for celery broker, application caching, django-constance, etc.
- Aurora Postgres and Aurora Postgres Serverless for cost savings in staging environments
- CDK Assets for automating S3 asset deployment and automated container building during deployment with AWS CDK
- Thorough resource tagging by both application and environment (dev, prod, etc.) for comprehensive cost tracking
- Optional bastion host for SSH access to bring up a Django shell in a container running on a container instance (this requires an EC2 instance)
Django Application
- Django REST Framework
- JWT-based authentication with django-rest-framework-simplejwt
- Custom user model with email as username
- Social authentication with
python-social-auth(Google, Facebook, GitHub) - Pytest for unit testing
- Settings broken into separate modules (development, ci, production)
- Django apps organized in
appsdirectory - S3 for static assets, public media and private media files in production, local file system for assets in local development
- Multiple Celery queues for asynchronous tasks
- Django Channels for websocket support with daphne
- Graphene for GraphQL
Vue.js application
- Quasar Framework for creating a Vue.js app with multiple build targets (SPA, PWA, Electron, SSR and Cordova)
- Internationalization
- Dark/Light mode
- Vuex for state management
- vue-router
- axios
- Vue Apollo
AWS ∩ Django ∩ Vue.js
CloudFront is used as a CDN and proxy in order to serve the frontend Vue.js PWA* 3, static and media assets, Django API and other monitoring services all on the same URL with environments namespaced by subdomain (or a combination of domain and subdomains by production and non-production environments, respectively). The PWA uses Workbox to route certain URL paths to network only (not served by the local cache).
Here are some examples:
Staging environment URLs
https://dev.mysite.com/api/*- Django REST Frameworkhttps://dev.mysite.com/admin/*- Django Adminhttps://dev.mysite.com/graphql/- Graphene/GraphQLhttps://dev.mysite.com/flower/*- Flower (Celery monitoring utility)https://dev.mysite.com/media/private/private-file.csv- private media fileshttps://dev.mysite.com/*- Vue.js PWA (all other routes loadindex.html)
Production environment URLs
https://mysite.com/api/*- Django REST Frameworkhttps://mysite.com/admin/*- Django Adminhttps://mysite.com/graphql/- Graphene/GraphQLhttps://mysite.com/flower/*- Flower (Celery monitoring utility)https://mysite.com/media/private/private-file.csv- private media fileshttps://mysite.com- Vue.js PWA (all other routes loadindex.html)
Alternatively, the production domain name could be configured to use a dedicated subdomain such as https://app.mysite.com.
Sample application logic
While this is mostly a Proof-of-Concept project that focuses on architecture, I have included some light-weight examples of what you can do with this application. These examples are all WIP.
Social Authentication
- Uses
python-social-authto allow users to Sign Up/Login with Google, Facebook and GitHub accounts - Makes use of the custom user model
Credit Card Statement App
This is a simple application for users to upload credit card statements in CSV format.
- Credit card transactions in CSV files are created using bulk inserts via the Django ORM in a celery task
- CSV files are saved in private S3 storage
- Basic visualization of spend over time
- Download consolidated CSV file
Hacker News Clone
- An implementation of the application from this tutorial: https://www.howtographql.com/graphql-python/0-introduction/
- Uses Vue Apollo GraphQL client
Testing
- Unit testing with pytest and Jest
- Test coverage reports
- Integration testing with Cypress
- Capture integration test run recordings as GitLab CI job artifacts
- Testing GitLab CI jobs locally with
gitlab-runner - Tests for CDK?* 4
Caveats, Questions, Confusion and Footnotes
- In the context of this project, it is serverless in the sense that AWS Fargate is serverless: there are no EC2 instances to manage. It is not serverless in the way that Zappa can deploy a Django application as an AWS Lambda function with one invocation per request. There are "always on" processes that listen for incoming requests. I'm interested in trying Zappa, but I'm confused about how CDK, zappa-cli, SAM and Serverless Framework would all play together. Aurora Postgres Serverless is another nice "serverless" aspect of this project and contributes significantly to cost savings.
