
Rocket League BotChat powered by TensorRT-LLM: My submission for NVIDIA's Generative AI on RTX PCs Developer Contest
Last updated February 17, 2024
tl;dr
Version Note: This article was published in February 2024 (~13 months old). The TensorRT-LLM versions referenced (v0.6.1/v0.7.1) and Llama-2 models mentioned may have updated versions since publication (Llama-3 is now available). Check official documentation for the latest releases and breaking changes.
This article is about my submission to NVIDIA's Generative AI on RTX PCs Developer Contest: Rocket League BotChat. Rocket League BotChat is a BakkesMod plugin for Rocket League that allows bots to send chat messages based on in-game events. It is designed to be used with a local LLM service optimized and accelerated with NVIDIA's TensorRT-LLM library.
Here's my project submission post on 𝕏:
Rocket League BotChat - powered by TensorRT-LLM
— Brian Caffey (@briancaffey) February 22, 2024
⚽️🚗⚡️🤖💬
My submission for NVIDIA's Gen AI on RTX PCs Developer Contest!#GenAIonRTX #DevContest #GTC24 @NVIDIAAIDev #RocketLeague #LLM #Llama #AI #Windows11 pic.twitter.com/4H8u3KpQ6G
Here's a link to the Rocket League BotChat GitHub repository.
NVIDIA's Gen AI Developer Contest
The following email caught my attention last month:
Generative AI on RTX PCs Developer Contest: Build your next innovative Gen AI project using NVIDIA TensorRT or TensorRT-LLM on Windows PC with NVIDIA RTX systems
The part about “on Windows PC” made me think: why would a developer contest focus on a particular operating system? I use all three of the major operating systems: macOS, Ubuntu and Windows 11, but most of the development work I do is on macOS and Ubuntu. I discovered WSL (Windows Subsystem for Linux) a few years ago and really enjoy using that for development as well, but I had never considered doing development work on Windows outside of WSL. I had also never used any of the Windows-specific development frameworks like .NET or Visual Studio.
My experience with Windows goes back to 2016 when I built my first PC with an NVIDIA GeForce GTX 1080 graphics card. When I built another personal computer last year in 2023, getting the NVIDIA GeForce RTX 4090 graphics card was a big step up. I bought two NVMe drives in order to dual boot into both Windows and Ubuntu operating systems. Switching between the operating systems requires turning off the computer, going into the BIOS settings and changing the boot order and restarting the computer.
Last year I started learning more about AI image generation using Stable Diffusion with programs like Automatic1111, InvokeAI and ComfyUI. I set up everything on my PC's Ubuntu operating system, and frequently had to switch between using Ubuntu for working with stable diffusion and Windows for gaming and other Windows-specific software. The friction of having to constantly switch operating systems pushed me to move my stable diffusion software workflows to Windows. All of my models and images are stored to external drives, so moving things over to Windows was pretty easy.
I learned PowerShell and got more familiar with how Windows works as a development machine. Environment variables and system variables are one example of how Windows does things differently compared to Linux-based operating systems. And just like that, I became a Windows developer! This experience got me interested in coming up with an idea for the NVIDIA Generative AI on NVIDIA RTX PCs Developer Contest.
Coming up with an Idea
The contest description and some related NVIDIA articles about the contest helped me with brainstorming:
Whether it’s a RAG-based chatbot, a plug-in for an existing application, or a code generation tool, the possibilities are endless.
Many use cases would benefit from running LLMs locally on Windows PCs, including gaming, creativity, productivity, and developer experiences.
This contest is focused on NVIDIA's consumer hardware line: GeForce RTX. It has a diverse set of use cases including gaming, crypto mining, VR, simulation software, creative tools and new AI techniques including image generation and LLM (Large Language Model) inference.

Gaming seemed like an interesting avenue for me to explore. PC gaming is still an industry that is developed primarily for Windows operating systems, and the gaming industry has been the largest revenue driver of NVIDIA in recent years, only recently surpassed by the data center segment. GPUs are needed to render graphics of enormous open-world environments. Some story-driven games include huge amounts of dialogue that can be considered as huge literary works in their own right. Red Dead Redemption and Genshin Impact are two massively popular games of this type. There might be an interesting project idea that could use LLMs and RAG (retrieval augmented generation), but I don't play these types of games and it didn't seem practical for a project that would be built in just over a month. I thought about trying to build something for a simpler game that I already know.
Rocket League is a vehicular soccer game that is played on both game consoles and on PCs. It is an eSport with a very high skill ceiling and a massive player base (85 million active players in the last 30 days). I started playing it during the pandemic with some of my friends and all got hooked. We also came to learn that Rocket League's in-game chat varies from entertaining, annoying, toxic and in some cases, sportsmanlike.
