
RedLM: My submission for the NVIDIA and LlamaIndex Developer Contest
Last updated November 9, 2024
tl;dr
RedLM is a new way to study art and literature powered by artificial intelligence. It is an application that applies LLMs to the study of one of China's most famous literary works: Dream of the Red Chamber. It uses leading language and vision models from Chinese AI groups including Alibaba's Qwen, Baichuan Intelligence Technology and 01.AI. RedLM uses tools, techniques and services from NVIDIA and LlamaIndex including NVIDIA NIMs, Retrieval Augmented Generation and Multi-Modal RAG with vision language models. This project is my submission for the NVIDIA and LlamaIndex Developer Contest.
This article will cover how I built the project, challenges I faced and some of the lessons I learned while working with NVIDIA and LlamaIndex technologies.
Links
/>RedLM: An AI-powered application for Redology
— Brian Caffey (@briancaffey) November 9, 2024
🪨✨📜🔎🖼️
A project for the #NVIDIADevContest #LlamaIndex @NVIDIAAIDev @llama_index pic.twitter.com/BUaBBbsLGl
What is RedLM?
RedLM is a combination of the word "Red" and LM, an abbreviation for "language model". Dream of the Red Chamber is such an important book in Chinese literature that it has its own field of study called 红学 (literally "the study of red"), or Redology. So, RedLM is an application that uses language models for the study of Redology.

In this project I focused on three applications of language models:
- Summary and translation of the source text
- A Q&A bot that can answer questions about the book providing references to the specific paragraphs used to give answers
- An image-based Q&A bot that can answer questions about sections of paintings that depict scenes from each of the book's chapters.
NotebookLM
I used this article to create a "Deep Dive" podcast episode for RedLM using Google's NotebookLM.
You can listen to this podcast episode here on 𝕏.
🎙️ a "deep dive" episode all about RedLM
— Brian Caffey (@briancaffey) November 9, 2024
made with #NotebookLM, whisper, pyannote and Blender pic.twitter.com/7BC4SIWs2E
How I built RedLM
RedLM consists of two parts: a web UI built with Vue 3 using the Nuxt Framework and a backend API built with Python, FastAPI and LlamaIndex. There are lots of great tools for building full-stack AI applications such as Gradio and Streamlit, but I wanted to build with the web tools that I'm most familiar with and that provide the most flexibility. These frameworks (Nuxt and FastAPI) are simple and effective and they allowed me to develop quickly.
Most of the code for this project was written by AI. I used OpenAI's ChatGPT 4o, Anthropic's Claude 3.5 Sonnet and 01.AI's Yi-1.5-9B-Chat model. In my development process with AI, I prompted for one logical piece of the application at a time, such as one API route, one Vue component, one pinia store or one utility function, for example. In this article I'll share some of the prompts I used in my development workflow.
This project embraces a hybrid AI inference model, meaning that the AI inference can be done either on local RTX PCs or using NVIDIA's Cloud APIs from build.nvidia.com depending on configuration via environment variables. I used PCs with NVIDIA GeForce RTX 4090 GPUs to do inference with language and vision models, and with a change of configuration, I was able to do similar inference using NVIDIA's API endpoints. This allowed me to develop the project both on powerful RTX desktop workstations and Mac laptops.
Translating Dream of the Red Chamber with TensorRT-LLM
Translation is often mentioned as one of the capabilities of bilingual LLMs from China. I wanted to try translating this book from Chinese to English, but I also wanted to better understand the meaning of the original text written in vernacular Chinese. Written vernacular Chinese is essentially a form of Chinese that closely resembles the way Chinese was spoken in imperial China by common people. The use of vernacular Chinese (Baihua) in literary works marked a significant cultural shift that started to make literature and education more accessible. Before the emergence of written vernacular Chinese, Chinese literature was dominated by Classical Chinese (Wenyanwen) which is a more concise, ambiguous and specialized form of language that assumes an understanding of ancient texts and Confucian classics. The difference between vernacular Chinese and modern Mandarin Chinese is somewhat analogous to the difference between Shakespearean English (Early Modern English) and Modern English.

Chinese large language models are well versed in Classical Chinese, written Chinese vernacular and modern Mandarin Chinese. I decided to rewrite the original vernacular text in simple, modern Mandarin Chinese and then using this new modern Mandarin version, translate the story into English.
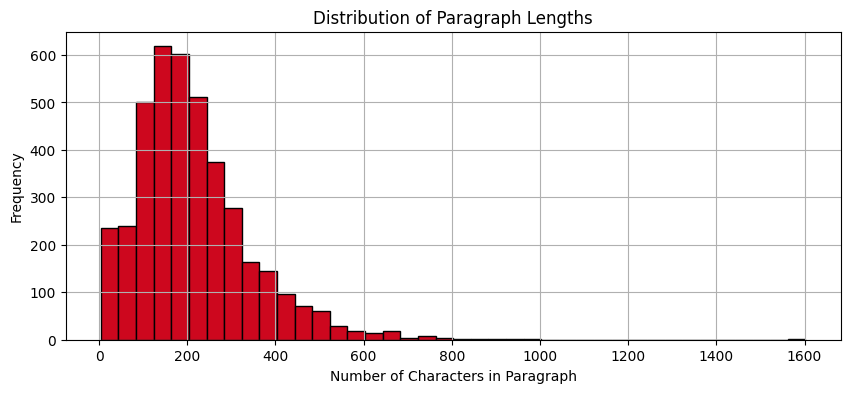
Dream of the Red Chamber is a large book. It is composed of over 800,000 Chinese characters, using 4303 unique Chinese characters. It has 120 chapters and a total of 3996 paragraphs. Here is a histogram showing the number of characters per paragraph.