- This project currently uses no NAT Gateways. The Fargate services and tasks running Django processes (gunicorn, celery, daphne as well as migration, collectstatic and other management commands) are launched in public subnets and the databases (RDS and ElastiCache) are placed in private subnets. This is primarily done to avoid the cost of running a NAT Gateway.
- I think it would fairly easy to switch to using a NAT Gatway to add an additional layer of security that is recommended in this article: https://aws.amazon.com/blogs/compute/task-networking-in-aws-fargate/.
- I asked a question about this on the Stack Exchange Information Security forum: https://security.stackexchange.com/questions/232055/security-implications-of-using-public-subnets-in-aws-vpc-for-hosting-web-and-job I'm curious to know if this is a reasonable tradeoff to make, as well as how secure the proposed solution is (using security groups and network ACLs).
- I'm not focusing on SEO in this project. I'm using
index.htmlas the error document for the S3 website that CloudFront uses as the default behavior. This means that nested routes for the PWA have 404 response codes. I have heard about using lambda@edge to rewrite the the response code, I'm also curious about using this project in SSR mode (and also "serverless-side rendering"), but for now that is outside of the scope of what I want to do with this project. - CDK is an awesome tool! Here is a great introduction by Nathan Peck, Senior Developer Advocate at Amazon Web Services: https://www.youtube.com/watch?v=184S7ki6fJA.
My experience with AWS CDK
Having worked with CloudFormation for almost a year, I was not looking forward to learning a another Infrastructure as Code (IaC) tool. I struggled with CloudFormation and the whole concept of using an extended version of YAML to define infrastructure for multiple environments. I have limited experience with Terraform, but learning another DSL seemed like a lateral move that didn't seem worth it. I'm glad I did spend time learning and using CloudFormation, because CDK is an abstraction layer over CloudFormation. Here are some of my thoughts on adopting CDK.
Start here: https://cdkworkshop.com
This is a great resource that was my first exposure to CDK. It focuses on using Lambda, DynamoDB and API Gateway, three technologies that I haven't used in production environments. In my mind this stack is the antithesis of the stack paradigm I am most experienced with: EC2, RDS and ELB. Regardless, I went ahead with it and was pretty much instantly hooked on CDK.
The stack is defined by a small number of inputs used for namespacing
awscdk/app.py is the entrypoint for cdk commands. Here's what it contains:
Here are the main parameters for ApplicationStack, which represents all of the resources for a specific environment environment. Each value is composed of environment variables set in GitLab CI when cdk deploy is called:
environment_name- Possible examples could bedev,qa,some-feature-branch,prod, etc.base_domain_name- The domain name of the Hosted Zone that needs to be setup manually in Route53full_domain_name-f"{environment_name}.{base_domain_name}"or optionally justbase_domain_namebase_app_name- Based on thebase_domain_name, but.is replaced with-in order to be used for naming certain AWS resources, used for resources tagging so we can easily look at the costs of all environments for our application with one tag.full_app_name- Base onfull_domain_name,.replaced with-as well.aws_region
Expand to the following to view awscdk/app.py:
#!/usr/bin/env python3
import os
from aws_cdk import core
from awscdk.cdk_app_root import ApplicationStack
# naming conventions, also used for ACM certs, DNS Records, resource naming
# Dynamically generated resource names created in CDK are used in GitLab CI
# such as cluster name, task definitions, etc.
environment_name = f"{os.environ.get('ENVIRONMENT', 'dev')}"
base_domain_name = os.environ.get("DOMAIN_NAME", "mysite.com")
# if the the production environent subdomain should nott be included in the URL
# redefine `full_domain_name` to `base_domain_name` for that environment
full_domain_name = f"{environment_name}.{base_domain_name}" # dev.mysite.com
# if environment_name == "prod":
# full_domain_name = base_domain_name
base_app_name = os.environ.get("APP_NAME", "mysite-com")
full_app_name = f"{environment_name}-{base_app_name}" # dev-mysite-com
aws_region = os.environ.get("AWS_DEFAULT_REGION", "us-east-1")
app = core.App()
stack = ApplicationStack(
app,
f"{full_app_name}-stack",
environment_name=environment_name,
base_domain_name=base_domain_name,
full_domain_name=full_domain_name,
base_app_name=base_app_name,
full_app_name=full_app_name,
env={"region": aws_region},
)
# in order to be able to tag ECS resources, you need to go to
# the ECS Console > Account Settings > Amazon ECS ARN and resource ID settings
# and enable at least Service and Task. Optionally enable
# CloudWatch Container Insights
stack.node.apply_aspect(core.Tag("StackName", full_app_name))
stack.node.apply_aspect(core.Tag("StackName", base_app_name))
app.synth()
Using cdk synth in development
When I first started using CDK, I defined a root stack containing multiple CDK constructs that each included groups of related CDK resources. For example, I had an RDSConstruct that contained a Secret, a StringParameter, a CfnSecurityGroup, a CfnDBSubnetGroup and a CfnDBCluster. Whenever I added a new section of CDK code, I would run cdk synth > stack.yml to generate a "snapshot" of my infrastructure in one file. stack.yml was committed in my repo, and I could easily see how changes in CDK code changed the resulting CloudFormation YAML by repeating this cdk synth command.
NestedStacks
stack.yml grew larger and larger as I added more resources in my main "master stack" or "skeleton stack", and I realized that I was going to reach the hard limit of 200 resources per CloudFormation stack. Refactoring to use NestedStacks was pretty straightforward, all I had to do was replace core.Construct with cloudformation.NestedStack. With nested stacks, running cdk synth > stack.yml references the AWS::CloudFormation::Stacks that are created, with TemplateURL and parameters from other stacks. It is more useful to look into contents of cdk.out when working with NestedStacks. The following command (executed from the root of the project) update the contents of the awscdk/cdk.out directory with templates for each of the NestedStacks:
cdk synth --app awscdk/app.py --output awscdk/cdk.out
The result is JSON, not YAML, and cdk.out is .gitignored, but it can still be helpful in verifying that your CDK code is generating the correct CloudFormation templates. (cdk diff may be the best option for seeing how CDK code changes will change your infrastructure).
cdk deploy and CDK in GitLab CI pipelines
I like how cdk deploy tails the output of CloudFormation events until the stack update finishes or fails. I previously had been using the AWS CLI to call aws cloudformation update-stack. This command kicks off a stack update and the GitLab pipeline will succeed regardless of the success of failure of the update-stack command.
With CDK, the CI pipeline that calls
cdk deployfails ifcdk deployresults in a stack rollback.
I couldn't find any examples of how to run cdk deploy in a GitLab CI pipeline (using the Python version of CDK, or any version of CDK). It would be nice if there was an official image maintained for the different languages that are ready to run CDK deploy. Here's how I got cdk deploy working correctly in my CI/CD pipline:
cdk deploy:
image: docker:19.03.1
services:
- docker:19.03.5-dind
stage: deploy
only:
- master
variables:
ENVIRONMENT: dev
DOCKER_TLS_CERTDIR: ''
before_script:
- apk add nodejs-current npm
- npm i -g aws-cdk
- apk add --no-cache python3
- pip3 install -e awscdk
script:
- cdk bootstrap --app awscdk/app.py aws://$AWS_ACCOUNT_ID/$AWS_DEFAULT_REGION
- cdk deploy --app awscdk/app.py --require-approval never
I have all of my CDK code in a top level directory called awscdk, my Django code is in the top level backend directory and my frontend code is in the top level quasar directory. This directory structure is important, I'll come back to it shortly. Here are some things to note about this GitLab CI job definition:
- It uses the base
dockerimage withdocker:dindas a dependent service. This is necessary only if you hare using CDK constructs that build docker images and make use ofcdk bootstrap, such as theaws_ecs.AssetImagethat I use to defineself.imagein theApplicationStackclass that defines that main stack of my application. - It requires node, npm python and pip, so these all need to be installed via
apk, the package manager for Alpine Linux. These are done in thebefore_script, the setup for the main "script" wherecdk deployis called. - The main
scriptsection callscdk bootstrap. You only need to callcdk bootstraponce to initialize resources that CDK will use, so placing it here in my CI script is more of a reminder that we are using CDK assets (S3 buckets and ECR images); calling it again once it has been called initially on your AWS account does nothing, and you will see a message that communicates this:
$ cdk bootstrap --app awscdk/app.py aws://$AWS_ACCOUNT_ID/$AWS_DEFAULT_REGION
⏳ Bootstrapping environment aws://XXXXXXXXXXXX/us-east-1...