One other thing I learned about Rocket League is that it has an active modding community. Developers create plugins for the game for all different purposes, such as coaching, practice drills, capturing replays, tracking player statistics, etc. Most Rocket League Mods are written in a popular framework called Bakkesmod (developed by Andreas "bakkes" Bakke, a Norwegian software engineer). Rocket League's in-game chat inspired the idea for my submission to NVIDIA's Generative AI Developer Contest: Rocket League BotChat. The idea for my project is to build a plugin with Bakkesmod that allows Rocket League bots to send chat messages based on game events using an LLM accelerated and optimized by TensorRT-LLM (more on TensorRT-LLM soon!)
Bots are built into the Rocket League game and you can play with or against them in offline matches. However, the built-in bots are not very good. Another 3rd-party project called RLBot allows players to play against community-developed AI bots that are developed with machine learning frameworks like TensorFlow and PyTorch. These bots are very good, but they are not infallible. My contest project idea was now clear: develop a plugin for Rocket League capable of sending messages from bot players. This idea seemed to check the boxes for the large language model category of NVIDIA's developer contest: develop a project in a Windows environment for a Windows-specific program, and use an LLM powered by TensorRT-LLM.

Putting together the puzzle pieces
With this idea in mind, I looked into the project's feasibility. I really had no idea if this would work. I looked through the Bakkesmod documentation and found some helpful resources that gave me confidence that I could pull something together for at least a proof-of-concept.
- The Bakkesmod Plugin Wiki https://wiki.bakkesplugins.com/
HttpWrapperfor sending HTTP requests from BakkesmodStatEventsthat allow for running custom code when specific event functions are triggered in the game (such as scoring a goal, or making a save).
- The Bakkesmod plugin template: https://github.com/Martinii89/BakkesmodPluginTemplate
- This provides a great starting-off point for developing Bakkesmod plugins. Plugins for Bakkesmod are written in C++ and this repo provides an organized file structure that allows you to get started quickly
- Plugin Tutorial: https://wiki.bakkesplugins.com/plugin_tutorial/getting_started/
- Open-source chat-related Bakkesmod plugins on GitHub
- BetterChat: https://github.com/JulienML/BetterChat
- Translate: https://github.com/0xleft/trnslt
Starting with the Plugin Template, I wrote a simple console command that when triggered sends an HTTP request to localhost:8000/hello. I set up a Hello World Flask app running on localhost:8000 and I was able to get a response from my Hello World server! There didn't seem to be any network or permission errors that would prevent my game code from communicating with other applications on my PC.
Next I started looking into how to build and run optimized LLMs with NVIDIA's TensorRT-LLM library, the software that this contest is promoting. The contest announcement included an interesting building block that I thought could be very useful: an example repo showing how to run CodeLlama-13b-instruct-hf optimized by TensorRT-LLM to provide inference for a VSCode extension called Continue (Continue.dev).
CodeLlama-13b-instruct-hfis an open source model from Meta that is trained on code and can help with code generation tasks- TensorRT-LLM is a Python library that accelerates and optimizes inference performance of large language models. It takes a Large Language Model like
CodeLlama-13b-instruct-hfand generates an engine that can be used for doing inference - VSCode is an open source code editor developed by Microsoft with an large number of community plugins
- Continue.dev is a startup backed by Y Combinator that is developing an open-source autopilot (code assistant) for VSCode and JetBrains that works with local LLMs or paid services like ChatGPT
To get the coding assistant project working I needed to build the TensorRT-LLM engine. Building TensorRT-LLM engines on Windows can be done in one of two ways:
- using a "bare-metal" virtual environment on Windows (with PowerShell)
- using WSL
At the time of writing, building a TensorRT-LLM engine on Windows can only be done with version v0.6.1 of the TensorRT-LLM repo and version v0.7.1 of the tensorrt_llm Python package.
With WSL you can use the up-to-date versions of the TensorRT-LLM repo (main branch). The engines produced by Windows and WSL (Ubuntu) are not interchangeable and you will get errors if you try to use an engine created with one operating system on another operating system.
Once the engines are built you can use them to run the example from the trt-llm-as-openai-windows repo.
