Deploying serverless Django applications to AWS with CDK on a tiny budget using Lambda, API Gateway, awsgi and the Lambda proxy pattern
Last updated August 1, 2020
tl;dr
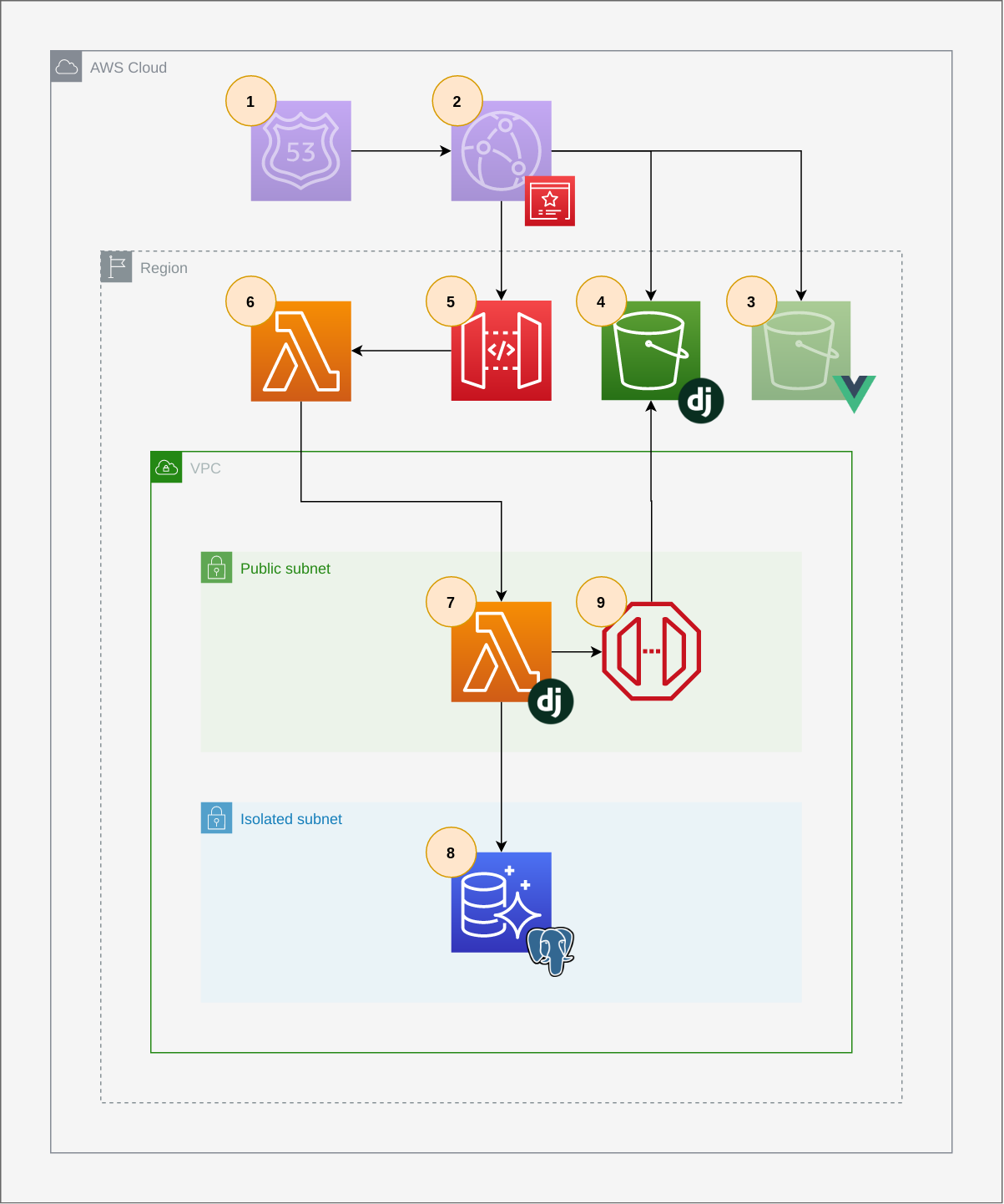
One way to deploy Django apps to AWS on a budget is to use the Lambda proxy pattern. The main idea is this: web requests are made to API Gateway that calls a Lambda outside of our VPC (proxy Lambda), which then invokes a second lambda (Django Lambda) inside of our VPC so that it can access VPC resources, namely RDS. The handler for the Django Lambda translates the API Gateway event into a WSGI-compatible request, processes the request and returns the response to the user back through the proxy Lambda. The big caveat is that you can't easily access the internet in Django's request/response cycle without network address translation (NAT) services which add additional costs. One other caveat is that there is high latency associated with the initial request. There are three cold starts to wait for: the cold start for the proxy Lambda, the cold start for the Django Lambda and the cold start for the Aurora Postgres Serverless database. Here's an architecture diagram:
Route53 and CloudFront (1 and 2), discuessed later on, are optional. Starting with 5, API Gateway requests are passed to a proxy lambda (6) which calls a Lambda in a VPC that contains our Django code and special Django handler (7). This function can access RDS (8) and S3 (4) via a VPC Gateway Endpoint (9), but it cannot access the internet.