✅ Environment aws://XXXXXXXXXXXX/us-east-1 bootstrapped (no changes).
cdk bootstap
cdk bootstrap is one of my favorite features of CDK. As I mentioned earlier, it is used with S3 and ECR.
S3 Assets
With S3, it allows you to populate the contents of an S3 bucket. Here's an example from ApplicationStack:
if os.path.isdir("./quasar/dist/pwa"):
s3_deployment.BucketDeployment(
self,
"BucketDeployment",
destination_bucket=self.static_site_bucket,
sources=[s3_deployment.Source.asset("./quasar/dist/pwa")],
distribution=self.cloudfront.distribution,
)
If the directory ./quasar/dist/pwa exists, CDK will upload the contents of that directory to the static_site_bucket and then invalidate the cache for self.cloudfront.distribution, all in one shot. ./quasar/dist/pwa is the directory where assets from my frontend PWA are placed when compiled. GitLab CI passes these files between the jobs using artifacts:
artifacts:
paths:
- quasar/dist/pwa
The job to build PWA assets can be set to only run when there are changes in the quasar directory, so the .quasar/dist/pwa directory will only exist if the job is executed. This helps speed up our CI/CD pipeline.
ECR Assets
I use cdk boostrap and CDK assets in a similar way for building and pushing my application container. In ApplicationStack, I define the following:
self.image = ecs.AssetImage(
"./backend", file="scripts/prod/Dockerfile", target="production",
)
This image is then referenced by multiple NestedStacks that define Fargate services and tasks (gunicorn, daphne, celery workers, etc.) This keeps our CDK code DRY.. Don't Repeat Yourself! Similarly, we aren't rebuilding, pushing and pulling the backend container when there are no changes to the code in backend directory.
I'm not setting up an ECR image repository for my application, but I believe there is a way to do this. One question that I have about using ecs.AssetImage is about image lifecycle management. I know that you can implement rules about how many images you want to keep in an ECR image repository, but I'm not sure how this works with CDK Image Assets.
Quick tour of ApplicationStack
Here's a very quick look at the structure of my CDK code, focusing on the ApplicationStack, the "master stack" or "skeleton stack" that contains.
hosted_zone
We get the hosted zone using the DOMAIN_NAME and HOSTED_ZONE_ID. This is not a nested stack.
site_certificate
The ACM Certificate that will be used for the given environment. This references the full_domain_name (environment + application).
vpc_stack
A NestedStack for defining VPC resources. This construct generates lots of CloudFormation resources. I currently have nat_gateways set to zero, and I'm PUBLIC and PRIVATE subnets spread over 2 AZs. As I mentioned earlier, this is primarily for cost considerations and it is a best practice to use the tiered security model and run our Fargate tasks in private subnets instead of public subnets. I think I need to add NACL resources in this NestedStack.
alb_stack
This defines the load balancer, configures that will send traffic to our Fargate services (such as our Django API). I was a little bit unclear about needing a listener and https_listener. I might be able to get away with removing the listener and only using https_listener.
static_site_stack
This stack defines the S3 bucket and policies that will be used for hosting our static site (Quasar PWA).
backend_assets
This stack defines the bucket and policies for managing the bucket that holds static and media assets for Django.
cloudfront
This defines the CloudFront distribution that ties together several different parts of the application. It is the "front desk" of the application, and acts as a CDN and proxy. There is a separate CloudFront distribution for each environment (dev, staging, production). This stack also defines the Route53 ARecord that will be used to send traffic to a specific subdomain to the correct CloudFront distribution.