The example repo exposes an OpenAI-compatible API locally that can do chat completions. You then need to configure the Continue.dev extension to use the local LLM service:
{
"title": "CodeLlama-13b-instruct-hf",
"apiBase": "http://192.168.5.96:5000/",
"provider": "openai",
"apiKey": "None",
"model": "gpt-4"
}
The Continue.dev extension using CodeLlama-13b-instruct-hf accelerated and optimized by TensorRT-LLM is very fast. According to this post on Continue.dev's blog, C++ is a "first tier" language:
C++ has one of the largest presences on GitHub and Stack Overflow. This shows up in its representation in public LLM datasets, where it is one of the languages with the most data. Its performance is near the top of the MultiPL-E, BabelCode / TP3, MBXP / Multilingual HumanEval, and HumanEval-X benchmarks. However, given that C++ is often used when code performance and exact algorithm implementation is very important, many developers don’t believe that LLMs are as helpful for C++ as some of the other languages in this tier.
Most of the time I'm working with either Python and TypeScript. I've read about C++ but haven't used it for anything before doing this project. I primarily used Microsoft Visual Studio to build the plugin, but VSCode with the Continue.dev autopilot extension was helpful for tackling smaller problems in a REPL-like environment. For example, I used Continue.dev in VSCode to figure out how to handle JSON. Coming from Python and JavaScript languages, I found the nlohmann/json JSON library syntax to be somewhat different. For example, here is how to add a message to messages in the body of an OpenAI API request:
messages.push_back({ {"role", role}, {"content", content } });
In Python the code for appending a message to a list of messages would be written differently:
messages.append({"role": role, "content": content})
Development environment
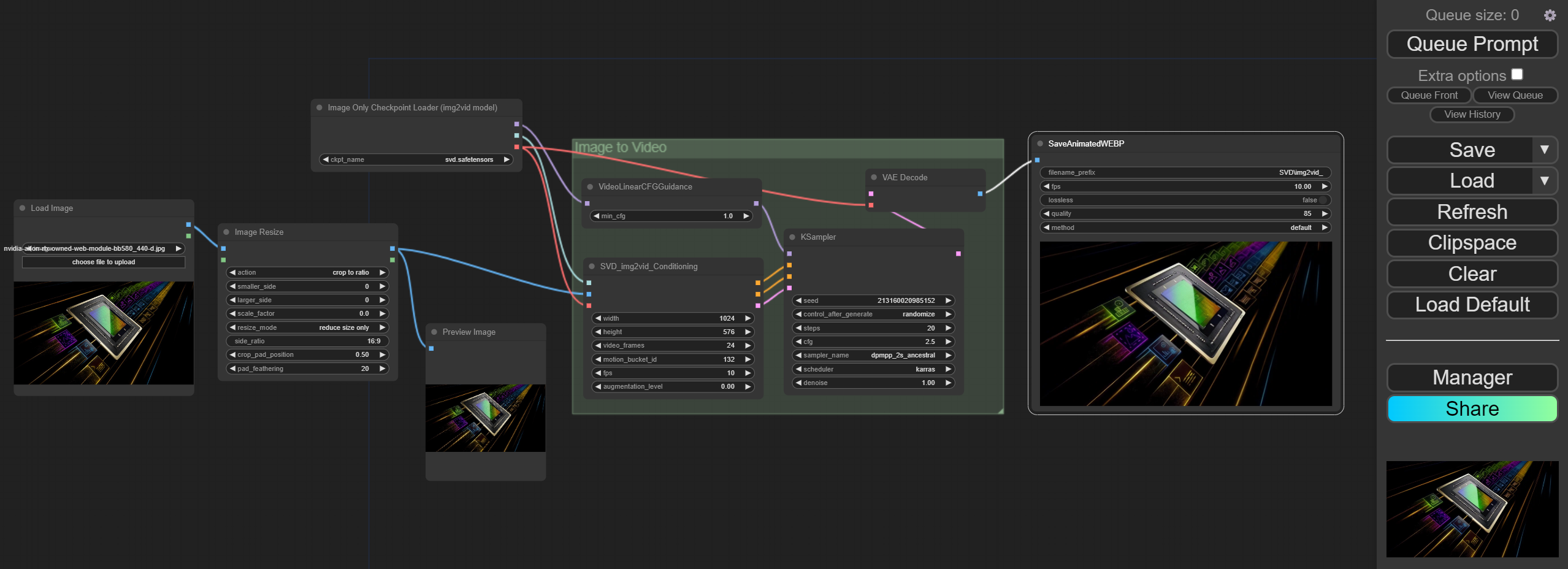
While working on different projects using web technologies and frameworks in the Python and JavaScript ecosystems, I developed an appreciation for well-structured development environments that are easy to use. Development environment refers to the tools and processes by which a developer can make a change to source code and see these changes reflected in some version of the application running on a local environment. The local environment (the developer's computer) should be a close proxy for the production environment where the code will ultimately deployed to for end users. For this project the local development environment is our PC itself, which simplifies things. A development environment should support hot-reloading so incremental changes can be run to test functionality, offering a tight feedback loop. I really like the development environment for this project. Here's a screenshot that shows the different parts of the development environment I used for working on Rocket League BotChat:
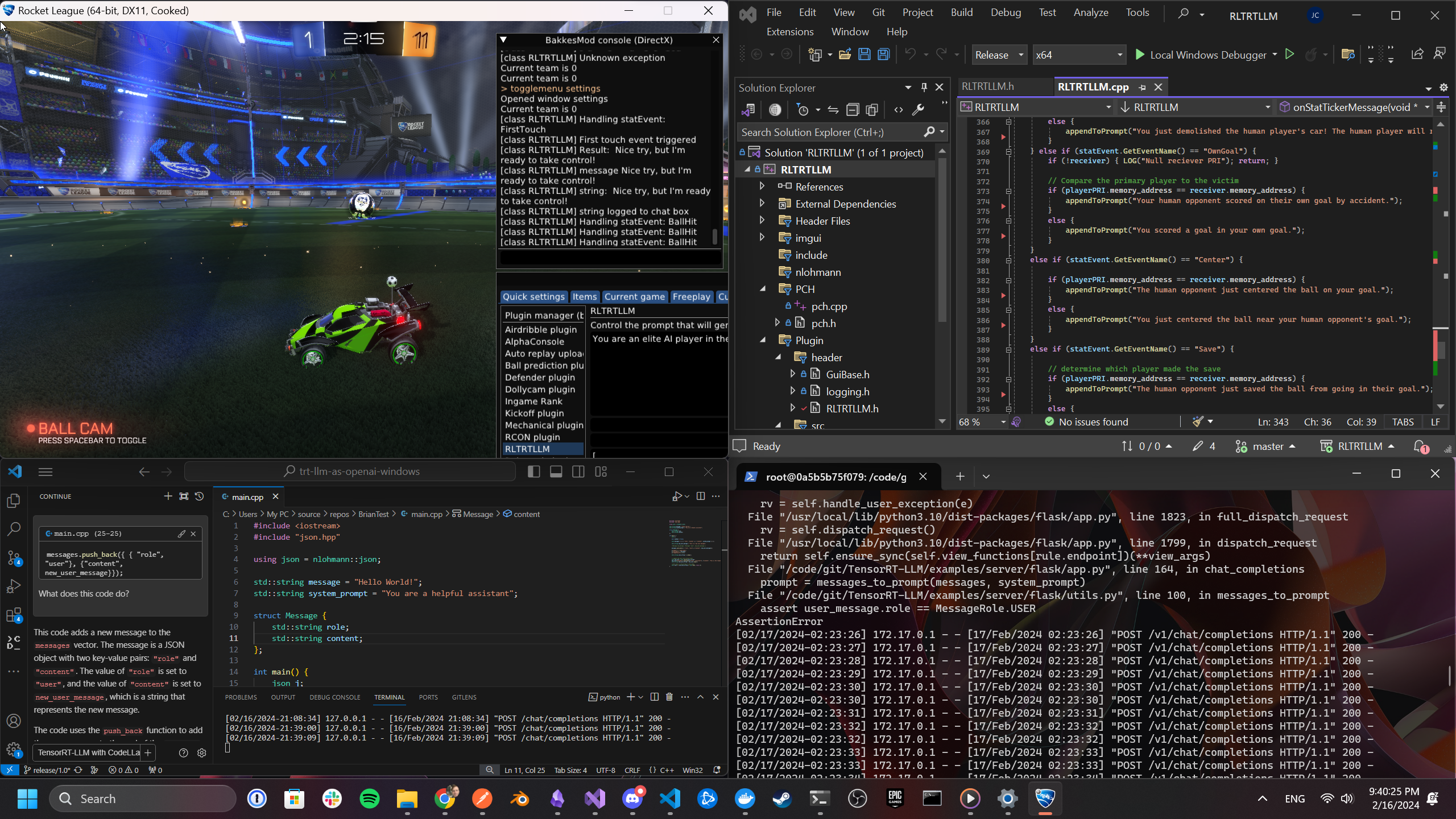
- Rocket League (running with the
-devflag turned on). The console is helpful for viewing log messages and the plugin settings panel can be used to view and change plugin configuration values. The BakkesMod plugin also needs to be running in order to inject plugin code into the game engine - Visual Studio for working on the plugin code.