I rented a large multi-GPU instance from AWS using some of the credits I get as a member of the AWS Community Builders program. The g5.12xlarge instance I selected has 4 A10G Tensor Core GPUs. The TensorRT-LLM LLM API is a relatively new part of the TensorRT-LLM library. It provides a very simple, high-level interface for doing inference. Following the LLM Generate Distributed example from the TensorRT-LLM documentation, I was able to translate the entire book into simple Mandarin and then from Mandarin into English in about an hour and 15 minutes. The tensor_parallel_size option in the LLM API allows for distributed inference, this meant that up to 4 paragraphs could be translated at the same time on different GPUs on the same EC2 instance.
Translating: data/book/22.json
Processed requests: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 38/38 [00:15<00:00, 2.41it/s]
Processed requests: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 38/38 [00:24<00:00, 1.54it/s]
Translated: data/book/22.json
Translating: data/book/114.json
Processed requests: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:11<00:00, 1.81it/s]
Processed requests: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:12<00:00, 1.58it/s]
Translated: data/book/114.json
[TensorRT-LLM][INFO] Refreshed the MPI local session
[TensorRT-LLM][INFO] Refreshed the MPI local session
[TensorRT-LLM][INFO] Refreshed the MPI local session
[TensorRT-LLM][INFO] Refreshed the MPI local session
real 74m1.578s
user 0m45.936s
sys 0m36.283s
Getting good results required a bit of experimentation with parameters. The LLM API makes this very easy. The following code configures settings and builds the inference engine that can be used for doing completions:
sampling_params = SamplingParams(temperature=0.7, top_p=0.95, max_tokens=256)
build_config = BuildConfig(max_seq_len=2048)
llm = LLM(model=MODEL, build_config=build_config, tensor_parallel_size=4)
I used the following prompts to rewrite each paragraph of the original text in simple, modern Mandarin Chinese:
bai_prompts = [
# Here are examples of how to rewrite Chinese vernacular into simple modern Mandarin.\n\nChinese vernacular:\n\n{p}\n\nSimple modern Mandarin
f"以下是如何将中国白话改写为简单的现代普通话的示例。\n\n中文白话:\n\n{p}\n\n简单的现代普通话:\n\n"
for p in flat_bai
]
It was difficult to get good results consistently. Here are some observations I had:
- Some of the translated paragraphs were perfect
- Some translated paragraphs would randomly hallucinate the same phrase over and over again
- Some requests to translate text to English would reply in Mandarin Chinese rather than in English
- Sometimes I would even see computer code generated when asking for a translation
- The names of characters were sometimes translated inconsistently, sometimes literally and sometimes using differing versions of pinyin, the Romanization system for transcribing the sounds of Mandarin Chinese
I found that ChatGPT 4o could handle any Chinese translation task flawlessly, but the Qwen2-7B model I used had mixed results! The change that I made that seemed to have the biggest impact on translation quality was setting *max_tokens*=256 in SamplingParams. I probably could have used a dynamic value for max_tokens based on the size of the current paragraph being translated. I also would have like to set up side-by-side comparisons of translations using different sized models, but rather than spend time and AWS credits on optimizing translation with TensorRT-LLM, I wanted to focus on the main part of this project: retrieval augmented generation (RAG) with LlamaIndex.
Building Q&A bots with RAG using LlamaIndex
My primary objective with this project was to implement a simple chat bot that responds to questions about the book with references to the specific paragraphs used in the response. The following shows images of the UI I built with one of the examples I included in the video I made for this project.

I haven't read that much of the book before working on this project, but I have read a lot about this book's characters, major themes and plot. This Q&A bot was a very interesting entrypoint to explore specific passages of the book starting with questions coming from my knowledge about the book. The question in the screenshots above is: "What does Jia Baoyu's father think about him?" The response includes references to paragraphs where Jia Zheng (Baoyu's father) is discussing his son. I was pretty amazed that the RAG query was able to pull out these two paragraphs.
In Dream of the Red Chamber, the relationship between protagonist Jia Baoyu and his father, Jia Zheng, is complex and fraught with tension. Jia Zheng, a strict, traditional Confucian patriarch, embodies values of discipline, scholarly rigor, and duty. He expects his son to excel in his studies and uphold the family's honor by pursuing an official career in government. Baoyu, however, is sensitive, imaginative, and inclined toward poetry and the company of women, especially his cousins Lin Daiyu and Xue Baochai. This preference clashes with Jia Zheng's expectations, leading to frequent misunderstandings and disappointment.