There are three origin_configs for each distribution:
CustomOriginConfigfor the ALBCustomOriginConfigfor the S3 bucket websiteS3OriginConfigfor the Django static assets
Note that these origin_configs each have different behaviors, and that list comprehension is used to keep this code DRY.
BucketDeployment
This will deploy our static site assets to the S3 bucket defined in static_site_stack if the static site assets are present at the time of deployment. If they are not present, this means that there were no changes made to the frontend site.
ecs
Defines the ECS Cluster.
rds
There is no L2 construct for DBCluster, so I used CfnDBCluster in order to use the Aurora Postgres engine and the serverless engine_mode.
elasticache
I also had to use L1 constructs for ElastiCache, but this one is pretty straightforward.
For both RDS and ElastiCache I used the vpc_default_security_group as the source_security_group. It might be a better idea to define another security group altogether, but this approach works.
AssetImage
The docker image that references Django application code in the backend directory. This image is referenced in Fargate services and tasks.
variables
This section defines and organizes all of the environment variables and secrets for my application.
backend_service
It might be a better idea to replace this with NetworkLoadBalancedFargateService, but instead I implemented this with lower-level constructs just to be clear about what I'm doing. To add a load balanced service, here is what I did:
- Define the Fargate task
- Add the container to this task with other information (secrets, logging,
command, etc.) - Give the task role permissions it needs such as access to Secrets, S3 permissions. (It might be a good idea to refactor this into a function that can be called on
task_role, but for now I am explicitly granting all permissions) - Create and add a port mapping
- Define an ECS Fargate Service that reference the previously defined Fargate task, configure security group
- Add the service as a target to the
https_listenerdefined previously inalb_stack. - Optionally configure autoscaling for the Fargate service
flower_service
Flower is a monitoring utility for Celery. I had trouble getting this to work correctly, but I managed to make it work by adding a simple nginx container that passes traffic to the flower container running in the same task. https://flower.readthedocs.io/en/latest/reverse-proxy.html
celery_default_service
This stack defines the default celery queue. This is discussed later in more detail, but the basic idea is to:
- Define the Fargate task
- Add the container
- Define the Fargate service
- Grant permissions
- Configure autoscaling
celery_autoscaling
This stack defines the Lambda function and schedule on which this Lambda is called. This stack is discussed in more detail later on.
backend_tasks
These are administrative tasks that are executed by running manual GitLab CI jobs such as migrate, collectstatic and createsuperuser.
Why X? Why not Y?
This section will compare some of the technology choices I have made in this project to other popular alternatives.
Why ECS? Why not Kubernetes?
I like Kubernetes. I have never used it to support production workloads, but I have explored it in a limited capacity. I have set up this project in Kubernetes locally using minikube, there is an article on this in the documentation. There are also lots of options for how you do Kubernetes, here are a few off of the top of my head:
- KOPS
- EKS
- k3s
- cdk8s
- Kubernetes on Fargate
- "Kuberetes the Hard Way"
With any of these options you are probably going to want to use Helm to do deployments, which adds another layer of abstraction that also has several different ways to be managed. On the other hand, ECS is "just ECS"; there are not a lot of other considerations to make when running workloads in ECS. You have to choose between the two available launch types: EC2 and Fargate. Comparisons of ECS and Kubernetes often mention that ECS integrates nicely with other AWS Services, something I have generally found to be true in setting up this project. Granting permissions to S3 buckets or CloudWatch, or using security groups to give ECS tasks access to certain resources in your VPC are some examples of what this "tight integration" has meant for me so far.
Why Django? Why not Flask?
I like Django for lots of reasons. I get why people say it can be "overkill", and there are definitely lots of parts of Django that don't use. I use Django primarily for the ORM, migrations system and the Django Admin. I also use the Django REST Framework, which gives me another big productivity boost when building APIs. I dislike Django Forms and Django templates, but that wasn't always the case. Before that, I disliked JavaScript frameworks and single page applications. That changes when I started working with Vue.js and Quasar.
Why Quasar Framework? Why not Nuxt.js or vanilla Vue.js? Why not React?