Why?
There are a few different reasons for why I put this project together. Before I get into these reasons, here is a little bit of background on how I typically deploy web apps and the motivations for this project.
Django is my web framework of choice, and I'm most comfortable working with Django in docker containers. I previously wrote an article about deploying Django applications with AWS Fargate. This approach technically is "serverless", but it requires the use of "always on" services: an Application Load Balancer, NAT Gateways and long-running Fargate tasks to run gunicorn processes for our Django application. Even if you choose to run workloads in public subnets and don't use NAT Gateways or NAT instances, the costs are prohbitively high for many types of Django projects: personal projects, proof-of-concept projects, internal projects, toy projects, etc.
The other serverless compute platform on AWS is Lambda. There is a popular framework for deploying serverless Django applications on Lambda called Zappa. I have been meaning to try out Zappa for a while now, and I still haven't used it, but it provided a good reference for how to do "serverless Django". I'll come back to Zappa in more detail later, but the main reason I didn't want to use it for my serverless Django project is because I already have a great deployment and Infrastructure as Code tool: CDK.
CDK, or Cloud Development Kit, is a tool that allows you define and deploy AWS infrastructure using any popular programming language, Python in my case. It uses CloudFormation in the background, and it has great support for lots of AWS services. If you are looking for an introuction to CDK, check out https://cdkworkshop.com/.
Zappa makes it really easy to deploy serveless Django applications with Django, but it requires that you setup NAT and other VPC resources before using it with RDS. Since CDK is really good at setting up these kinds of resources, as well as the resources that Zappa creates (including Lambda functions and API Gateway), I wanted to know how far I could get in setting up a servless Django application only using CDK. I also didn't want everything abstracted away by a high level framework; I'm interested in a lower level view to get more familiar with how serverless technologies work. It's important to note that the biggest motivation of all is to learn try something out of my comfort zone, make mistakes and get feedback.
Django + Lambda = djambda
The name for this project came pretty easily. I created a repo on GitLab called djambda and then discovered a similar project by the same name on GitHub: netsome/djambda. The netsome/djambda project uses Terraform, and I encourage you to check it out and leave it a GitHub star. Before I came across this project, I hacked together a very basic djambda protoype using some code from Zappa's handler. A handler is the name for the function that is called in your Lambda function's code when the Lambda function is invoked. Here's some pseudo code that shows how Zappa's handler works:
from werkzeug.wrappers import Response
def handler(event, context):
with Response.from_app(wsgi_app, wsgi_request(event)) as response:
zappa_returndict = dict()
zappa_returndict['body'] = response.data
zappa_returndict['statusCode'] = response.status_code
return zappa_returndict
For reference, here is the link to the line in Zappa's source code that starts processing API Gateway requests on which the above psuedo code is loosly based.