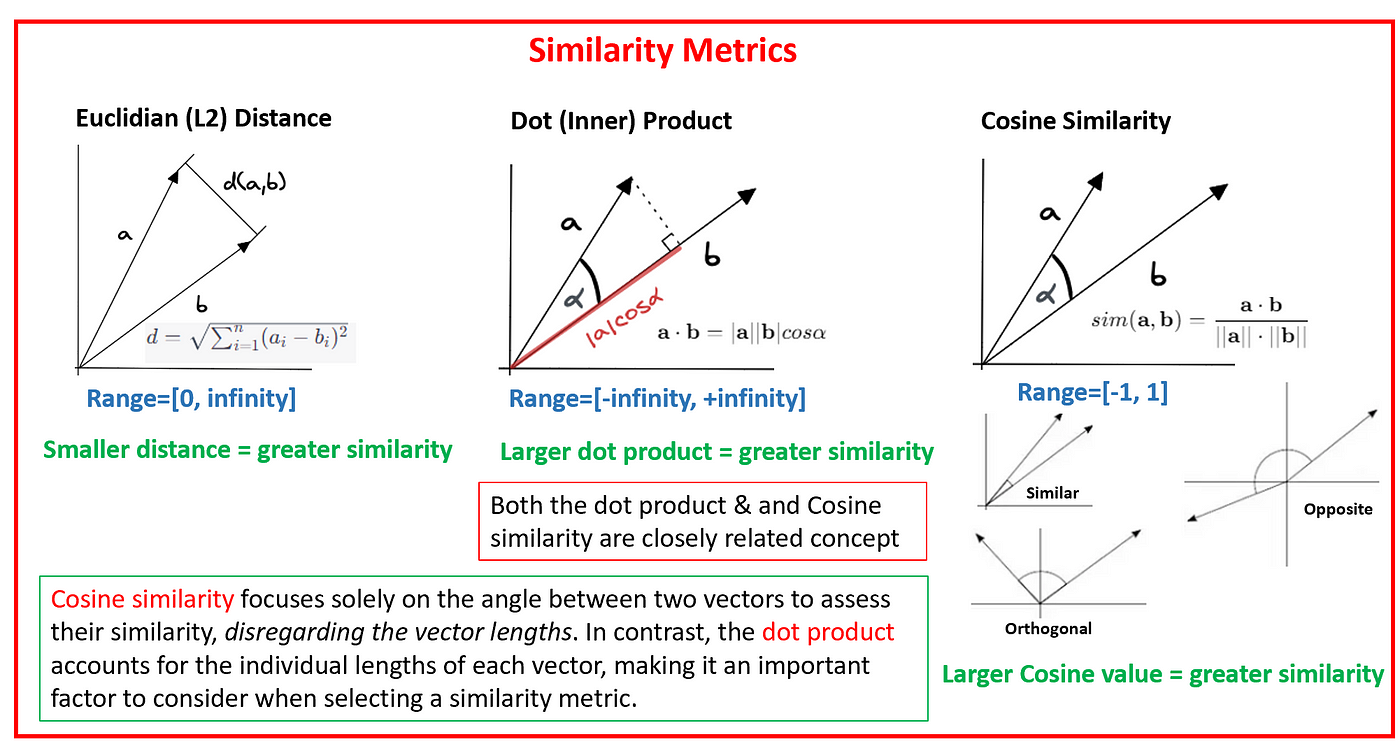
By default, LlamaIndex uses cosine similarity as the distance metric for finding the vectors representing the documents (paragraphs) that are "closest" to the vector representing the user query. This is the central mechanism by which RAG works. LlamaIndex provides an abstraction of this process, hiding the implementation details and allowing rapid development of retrieval systems.
Here is some of the code I wrote for the text-based Q&A bot using LlamaIndex's CustomQueryEngine class to fetch the nodes from which I get the referenced paragraph text, chapter number and paragraph number.
class QAndAQueryEngine(CustomQueryEngine):
"""RAG Completion Query Engine optimized for Q&A"""
retriever: BaseRetriever
response_synthesizer: BaseSynthesizer
llm: OpenAILike
qa_prompt: PromptTemplate
def custom_query(self, query_str: str):
nodes = self.retriever.retrieve(query_str)
metadata = []
# Collect the metadata into a list of dicts so that it can be sent to UI for references
for node in nodes:
metadata_dict = {}
node_metadata = node.node.metadata
metadata_dict["content"] = node.node.text
metadata_dict["chapter"] = int(node_metadata.get("chapter"))
metadata_dict["paragraph"] = int(node_metadata.get("paragraph"))
metadata.append(metadata_dict)
context_str = "\n\n".join([n.node.get_content() for n in nodes])
response = self.llm.chat(
[
ChatMessage(
role="user",
content=q_and_a_prompt.format( # the English and Chinese prompt templates are discussed below
context_str=context_str, query_str=query_str
),
)
]
)
return response, metadata
Indexing the book data
In the indexing process, embedding models are used to translate chunks of text (paragraphs) into high-dimensional vectors that represent the relationships between the tokens in a chunk of text. These are the vectors stored in the "Vector Database" used by LlamaIndex. The chapter number, paragraph number and version (original, Mandarin Chinese and English) of each paragraph are added to the database entry as metadata during the indexing step which runs via a script before starting the FastAPI server. Here's how I indexed the original text and translations with LlamaIndex:
from llama_index.core import Document, VectorStoreIndex
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
en_embedding_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
zh_embedding_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5")
def persist_index():
documents = []
for chapter in range(1, 121):
with open(f"data/book/{chapter}.json", "r") as f:
data = json.load(f)
paragraphs = data["paragraphs"]
for i, p in enumerate(paragraphs):
for lang in ["original", "chinese", "english"]:
document = Document(
text=p[lang],
metadata={
"chapter": str(chapter),
"paragraph": str(i),
"language": lang,
},
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
embed_model=(
en_embedding_model if lang == "english" else zh_embedding_model
),
)
documents.append(document)
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir="storage")
if __name__ == "__main__":
persist_index()
For the embedding models, I used the small BAAI General Embedding models (BGE) for English and Chinese. BAAI is the Beijing Academy of Artificial Intelligence, and I learned about this organization through some of the examples on the LlamaIndex site that use BAAI embeddings. There are multi-lingual embedding models (e.g. BAAI/bge-m3), but setting the embedding model on a per-document basis is possible and in some cases it might be preferable to using a single embedding model for all documents.