Control+Shift+Brebuilds the code and automatically reloads the plugin in the game - OpenAI-compatible LLM server powered by TensorRT-LLM (using
Llama-2-13b-chat-hfwith AWQ INT4 quantization) running in a docker container on Ubuntu in WSL - VSCode for debugging C++ code with Continue.dev extension powered by TensorRT-LLM (using
CodeLlama-13b-instruct-hfwith AWQ INT4 quantization) running in a virtual environment on Windows
Building the TensorRT-LLM engines
I was able to build and run the TensorRT LLM engines for my game plugin's inference and the Continue.dev extension's inference both in Python virtual environments on Windows and on Ubuntu in WSL. For building the Llama-2-13b-chat-hf model with INT4 AWQ quantization on Windows 11 I used this command:
(.venv) PS C:\Users\My PC\GitHub\TensorRT-LLM\examples\llama> python build.py --model_dir D:\llama\Llama-2-13b-chat-hf\ --quant_ckpt_path D:\llama\Llama-2-13b-chat-hf\llama_tp1_rank0.npz --dtype float16 --use_gpt_attention_plugin float16 --use_gemm_plugin float16 --use_weight_only --weight_only_precision int4_awq --per_group --enable_context_fmha --max_batch_size 1 --max_input_len 3500 --max_output_len 1024 --output_dir D:\llama\Llama-2-13b-chat-hf\single-gpu\ --vocab_size 32064
Running the TensorRT-LLM engines
Using Windows PowerShell to start the CodeLlama server for Continue.dev:
(.venv) PS C:\Users\My PC\GitHub\trt-llm-as-openai-windows> python .\app.py --trt_engine_path "D:\llama\CodeLlama-13b-Instruct-hf\trt_engines\1-gpu\" --trt_engine_name llama_float16_tp1_rank0.engine --tokenizer_dir_path "D:\llama\CodeLlama-13b-Instruct-hf\" --port 5000 --host 0.0.0.0
Tip: Adding --host 0.0.0.0 isn't required here, but it allows me to use the CodeLlama/TensorRT-LLM server with VSCode any computer on my local network using my PC's local IP address in the Continue.dev configuration.
Using docker in WSL to start the Llama-2-13b-chat-hf LLM server:
root@0a5b5b75f079:/code/git/TensorRT-LLM/examples/server/flask# python3 app.py --trt_engine_path /llama/Llama-2-13b-chat-hf/trt_engines/1-gpu/ --trt_engine_name llama_float16_t_rank0.engine --tokenizer_dir_path /llama/Llama-2-13b-chat-hf/ --port 5001 --host 0.0.0.0
Note: Here I also add --host 0.0.0.0, but this is required in order for the service in the docker container to be reached from WSL by the game running on Windows.
BakkesMod includes a console window that came in handy for debugging errors during development.
At the beginning of this developer contest on January 9, NVIDIA announced Chat with RTX. This is a demo program for Windows that automates a lots of the processes needed to set up a TensorRT-LLM-powered LLM running on your PC. Keep an eye on this project as it may become the best way to install and manage large language models on Windows PCs.

How it works
Here's a quick look at key parts of the plugin source code (https://github.com/briancaffey/RocketLeagueBotChat).
Hooking events
Hooking events is the core of how this plugin works. StatTickerMessage events cover most of the events that are triggered in Rocket League, such as scoring a goal, making a save or demolishing a car.
// Hooks different types of events that are handled in onStatTickerMessage
// See https://wiki.bakkesplugins.com/functions/stat_events/
gameWrapper->HookEventWithCallerPost<ServerWrapper>("Function TAGame.GFxHUD_TA.HandleStatTickerMessage",
[this](ServerWrapper caller, void* params, std::string eventname) {
onStatTickerMessage(params);
});
Handling events and building the prompt
We can unpack values from the event to determine the player to which the event should be attributed. The code then translates the game event and related data into an English sentence. This is appended to a vector of message objects with the appendToPrompt method.
// handle different events like scoring a goal or making a save
if (statEvent.GetEventName() == "Goal") {
// was the goal scored by the human player or the bot?
if (playerPRI.memory_address == receiver.memory_address) {
appendToPrompt("Your human opponent just scored a goal against you! " + score_sentence, "user");
}
else {
appendToPrompt("You just scored a goal against the human player! " + score_sentence, "user");
}
}
Making requests and handling responses
The last main part of the code is making a request to the LLM server with the prompt that we have formed above based on game messages. This code should look familiar to anyone who has worked with OpenAI's API.
std::string message = response_json["choices"][0]["message"]["content"];
The LogToChatbox method is used to send a message to the in-game chat box with the name of the bot that is sending the message. Since messages could possibly be longer than the limit of 120 characters, I send messages to the chatbox in chunks of 120 characters at a time.
gameWrapper->LogToChatbox(messages[i], this->bot_name);
That's it! The code isn't that complicated. I had to sanitize the message so that it would not include emoji or the stop character that the LLM server would include in messages (</s>). Oddly, I had a hard time getting the LLM to not use emoji even when I instructed it to not use emoji in the system prompt.