The netsome/djambda project makes use of a package called awsgi that has active contributions from people at AWS. Similar to djambda, it is a mashup of words (acronyms): (AWS + wsgi = awsgi). It does most of the work that Zappa's handler does, so I replaced the adapted Zappa handler code with a very elagant handler (borrowed from netsome/djambda):
# djambda/src/djambda/awsgi.py
import io
import awsgi
from django.core import management
from .wsgi import application
def lambda_handler(event, context):
if "manage" in event:
output = io.StringIO()
management.call_command(*event["manage"].split(" "), stdout=output)
return {"output": output.getvalue()}
else:
return awsgi.response(application, event, context)
This handler can takes care of translating API Gateway requests to WSGI requests as well as management commands such as migrate, createsuperuser, collectstatic and other custom management commands. Let's talk about the management commands first as they relate to the two main AWS services that our Django application uses: RDS and S3. Then we will talk about API Gateway, the proxy Lambda and how the Lambda proxy pattern works.
RDS
To run the management commands for our application, we can use the AWS CLI to invoke the Lambda function with a payload that will trigger the if "manage" in event: code block from the above handler:
aws lambda invoke \
--function-name my-djambda-lambda \
--invocation-type RequestResponse \
--payload '{"manage": "migrate --no-input"}' \
resp.json
This will run the migrate command by connecting to RDS from our Django application with a special version of psycopg2 called aws-psycopg2 (check django/requirements.txt for this dependency). psycopg2 and psycopg2-binary both gave error messages when trying to access the database, but the aws-psycopg2 package had no issues.
RDS can sometimes be the most expensive part of a project on AWS. To reduce costs, we are using Aurora Postgres Serverless. This AWS service is ideal for small, infrequently-used projects that are in development. The database "goes to sleep" after a period of inactivity (5 minutes, I think). When new requests to the database are made, it can take up to 30 seconds for the database to wake up. For this reason, we need the timeout of the Django Lambda to be able to clear the wakeup period of the Aurora Postgres Serverless database.
Since our Lambda function is in public subnet of our VPC and our RDS Aurora database cluster is in an isolated VPC, we need to make sure that the Lambda function can talk to the RDS cluster. CDK makes this really easy. I'll highlight a few important permission related parts of awscdk/vpc.py, the code that defines the nested CloudFormation stack where we define our VPC and resources related to our application (including API Gateway, which is technically not located in our VPC).
First, we define a new security group for our Django Lambda:
self.lambda_security_group = ec2.SecurityGroup(
self, "LambdaSecurityGroup", vpc=self.vpc
)
Then, we reference this security group in the list of security group ingresses for our database cluster's security group:
self.db_security_group = ec2.CfnSecurityGroup(
self,
"DBSecurityGroup",
vpc_id=self.vpc.vpc_id,
group_description="DBSecurityGroup",
security_group_ingress=[
ec2.CfnSecurityGroup.IngressProperty(
ip_protocol="tcp",
to_port=5432,
from_port=5432,
source_security_group_id=self.lambda_security_group.security_group_id,
)
],
)
Now let's take a look at the code for the Django lambda itself:
self.djambda_lambda = _lambda.Function(
self,
"DjambdaLambda",
runtime=_lambda.Runtime.PYTHON_3_8,
code=_lambda.AssetCode('./django'),
function_name=f"{scope.full_app_name}-djambda-lambda",
handler="djambda.awsgi.lambda_handler",
layers=[self.djambda_layer],
timeout=core.Duration.seconds(60),
vpc=self.vpc,
vpc_subnets=ec2.SubnetSelection(subnets=self.vpc.isolated_subnets),
environment={**self.env_vars},
security_groups=[self.lambda_security_group],
)
# Use raw override because Lambda's can't be placed in
# public subnets using CDK: https://github.com/aws/aws-cdk/issues/8935
self.djambda_lambda.node.default_child.add_override(
"Properties.VpcConfig.SubnetIds",
[subnet.subnet_id for subnet in self.vpc.public_subnets],
)
lambda is a reserved word in Python, so we import lambda as _lambda from aws_cdk. Note that we have a reference to the awsgi.py handler function in the handler parameter of self.djambda_lambda. I initially put the lambda in isolated_subnets because CDK won't let you define a _lambda.Function with public_subnets for vpc_subnets. We can override this using add_override below the Lambda definition to place it in a public subnet instead.