Milvus Vector Database
I did most of the development for this project using the in-memory VectorIndexStore provided by LlamaIndex. This worked well, but making any changes to the FastAPI server required the data to be reloaded into memory which took several seconds each time. This can really hinder a good development flow, so I looked into using an external service for the vector database instead of running it in memory.

There are a LOT of options to consider when picking a vector database for a RAG application. Milvus has a highly decoupled architecture, it is fully open source and I had seen it in some examples in the NVIDIA/GenerativeAIExamples repo, so I decided to give it a try.
Using the Milvus docker compose example I was able to set up an external vector database based on etcd and minio. Milvus also provides a Helm chart for running their vector database, this would be helpful if I was going to be running everything in Kubernetes (inference, vector database and application containers).
Other examples of RAG with English questions
One interesting design question I faced was how to support answering questions in both English and Chinese. I initially built the Q&A bot with only Chinese language support. Later, I added a simple helper function to determine if the input text is Chinese:
def is_chinese_text(text: str) -> bool:
"""
This is a simple helper function that is used to determine which prompt to use
depending on the language of the original user query
"""
chinese_count = sum(1 for char in text if '\u4e00' <= char <= '\u9fff')
english_count = sum(1 for char in text if 'a' <= char.lower() <= 'z')
return chinese_count > english_count
This boolean value would then be used in the CustomQueryEngine to use either the Chinese or English PromptTemplate. This allowed the Q&A bot to answer questions in either Chinese or English, and it does not require translating back and forth between Chinese and English. However, this method relies on high-quality translations, so I don't expect English language questions to be answered as accurately as Chinese language questions. Here are the Chinese and English prompts that I used for the text-based Q&A bot, as well as some examples of the Q&A bot answering questions in English. The referenced materials include paragraphs from the English translation.
# Chinese prompt for text-based Q&A bot
q_and_a_prompt = PromptTemplate(
"这是相关的参考资料:\n"
"---------------------\n"
"{context_str}\n" # context_str contains Chinese paragraphs retrieved via RAG query
"---------------------\n"
"根据上述的参考资料,回答下面的问题\n"
"问题:{user_question}\n"
)
# English prompt for text-based Q&A bot
q_and_a_prompt_english = PromptTemplate(
"This is some related reference material:\n"
"---------------------\n"
"{context_str}\n" # context_str contains English paragraphs retrieved via RAG query
"---------------------\n"
"Based on the above material, answer the following question:\n"
"Question: {user_question}\n"
)

Asking random questions like this one is a fun way to explore the many scenes of Dream of the Red Chamber.
RedLM RAG Evaluation
Examinations have long been a cornerstone of Chinese society, shaping individual aspirations, cultural values, and even government structures. This legacy began with the imperial civil service exams, kējǔ (科举), established during the Sui and Tang dynasties, and carries through in Modern China with the gaokao (高考) college entrance examination, both of which have allowed for unprecedented meritocratic routes to power and prestige. Given how widely this novel is studied in China, I was not surprised to find a wealth of examination questions written for students studying Dream of the Red Chamber.
I used a set of 1000 multiple choice questions about Dream of the Red Chamber on examcoo.com to evaluate the effectiveness of the RAG system I built with LlamaIndex. I wrote a script to parse the questions from the website HTML using ChatGPT (parsing HTML is one of my favorite use cases of LLMs!) I filtered the list of 1000 questions down to 877 questions based on the following criteria:
- Four answer choices: some of the questions had more than four answer choices. I filtered questions with more than four answer choices to keep the evaluation simple. This would allow me to assume that random answer choices would have a 25% chance of being correct.
- Only one answer: For some questions the correct answer required selecting multiple answer choices. This would also help keep the evaluation logic simple.

Multiple choice questions from a Dream of the Red Chamber test (examcoo.com)
To run the evaluation I set up two scripts. The first script would prompt the LLM to answer the question without any additional information from the RAG system. This served as a baseline to see how well the LLM could do at answering multiple choice questions about the book. The script simply checks to see if the LLM response contains the letter (A, B, C or D) of the correct answer and keeps track of the number of questions answered correctly.
Another script was used to take the test using large language models with RAG. In this script, the prompt sent to the LLM included relevant paragraphs from the book based on how similar the query is to each paragraph in the book based on the cosine similarity metric mentioned earlier.