Quasar Framework is a few different things, and just like Vue.js itself, Quasar can be incrementally adopted. Primarily, Quasar is a CLI for creating Vue.js projects. It offers some opinions on how to organize files and folders. It handles SPA, PWA, SSR, Electron, Cordova and other build targets. It implements the MaterialUI spec and it has an awesome and active community (but Django, GitLab and AWS do, too!)
Quasar does things a little bit differently than vanilla Vue.js. There is no main.js file in a typical Quasar application. Instead, bootfiles are used to initialize things that would typically go into main.js. I believe this helps Quasar manage multiple build targets easily.
I really haven't worked a lot with Nuxt.js, but I would probably be drawn to it if Quasar was not an option. I like how it helps structure your application. In the same way that Django is "batteries included", Quasar is also very much "batteries included".
I think React is neat, but I have similar feelings between React and Vue that I have between Django and Flask. One requires you make more decisions and therefore has a heavy mental load. The biggest example of this is the tight integration of an official router and state management system for Vue (vue-router and vuex).
Why Celery? Why not Heuy or django-rq?
I think celery is probably the most heavy-weight option for managing asynchronous tasks in Django. It is very flexible and "pluggable" which makes it slightly more challenging to get setup. I would be interested in trying another option, but celery is a mature option that has a large community of users.
Scaling Celery workers to zero
Django is used in a few different ways in this application:
- a backend API supported by Django REST Framework, Postgres and static files stored in AWS S3, served over CloudFront
- a websocket server supported by Django Channels
- an administrative backend that is automatically generated by Django (Django Admin)
- asynchronous task workers supported by Celery
The API server, websocket server and Django admin can technically be served by the same daphne process. In terms of our application and AWS architecture, this means that requests for URLs starting with /api/, /ws/ and /admin/ can all be sent to the same Fargate service target group.
Alternatively, we could split these up into two or three different process that can then be scaled individually.
Celery processes should be run as separate processes. If you have multiple queues, you may have workers that are dedicated to processing tasks from certain queues which run as individual Fargate tasks, each with certain CPU and memory allocations and other celery settings, such as max_concurrency.
To manage the total cost of ownership, I wanted to know how to scale Celery workers between 0 and N. A celery worker is typically an "always on" process that watches for new messages that arrive in the queue and then processes message specified (the messages delivered to the queue contain information on which function to call, and what arguments that function should be called with.
Let's image that we have a celery task to process with the following properties:
- It takes a long time to process (between 15 minutes and 1 or 2 hours)
- It has lots of dependencies (such as pandas, scikit-learn, etc.)
- It requires a high amount of CPU and memory
- It cannot easily be broken down into smaller sub-tasks
- The time and frequency at which this task will be called is not predictable
- A 2 - 3 minute delay between calling the task and starting work on the task is acceptable
- This task might not be very easy to process with AWS Lambda without lots of additional logic, if not impossible.
To manage our project's TCO, we want scale down the number of Fargate tasks that process the queue this task is sent to. If there are no messages queued for this worker and no messages currently being processed by any of the workers for the queue, the number of Fargate tasks (celery workers) should be scaled down.
I haven't done much with autoscaling on AWS before, but I found that CDK provides some very nice abstractions that make scaling with Fargate task very straightforward.
ECS allows you to scale based on some built in metrics, such as CPU Utilization. Scaling between 0 and N workers based on CPU utilization metrics wouldn't work because there would be no CPU utilization after the Fargate tasks are scaled to zero; messages in the queue would remain unprocessed and no new workers would be brought online.
Using the number of tasks in the queue would be a better option. I tried a few different options to get this to work.
First, I tried using one of the high-level constructs (L3 construct) from ecs_patterns called QueueProcessingFargateService, but this would require that I replace Redis with SQS as the broker to be used with Celery. Some people prefer to use SQS, but I like having the ability to inspect and control, which requires a broker like Redis and is not possible with SQS.