I'm not sure if this is necessary, or if this is recommended. Things get a little bit confusing for me here so I would love some insight if anyone knows what would be best to do here. The VPC construct for CDK doesn't allow you to have private subnets when
nat_gateways=0. Would I be better off placing the lambda in the isolated subnet with the RDS cluster? Would I still be able to access S3 via the VPC Gateway Endpoint from an isolated subnet?
Putting aside my uncertainties about the correct way to configure our Lambdas functions in a VPC, let's continue! Here's the Lambda invocation for createsuperuser that we can run once we have successfully invoked the migrate command.
aws lambda invoke \
--function-name dev-mysite-com-djambda-lambda \
--invocation-type RequestResponse \
--payload '{"manage": "createsuperuser --no-input --username admin --email brian@email.com"}' \
resp.json
This assumes that there is an environment variable defined in our Lambda's environment variables that we passed in {**self.env_vars} for DJANGO_SUPERUSER_USERNAME. Here's what we have in env_vars:
self.env_vars = {
"POSTGRES_SERVICE_HOST": self.rds_cluster.get_att(
"Endpoint.Address"
).to_string(),
"POSTGRES_PASSWORD": os.environ.get("DB_PASSWORD", "db-password"),
"AWS_STORAGE_BUCKET_NAME": f"{scope.full_app_name}-assets",
"DEBUG": "",
"DJANGO_SUPERUSER_PASSWORD": os.environ.get(
"DJANGO_SUPERUSER_PASSWORD", "Mypassword1!"
),
"DJANGO_SUPERUSER_USERNAME": os.environ.get(
"DJANGO_SUPERUSER_USERNAME", "admin"
),
}
We can use environment variables to set an initial password for our superuser. We also define additionl environment variables that we will use for our datbase connection, and the S3 bucket that we will use for Django's static and media assets.
S3
To access S3 from our Lambda function in a VPC, we need to use a VPC Gateway Endpoint for S3. This is a free service that enables us to access S3 directly from our VPC without going through the internet, and instead using a private connection . This again has to do with the fact that our Django Lambda can't access the internet because the network interfaces created by Lambda only have private IP addresses and would require NAT in order to connect to resources on the internet. Here's how we define the VPC as well as the VPC Gateway Endpoint using CDK:
self.vpc = ec2.Vpc(
self,
"Vpc",
max_azs=2,
cidr="10.0.0.0/16",
nat_gateways=0,
subnet_configuration=[
ec2.SubnetConfiguration(
subnet_type=ec2.SubnetType.PUBLIC,
name="Public",
cidr_mask=24,
),
ec2.SubnetConfiguration(
subnet_type=ec2.SubnetType.ISOLATED,
name="Isolated",
cidr_mask=24,
),
],
)
self.vpc.add_gateway_endpoint(
"S3Gateway", service=ec2.GatewayVpcEndpointAwsService('s3')
)
With this VPC endpoint in place, we are almost ready to run our collectstatic command, but it won't work yet. This is because we haven't given our Lambda function access to write files to the S3 assets bucket for our Django application's static and media files. We can grant this permission with the following snippet from awscdk/app_stack.py, the file that defines the root CloudFormation stack for our application:
self.backend_assets_bucket.grant_read_write(
self.vpc_stack.djambda_lambda
)
Finally, we need to add the following settings to settings.py:
STATIC_URL = '/static/'
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
STATICFILES_STORAGE = "djambda.storage_backends.StaticStorage"
AWS_DEFAULT_ACL = None
AWS_STORAGE_BUCKET_NAME = os.environ.get(
"AWS_STORAGE_BUCKET_NAME", "bucketname"
)
AWS_S3_OBJECT_PARAMETERS = {
"CacheControl": "max-age=86400",
}
AWS_PRIVATE_MEDIA_LOCATION = "media/private"
AWS_STATIC_LOCATION = "static"
PRIVATE_FILE_STORAGE = "backend.storage_backends.PrivateMediaStorage"
AWS_S3_CUSTOM_DOMAIN = f"{AWS_STORAGE_BUCKET_NAME}.s3.amazonaws.com"
if not DEBUG:
MEDIA_ROOT = "media"
MEDIA_URL = f"https://{AWS_S3_CUSTOM_DOMAIN}/{MEDIA_ROOT}/"
STATIC_URL = f"https://{AWS_S3_CUSTOM_DOMAIN}/{AWS_STATIC_LOCATION}/"
FORCE_SCRIPT_NAME = "/prod"
We can run the collectstatic command with the following Lambda invocation:
aws lambda invoke \
--function-name dev-mysite-com-djambda-lambda \
--invocation-type RequestResponse \
--payload '{"manage": "collectstatic --no-input"}' \
resp.json
API Gateway and the Lambda proxy pattern
I first read about the Lambda proxy pattern in an article titled How to access VPC and internet resources from Lambda without paying for a NAT Gateway on Paul Swail's website https://serverlessfirst.com/. This site has tons of great serverless content, check out the list of articles. Thank you Paul for putting out great serverless resources!