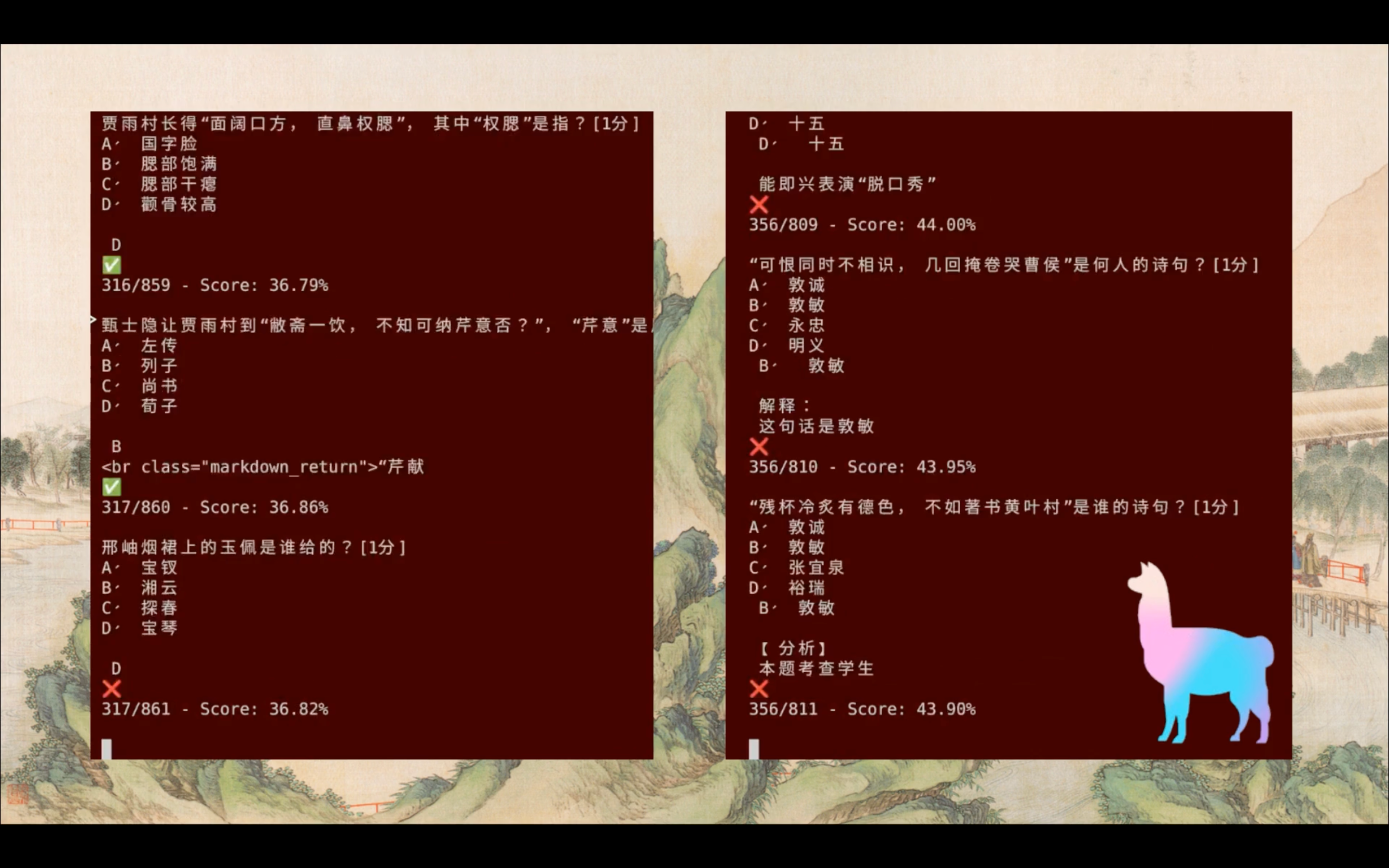
Here are some results and other observations from this experiment:
- LLMs alone scored in the mid 30% range (36%)
- LLMs using retrieval augmented generation with the set of questions score in the mid 40% range (44%)
- I used the completion API rather than the chat API and set the
max_tokensto 16. This was done to ensure that the LLM only gave a short response with a valid answer choice rather than giving a long response with an explanation. - The evaluation took longer for LLM + RAG test because of the time required for making the RAG query and the longer prompt (including both the original multiple-choice question and the referenced paragraphs).
- I used the
01-ai/Yi-1.5-9B-Chatmodel for this test, but I probably should have used the base model rather than the chat model. - Some questions would not be capable of being answered by RAG. For example, some of the questions are about film renditions of the novel. Most of the questions seemed relevant to the content of the book, so I didn't bother to filter out the questions that were not directly related to the book's content.
Here is an example of a question that the LLM test script answered incorrectly and the LLM + RAG test script answered correctly.
秦钟的父亲是如何死的?
A、外感风寒、风毒之症
B、被智能儿气死的
C、生气引发旧病加重
D、生气而诱发中风而死
Translation:
How did Qin Zhong's father die?
A. He caught a cold and developed wind-related illnesses.
B. He was angered to death by Zhineng'er (a character).
C. His old illness worsened due to anger.
D. He had a stroke induced by anger and died.
Here is the paragraphs that the RAG query returned along with the English translation:
Original
荣两处上下内外人等莫不欢天喜地,独有宝玉置若罔闻。你道什么缘故?原来近日水月庵的智能私逃入城,来找秦钟,不意被秦邦业知觉,将智能逐出,将秦钟打了一顿,自己气的老病发了,三五日便呜呼哀哉了。秦钟本自怯弱,又带病未痊,受了笞杖,今见老父气死,悔痛无及,又添了许多病症。因此,宝玉心中怅怅不乐。虽有元春晋封之事,那解得他的愁闷?贾母等如何谢恩,如何回家,亲友如何来庆贺,宁荣两府近日如何热闹,众人如何得意,独他一个皆视有如无,毫不介意。因此,众人嘲他越发呆了。
English
Everyone in the Rong and Ning households, both inside and outside, were extremely happy, except for Baoyu, who seemed indifferent. Do you want to know why? It turns out that recently, the nun Zhineng from Shuiyue Temple secretly ran into the city to find Qin Zhong. Unexpectedly, she was discovered by Qin Zhong's father, Qin Banger. Qin Banger not only drove Zhineng away but also gave Qin Zhong a beating. This made Qin Banger so angry that his old illness relapsed, and within three to five days, he passed away. Qin Zhong had always been weak and hadn't fully recovered from a previous illness. After being beaten and seeing his father die in anger, he was overwhelmed with regret and sorrow, which worsened his condition. As a result, Baoyu felt very melancholic. Although the promotion of Yuan Chun to imperial concubine was a joyful event, it couldn't alleviate the gloom in his heart. While Grandmother Jia and others were busy expressing their gratitude and returning home, and relatives and friends came to celebrate, and the Rong and Ning households were bustling with excitement, Baoyu alone remained completely indifferent to it all. Consequently, everyone started to mock him for becoming more and more absent-minded.