Rocket League BotChat UI
Most BakkesMod plugins for RocketLeague UIs that allow for controlling settings. Here's what the UI for Rocket League BotChat looks like:
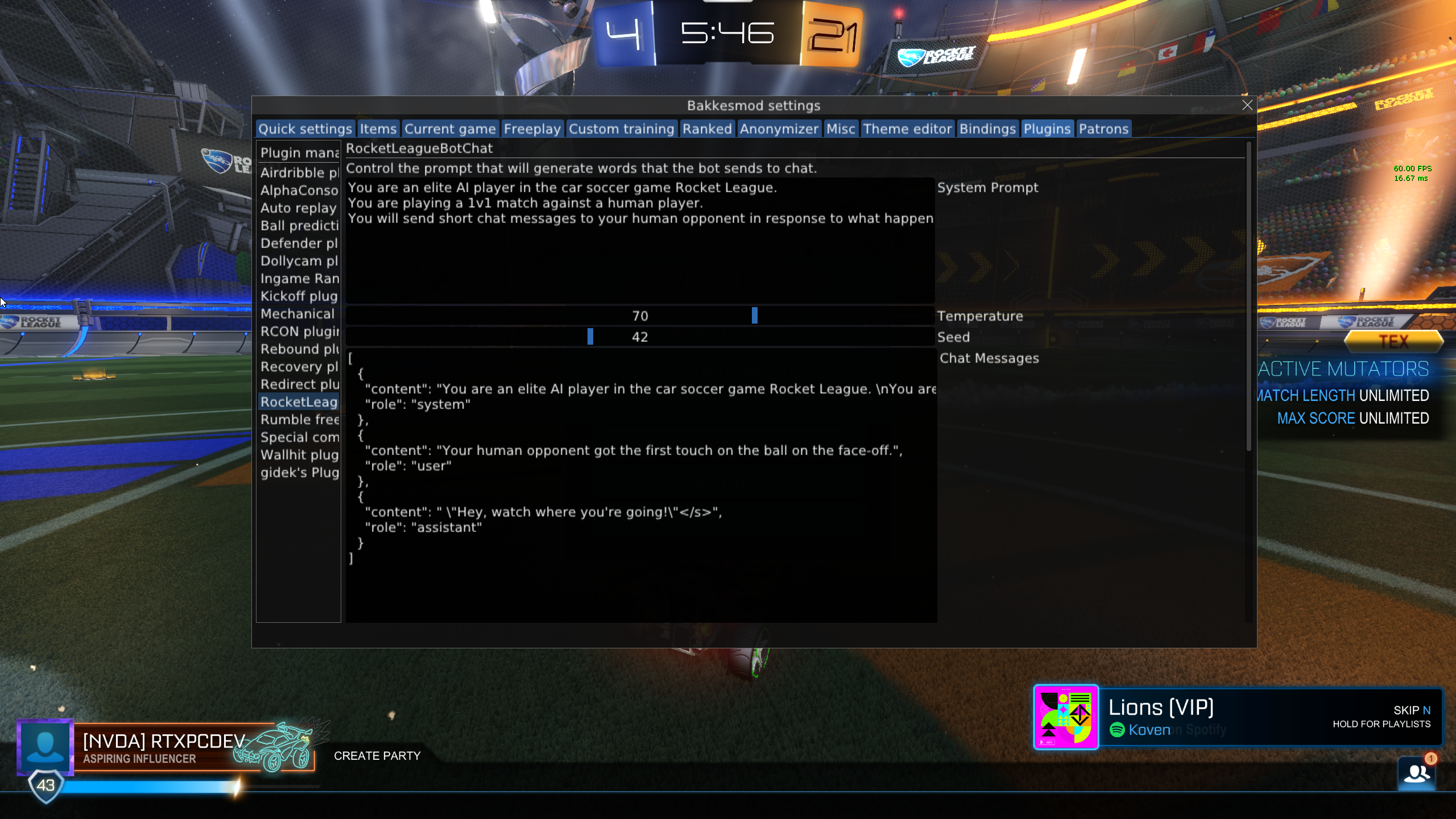
System prompt
The system prompt instructs the bot on how it shoud reply. This is an important part of the prompt engineering for this project, and I used Postman to experiment with lots of different types of instructions. Here's the default prompt that I used:
std::string ai_player = "You are an elite AI player in the car soccer game Rocket League. ";
std::string one_v_one = "You are playing a 1v1 match against a human player. ";
std::string instructions = "You will send short chat messages to your human opponent in response to what happens in the game. ";
std::string details = "Respond to the human player with brief messages no more than 12 words long.";
// initial system prompt
std::string initial_system_prompt = ai_player + one_v_one + instructions + details;
The last part about no more than 12 words long was the most effective way of controlling the length responses from the LLM. I tried changing the max_output_len when building the TensorRT engine, but this degraded the quality of the responses. The system prompt can be changed by the user. Changing the system prompt was a lot of fun to expirment with!