Let's take a look at the Proxy Lambda function next. The function itself is pretty straightforward:
import json
import os
import boto3
lambda_client = boto3.client('lambda', region_name='us-east-1')
def handler(event, context):
invoke_response = lambda_client.invoke(
FunctionName=os.environ.get("FUNCTION_NAME", None),
InvocationType='RequestResponse',
Payload=json.dumps(event),
)
data = invoke_response['Payload'].read()
return data
There are just a few things to setup in our CDK code to make the proxy pattern work:
- Define the Lambda function
- Give the proxy Lambda permission to invoke the Django Lambda
- Define a
LambdaRestApiconstruct with the Proxy Lambda as thehandler
Here's what that code looks like:
self.proxy_lambda = _lambda.Function(
self,
"ProxyLambda",
code=_lambda.AssetCode("./awslambda"),
runtime=_lambda.Runtime.PYTHON_3_8,
layers=[self.djambda_layer],
handler="proxy_lambda.handler",
timeout=core.Duration.seconds(60),
environment={"FUNCTION_NAME": self.djambda_lambda.function_name},
)
self.djambda_lambda.grant_invoke(self.proxy_lambda)
self.apigw = apigw.LambdaRestApi(
self, 'DjambdaEndpoint', handler=self.proxy_lambda,
)
That's it! We can now access our Django project at the API Gateway execute-api endpoint. This is a special URL that has the format:
https://abc123.execute-api.us-east-1.amazonaws.com/prod
abc123is the id of the API Gateway that we created (you can find the value of this id in the API Gateway section of the AWS management console)]- The region
us-east-1is the region where you deployed the API Gateway /prodis the stage name
The stage name part is a little confusing for me. It is meant to be a URL suffix that indicates production, staging, etc., but I typically separate environments at the level of the CloudFormation stack, so all of my environments use the /prod suffix. In order for Django to work properly, we need to tell it that our site will be served at this /prod path (for example /admin will now be served at /prod/admin) by setting a special value in our settings module:
FORCE_SCRIPT_NAME = "/prod"
This will make dealing with URLs easier, mostly because we don't actually have to change anything in our urls.py. I tried adding /prod to my URL paths in urls.py, but the Django admin doesn't work properly because going to /prod/admin will redirect you to /admin/login which will thrown an error with API Gateway since our application must be on the /prod subpath.
Setting a custom URL for API Gateway
If you don't mind having a URL in the form of https://abc123.execute-api.us-east-1.amazonaws.com/prod, then everything should be good to go. If you do want a custom URL for API Gateway, there are only two things you need to do:
- Get a domain and hosted zone set up in Route53 (this typically costs about $12/year)
- Add the
DOMAIN_NAMEand theHOSTED_ZONE_IDto environment variables (see below for how to do this) - Define an ACM certificate in our CDK code and
- Use the
LambdaRestApi'sadd_domain_namemethod to add the domain name and certificate to the API Gateway endpoint.