The correct answer for this question is C.
Multi-modal RAG for visual reasoning
Qwen2-VL is a new AI model that was released in late August 2024. Qwen is the name of Alibaba's AI Lab, and it is an abbreviation of the Chinese characters: 千问 ("qian wen", meaning 1000 questions). VL stands for vision-language, meaning that the model is capable of understanding both text and images. I had tested out the previous version of Qwen's vision-language model and was very impressed by how it could accurately describe the contents of images and also answer general questions about images.
Sun Wen was a Qing-era painter who spent 36 years of his life creating a series of 230 paintings capturing scenes from Dream of the Red Chamber. The paintings are incredibly detailed and often contain repeated figures in a temporal sequence. If you asked a Qwen-VL model to describe one of the images, it might return lengthy description that doesn't fully capture the full detail of the scene. It might also be difficult for a language model to "focus" on a portion of the whole image.

This sparked the idea to create a feature where users can click and drag over an image to select part of a painting, then ask questions specifically about the selected portion. I knew that while this could be achieved with tools like HTML canvas, writing it on my own would be quite time-consuming. It took me just a few minutes to write out the prompt, and Claude 3.5 Sonnet generated a perfect prototype of this feature in under a minute. Here's the prompt I used:
I'm going to describe a Vue component and I want you to write it using Vue 3 to the best of your ability.
write a simple single-file vue component using Vue 3 that does the following:
- displays an image
- allows the users to click and drag to select a subsection of the image
- the subsection of the image is saved as a base64-encoded data url to a variable that is displayed below the image
The solution should make use of HTML canvas. When you click down on the image you begin selecting the subsection. You then move the mouse to make your subsection on the image, and when you mouse-up the subsection is selected and the data url is updated. Then the subsection is displayed at the very bottom of the page as a "preview" image using the base 64 image string as the image source.
The selection box should be a dashed red line

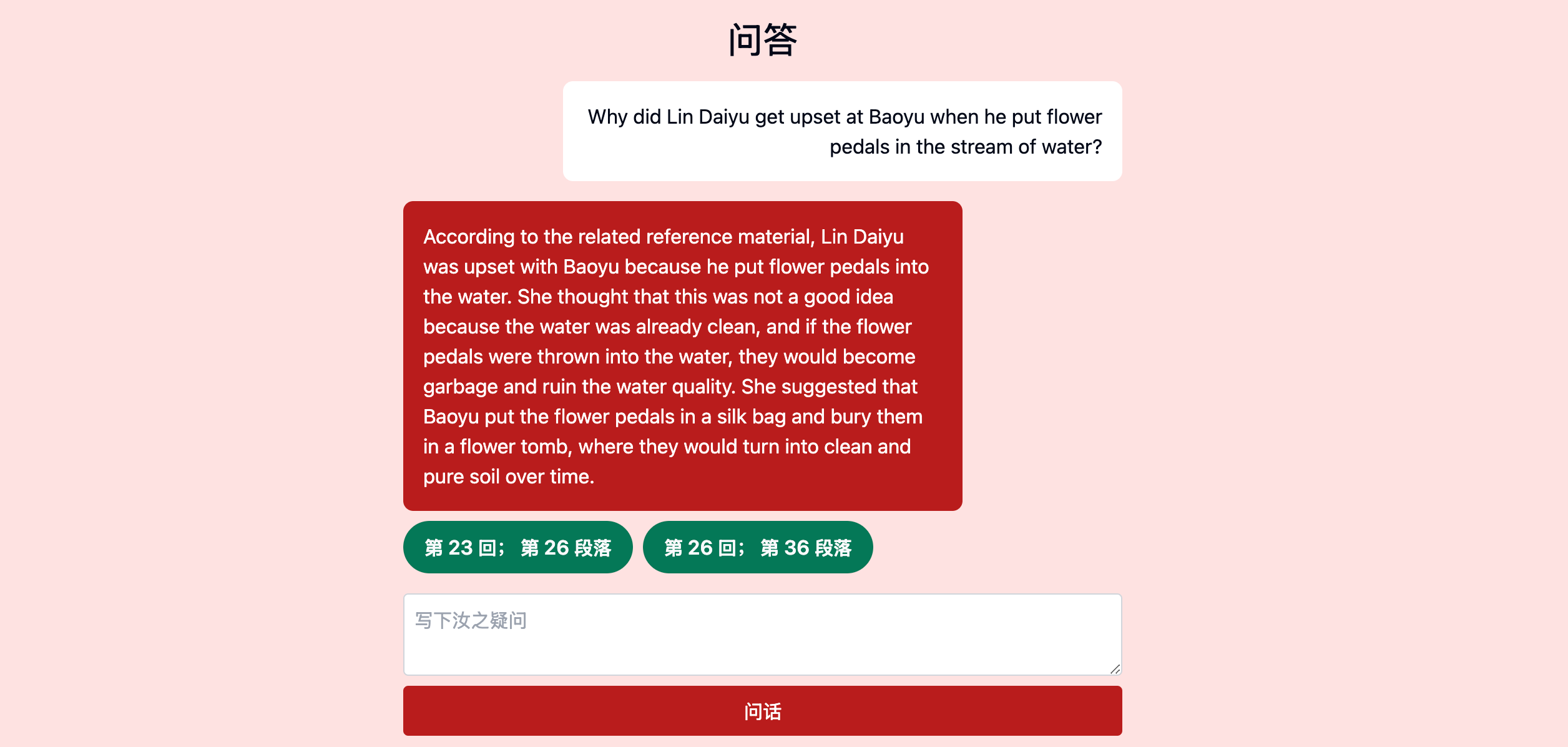
This shows the final result of the UI I built for the image Q&A feature in RedLM. It uses a similar chat layout that the text-based Q&A feature uses, with the addition of the image preview included in the chat log. The user query in this example just says "Please describe the contents of the image". This was the first image that I tested when building the image Q&A feature to see if the correct passage can be referenced based on the description of an image. This pulled the exact passage and the answer provides details about what happened (a fire broke out) where it happened (at the Gourd Temple) and why it happened (a Monk accidentally set an oil pot on fire).