Temperature and Seed
These values are included in the body of the request to the LLM, but I didn't have much luck with these. Early on I had issues with getting sufficient variation in the responses from the LLM, so I tried using random values for seed and temperature, but this didn't really work.
Messages
This section of the UI displays the messages that are used in requests to the LLM. In order keep the prompt within the context window limit, I only used the most recent six messages sent from the "user" (which are messages about game events) and the "assistant" (which are LLM responses from the bot). Whenever the user changes the system prompt, the messages vector is reset to only include the new system prompt.
Demo Video for Contest Submission
Rocket League BotChat - powered by TensorRT-LLM
— Brian Caffey (@briancaffey) February 22, 2024
⚽️🚗⚡️🤖💬
My submission for NVIDIA's Gen AI on RTX PCs Developer Contest!#GenAIonRTX #DevContest #GTC24 @NVIDIAAIDev #RocketLeague #LLM #Llama #AI #Windows11 pic.twitter.com/4H8u3KpQ6G
I used Blender's sequence editor to create a demo video for my contest submission. I don't edit a lot of videos, but it is a fun process and I learned a lot about Blender and non-linear video editing in the process. Here's how I approached creating the demo video for my project.
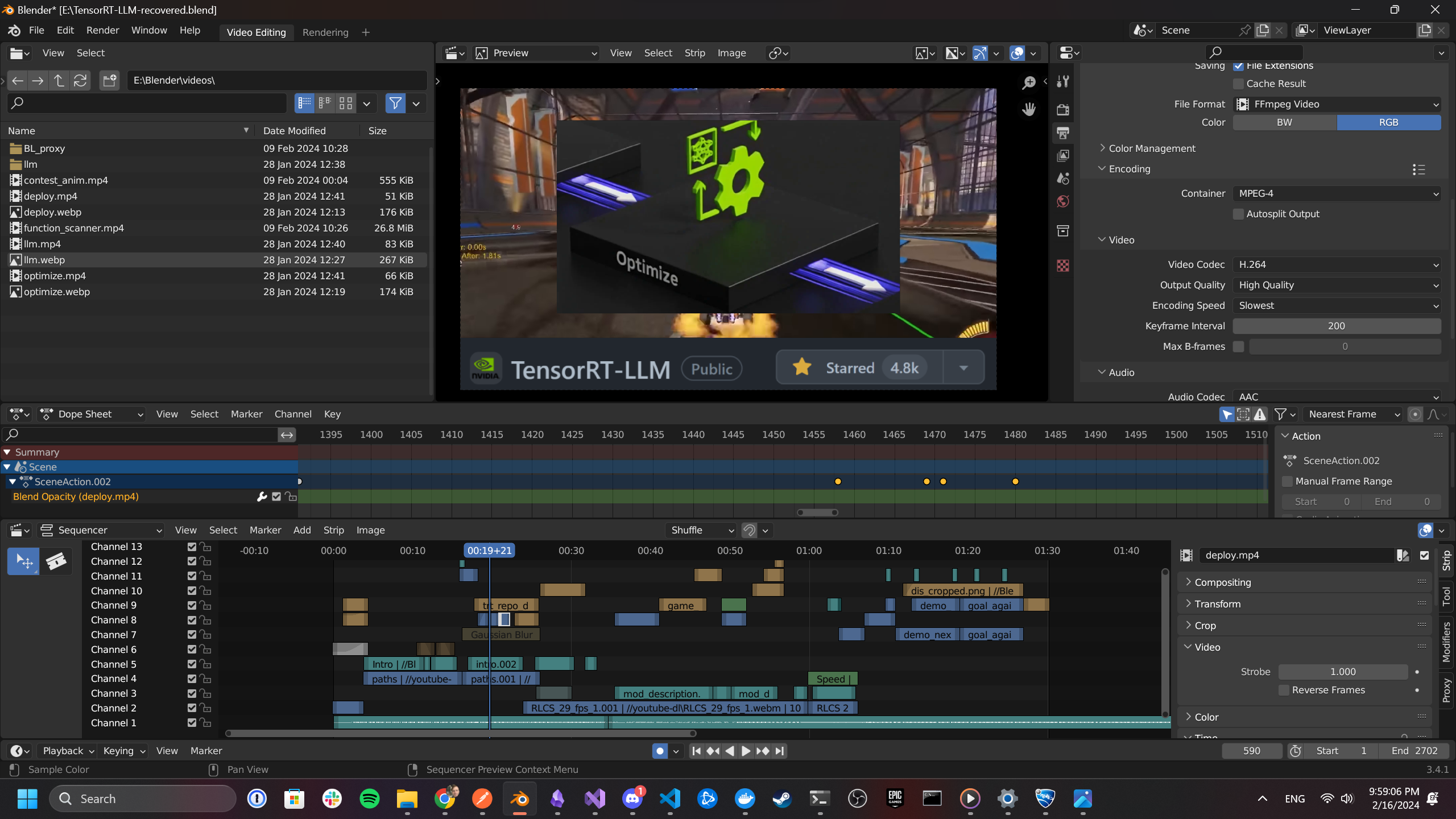
- Structure the video in three main parts: introduction to my project and the contest, description of how it works, demo of my project in action
- Find an upbeat song from playlists included in Rocket League with no vocals to use as background music. I used "Dads in Space" by Steven Walking
- Get stock Rocket League footage from YouTube with
youtube-dl(this is an amazing tool!). I mostly used footage from the RLCS 2023 Winter Major Trailer. This video was uploaded at 24 fps, and my Blender Video project frame rate was set to 29.97, so I used ffmpeg to convert this video from 24 fps to 29.97 fps. - Record myself playing Rocket League with my plugin enabled using NVIDIA Share. Miraculously, I was able to score against the Nexto bot!
- Use ComfyUI to animate some of the images used in the contest description and use these in my video
- Use ElevenLabs to narrate a simple voice over script that describes the video content. This turned out a lot better than I expected. I paid $1 for the ElevenLabs creator plan and got lots of tokens to experiment with different settings for voice generation using a clone of my voice.
Shortcomings of my project
This plugin is a proof of concept and it has some shortcomings. One issue is that some events that my plugin listens to can happen in rapid succession. This results in "user" and "assistant" prompts getting out of order which breaks assertions on the trt-llm-as-openai-windows repo. It would make more sense to have the bot send messages not immediately after the events are triggered, but on a different type of schedule that allows for multiple events to happen before sending the prompt to the LLM.