My current solution involves:
- Creating a CloudWatch metric (the namespace is
FULL_APP_NAMEand the metric name is the name of the queue,default) - Calling
auto_scale_task_counton the Fargate service to create a an "autoscaling Fargate task" - Calling
scale_on_metricon the "autoscaling Fargate task" with the CloudWatch metric created in1 - Setting up a
celery-metricsAPI endpoint on my Django API server that, whenPOSTed to, collects celery metrics per queue and publishes these metrics to CloudWatch. - Scheduling a Lambda function to post to the
celery-metricsendpoint every 5 minutes.
Here's the code that takes care of steps 1, 2 and 3:
self.default_celery_queue_cw_metric = cw.Metric(
namespace=scope.full_app_name, metric_name="default"
)
self.celery_default_queue_asg = self.celery_default_worker_service.auto_scale_task_count(
min_capacity=0, max_capacity=2
)
self.celery_default_queue_asg.scale_on_metric(
"CeleryDefaultQueueAutoscaling",
metric=self.default_celery_queue_cw_metric,
scaling_steps=[
aas.ScalingInterval(change=-1, lower=0),
aas.ScalingInterval(change=1, lower=1),
],
adjustment_type=aas.AdjustmentType.CHANGE_IN_CAPACITY,
)
Step 4 inspects active and reserved tasks, filters the tasks by the routing_key (which is the same as the queue name) and the combines this with any queued tasks by calling llen(queue_name). Finally, the queue names and combined active, reserved and queued task totals are sent to CloudWatch via boto3. The code for this is in backend/apps/core/utils/celery_utils.py.
Here's the code for the Lambda function in step 5:
import json
import os
import urllib.request
FULL_DOMAIN_NAME = os.environ.get("FULL_DOMAIN_NAME")
CELERY_METRICS_PATH = "api/celery-metrics/"
CELERY_METRICS_URL = f"https://{FULL_DOMAIN_NAME}/{CELERY_METRICS_PATH}"
CELERY_METRICS_TOKEN = os.environ.get("CELERY_METRICS_TOKEN")
def lambda_handler(event, context):
data = {"celery_metrics_token": CELERY_METRICS_TOKEN}
params = json.dumps(data).encode('utf8')
req = urllib.request.Request(
CELERY_METRICS_URL,
data=params,
headers={'content-type': 'application/json'},
)
response = urllib.request.urlopen(req)
return response.read()
Finally, here is the code for defining the lambda function and scheduled invocation of the lambda function:
class CeleryAutoscalingStack(cloudformation.NestedStack):
def __init__(self, scope: core.Construct, id: str, **kwargs) -> None:
super().__init__(
scope, id, **kwargs,
)
self.lambda_function = aws_lambda.Function(
self,
"CeleryMetricsLambdaFunction",
code=aws_lambda.Code.asset("awslambda"),
handler="publish_celery_metrics.lambda_handler",
runtime=aws_lambda.Runtime.PYTHON_3_7,
environment=scope.variables.regular_variables,
)
self.celery_default_cw_metric_schedule = events.Rule(
self,
"CeleryDefaultCWMetricSchedule",
schedule=events.Schedule.rate(core.Duration.minutes(5)),
targets=[
events_targets.LambdaFunction(handler=self.lambda_function)
],
)
# TODO: refactor this to loop through CloudWatch metrics multiple celery queues
scope.celery_default_service.default_celery_queue_cw_metric.grant_put_metric_data(
scope.backend_service.backend_task.task_role
)
Miscellaneous Grievances
- Fargate tasks cannot access Secrets that use JSON template
- You cannot select
FARGATE_SPOTon a CDK-created ECS cluster. This option seems to only be available from the ECS Wizard in the AWS Console - It's not super clear how to package dependencies in Lambda with CDK. Here's an interesting approach that I would like to try: https://github.com/aws-samples/aws-cdk-examples/issues/130#issuecomment-554097487. The Lambda functions I'm using don't require anything outside of the standard library, but if they did it would require some additional work to make sure dependencies can be added as Lambda Layers.
TODO
- Create an IAM role template that can be used to create an IAM role that has access to setup infrastructure through CDK. Currently I'm using an admin account which is not a best practice.
- Move this Wiki Article to the project documentation site and main README
- Expand on each topic, replace existing documentation
- Add a summary of each
NestedStackfrom CDK code