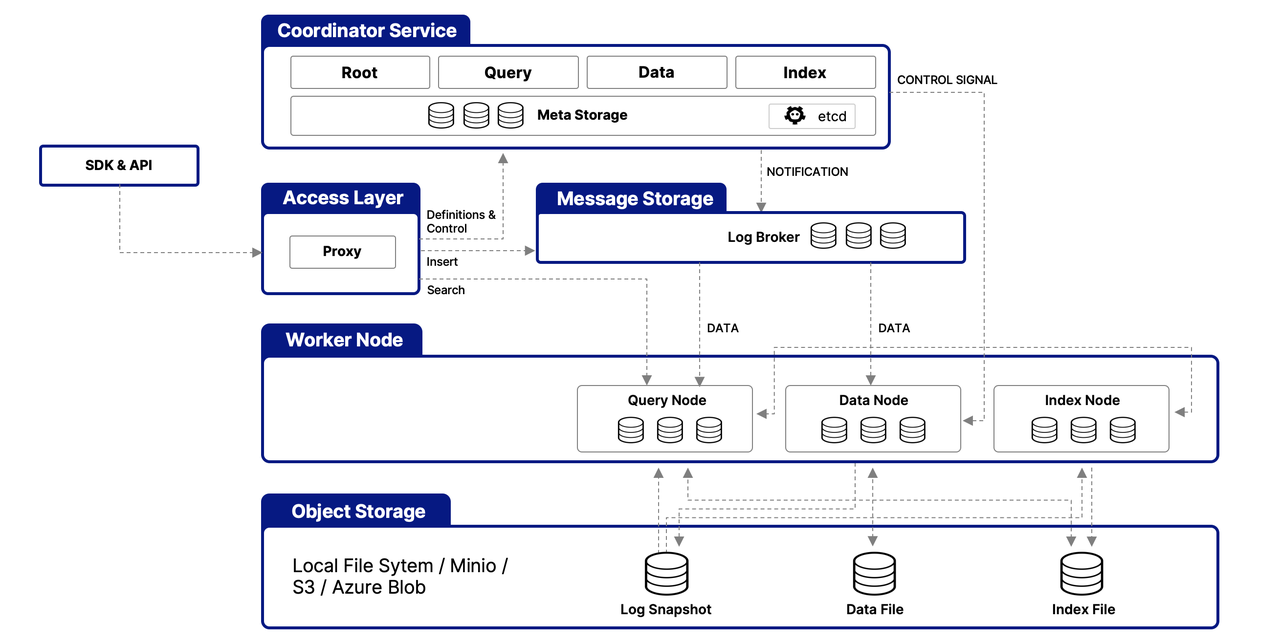
Here is a diagram showing the overall flow of data in the image Q&A feature:
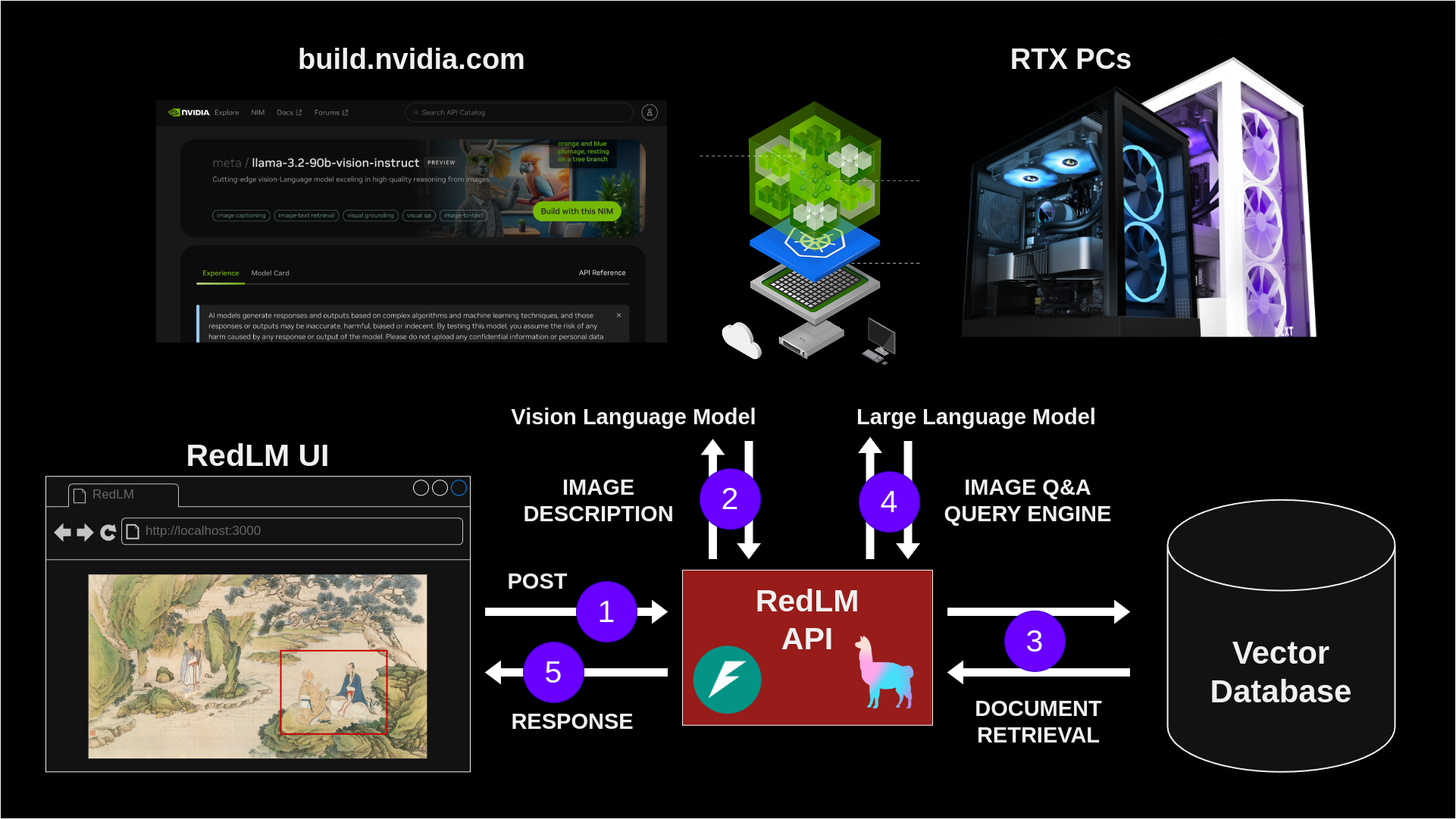
This flow chart shows how the image Q&A feature works.
- The user selects part of an image and writes a question. This data is then sent to the RedLM API as a post request to the
/mm-q-and-aendpoint (multi-modal Q&A). - Vision language models are used to get a description of the image. Depending on the application configuration, this query can use models such as
Qwen/Qwen2-VL-2B-Instructon RTX PCs or using the NVIDIA API Catalog using larger models such asmeta/llama-3.2-90b-vision-instruct. Not all vision language models have the same interface, so I added some logic to handle different model formats. - The image description is used to fetch relevant documents from the Vector Database
- The full prompt with the image description and relevant documents is sent to the LLM. Again, inference for this step is done either with RTX PCs or using models from the
build.nvidia.comAPI catalog. - The response from the LLM is sent back to the browser and is displayed to the user as a chat message.
Here is the prompt I used for the image Q&A feature:
# Chinese prompt for image-based Q&A bot
mm_q_and_a_prompt = PromptTemplate(
"这是书中相关的内容:\n"
"{context_str}\n"
"---------------------\n"
"下面是场景的描述:\n"
"---------------------\n"
"{image_description}\n"
"---------------------\n"
"根据上述的信息,尽量解释上说的场景和书的关系。"
)
# English prompt for image-based Q&A bot
mm_q_and_a_prompt_english = PromptTemplate(
"Here is relevant content from the book:\n"
"{context_str}\n"
"---------------------\n"
"Below is the description of a scene:\n"
"---------------------\n"
"{image_description}\n"
"---------------------\n"
"Based on the information provided above, try to explain the relationship between the described scene and the book content."
)
The prompt engineering for this feature was tricky. I was able to get some awesome results that would give me detailed and accurate responses, and then sometimes the LLM would seem confused about my query and tell me that there was no relationship between the scene description and the book content. Sometimes it would give me an accurate description of the scene, but then proceed to tell me that the book content is not related to the scene at all.