Here's a link to the CDK Python documentation on add_domain_name.
When you configure a custom domain name, you don't need to set the FORCE_SCRIPT_NAME setting in Django settings.
Project directory structure
Let's take a quick look at the structure of the project using tree:
tree -L 3 .
.
├── awscdk
│ ├── app.py
│ ├── awscdk
│ │ ├── app_stack.py <----------------- CDK application overview
│ │ ├── backend_assets.py
│ │ ├── cert.py
│ │ ├── cloudfront.py
│ │ ├── hosted_zone.py
│ │ ├── __init__.py
│ │ ├── static_site_bucket.py
│ │ └── vpc.py <------------------------ VPC, Lambdas, API Gateway and more
│ ├── cdk.json defined here
│ ├── README.md
│ ├── requirements.txt
│ ├── setup.py
│ └── source.bat
├── awslambda
│ └── proxy_lambda.py <------------------- Proxy Lambda
├── django
│ ├── core <------------------------------ A sample Django app
│ │ ├── admin.py
│ │ ├── apps.py
│ │ ├── __init__.py
│ │ ├── migrations
│ │ ├── models.py
│ │ ├── tests.py
│ │ ├── urls.py
│ │ └── views.py
│ ├── djambda
│ │ ├── asgi.py
│ │ ├── awsgi.py <---------------------- Django Lambda handler
│ │ ├── __init__.py
│ │ ├── settings.py <------------------- Django settings (RDS connections, S3 static/media)
│ │ ├── storage_backends.py
│ │ ├── urls.py
│ │ └── wsgi.py
│ ├── manage.py
│ └── requirements.txt
├── layers <-------------------------------- Lambda Layers (python dependencies)
│ └── django Note: This folder is not committed to git
│ └── python
├── ARTICLE.md <---------------------------- This article
├── gitlab-ci.yml
├── .variables <---------------------------- Environment variables needed for deployment
└── README.md
The three top level folders are awscdk, awslambda and django. To deploy our CDK code, we run the following command from the root of the project:
cdk deploy --app awscdk/app.py
We can also run cdk synth --app awscdk/app.py to preview changes to our CDK code by reviewing the CloudFormation templates generated by cdk synth. Running the cdk deploy and cdk synth commands at root of the project means that we need to specificy lambda code assets from the root of the project as well. This is why the Django application's Lambda function references the code with:
code=_lambda.AssetCode('./django'),
Deploying
CDK is easy to use both locally and in a CI/CD tool such as GitLab CI, my CI/CD tool of choice. There are a few things to coordinate when deploying in both of these environments:
- Environment variables
- Dependencies
Deploying from a terminal
If you are new to CDK, you will need to make sure that you have ran the cdk bootstrap command at least once on your account. This command sets up a CloudFormation stack that CDK uses internally to manage deployments.
The environment variables needed for deployment are defined in .variables.template:
export APP_NAME=
export AWS_ACCESS_KEY_ID=
export AWS_ACCOUNT_ID=
export AWS_DEFAULT_REGION=
export AWS_SECRET_ACCESS_KEY=
export DOMAIN_NAME=
export HOSTED_ZONE_ID=
APP_NAMEshould be a URL compatible name, such asmy-app(don't put.in this variable)DOMAIN_NAMEandHOSTED_ZONE_IDare needed for adding a custom domain name to API Gateway
Copy this template into a file in the root of the project called .variables and set these environment variables with the following command:
. .variables
Next, we need to install our Python dependencies locally with the -t target flag so that the Lambda layers we define in CDK can find the files needed to be packaged into our Lambda layer and made available to our Lambda function at runtime. Install dependencies to the target directory by running the following command from the root of the project:
pip install -r django/requirements.txt -t layers/django/python
Now we can deploy our serverless application to AWS using CDK. First, activate the CDK Python virtual environment with:
source awscdk/.env/bin/activate
Also make sure that you are using a version of Node.js greater or equal to 10. I do this with nvm use 13.