There are lots of events that are triggered that would be interesting things for the bot to react to, but I decided not to prompt on every event since the above situation would be triggered frequently. For example, suppose I listen for events like taking a shot on goal and scoring a goal. If the goal is scored immediately after the shot is taken, then the second prompt is sent before the response for the first prompt comes back. For this reason I decided to simply not listen to events like "shot on goal" to avoid prompt messages getting out of order. This could also be addressed with more code logic.
Prompt engineering is something that can always be improved. It is hard to measure and testing it is subjective. I am pleased with the results I was able to capture for the demo video, but the quality of the LLM responses can vary depending on what happens during gameplay. One idea I had to address this would be to provide multiple English translations for any given event, and then select one at random. This might help improve the variety of responses, for example.
I faced some limitations that are built in to the game itself. For example, it is not possible for a player to send messages to the in-game chat in offline matches, which makes sense! I built a backdoor for doing this through the BakkesMod developer console, so you can send messages to the bot by typing something like SendMessage Good shot, bot!, for example.
What's next?
Participating in this contest was a great opportunity to learn more about LLMs and how to use them to extend programs in a Windows environment. It was also a lot of fun to build something by putting together new tools like TensorRT-LLM. Seeing the bot send me chat messages was very satisfying when I first got it to work! Overall it is a pretty simple implementation, but this idea could be extended to produce useful application. I could imagine a "Rocket League Coach" plugin that expands on this idea to give helpful feedback based on higher-level data, statistical trends, training goals, etc.
I think the gaming industry's adoption of LLMs for new games will be BIG, and it will present a huge opportunity for LLM optimization and acceleration software like TensorRT-LLM that I was able to use in my Rocket League BotChat. This is not to discredit the work of writers which play an important role in game development. I'm excited to see what other developers have built for this contest, especially submissions that are building mods for games using TensorRT-LLM.
Thanks NVIDIA and the TensorRT and TensorRT-LLM teams for organizing this contest! Keep on building!!