Make sure that all of the dependencies defined in awscdk/setup.py are up-to-date. Make sure that there are no issues witht the CDK code by running:
cdk synth --app awscdk/app.py
Inspect the contents of cdk.out; these are the CloudFormation templates generated by CDK that will be used to deploy all of our resources. If everything looks good to go, deploy with the following command:
cdk synth --app awscdk/app.py
Follow the output of this command and ensure that it completes successfully. You can also follow along in the CloudFormation section of the AWS management console to make sure that things are deploying properly.
Once everything has finished deploying, you will need to run migrate, createsuperuser and collecstatic after the first deployment.
TODO: consolidate these steps with a Makefile or bash script
Deploying with GitLab CI
Deploying locally is fine, but it is better to run CDK commands from a CI/CD process so we can keep track of the commits, pipeline results, commit messages, etc. The process is very similar to everything we do locally, but you will need to add environment variables to the GitLab project's Settings > CI/CD > Variables. I have broken out dependency installation into a separate stage. This is not entirely necessary, but it helps keep things easy to follow:
pip_install:
stage: build
artifacts:
paths:
- layers/django/python
script:
- pip install -r django/requirements.txt -t layers/django/python
cdk_deploy:
stage: deploy
before_script:
- apt-get -qq update && apt-get -y install nodejs npm
- npm i -g aws-cdk
- pip3 install -e awscdk
script:
- cdk bootstrap --app awscdk/app.py aws://$AWS_ACCOUNT_ID/$AWS_DEFAULT_REGION
- cdk deploy --app awscdk/app.py --require-approval never
For management commands, we use a .base_task template and reuse this for each command:
.base_task: &task
image: python:3.8
stage: deploy
rules:
- when: manual
before_script:
- pip install awscli
after_script:
- cat invoke_response.json
migrate:
<<: *task
script:
- |
aws lambda invoke \
--function-name ${ENVIRONMENT}-${APP_NAME}-djambda-lambda \
--payload '{"manage": "migrate --no-input"}' \
invoke_response.json
These are manual commands, and can be started through the GitLab CI interface by pressing the "Play" button on the pipeline.
Next Steps
I still have lots of ideas and things to try out with this Django/Lambda architecture. Here are a few things that would be good to try:
- Using another Lambda function that proxies web requests to a Lambda outside of the VPC for basic network requests using either
urllib.requestorrequests. This would be the easiest way to add simple internet access without needing a NAT Gateway - Use a NAT provider to add a cheap NAT instance using a
t3a.nanoinstance ( about $5.00/month) to allow for internet access in the Django request/response cycle - Figure out a good solution for async processing. Zappa has a
@taskwrapper that allows you to run tasks asynchronously in separate Lambda functions. It would be interesting to experiment with direct invocation of async tasks as well as task queueing with SQS. Using SQS would involve a VPC Endpoint which does cost extra, or we could setup a dedicated SQS proxy function to do this in a way similar to how we would handle requests. - Lambda tuning. I'm pretty new to using Lambda and I would like to better understand how to fine-tune Lambda settings. There are lots of options in the
_lambda.Functionconstruct, which would be a good place to start. This would be especially important for async tasks that require high memeory. From the Lambda Developer Guide it looks like memory can be configured from 128 MB to 3,008 MB in 64 MB increments. - I typically setup Vue.js frontends with S3/CloudFront and use Django only for the admin and API with Django REST Framework. From what I understand, API Gateway uses CloudFront in the backround to do custom domains, but you don't have access to this CloudFront distribution. You can add the
execute-apiURL as a Custom Origin for a single CloudFront distribution, or keep a CloudFront distribution separate from the API Gateway custom domain and serve these on different subdomains, such asapi.mysite.comfor the API Gateway domain name andmysite.comfor the CloudFront distribution serving Vue.js files. - Pricing. I'm still unsure about exactly how much this setup costs. The only major costs should be Aurora Postgres Serverless if it is used heavily, but I'm still not sure about how the pricing for this service works. Here's an in-depth article from Jeremy Daly that has more information on Aurora Serverless: https://www.jeremydaly.com/aurora-serverless-the-good-the-bad-and-the-scalable/
Thanks for reading!