There is another important concept from LlamaIndex that I used to build the image Q&A feature: metadata filtering. Metadata filtering is an important concept in RAG systems because it helps you focus your query on relevant documents in a precise way. A very simple example might be a RAG system that indexes news articles and stores the associated date as metadata. You could allow a user to set a date range for their query and only include articles that match the given date range.
For my image Q&A system, I have a mapping between the paintings and their associated chapters. When I ask a question about a painting, I want to use the description of the image to find similar paragraphs, but only the paragraphs that occur in the painting's associated chapter. What I ended up doing was filtering the entire index before making the query. The alternative would be filtering the returned nodes after making the query, but this would have the possibility of not returning any nodes.
Here's what some of the metadata filtering code looks like:
# main.py
# filter by chapters associated with the queried image
filters = MetadataFilters(
filters=[ExactMatchFilter(key="chapter", value=str(req_data.chapter))]
)
query_engine = get_query_engine_for_multi_modal(filters)
# rag.py
# utility function that returns the query engine use for image Q&A
# the index is filtered to only include nodes associated with the image being queried
def get_query_engine_for_multi_modal(filters):
retriever = index.as_retriever(filters=filters)
synthesizer = get_response_synthesizer(response_mode="compact")
try:
query_engine = QAndAQueryEngine(
retriever=retriever,
response_synthesizer=synthesizer,
llm=model,
qa_prompt=mm_q_and_a_prompt,
)
except Exception as e:
print(e)
return query_engine
This seemed to work well for my use case, but it might not be a best practice, and it might not be efficient at a bigger scale.
Multi-modal Q&A examples
Here are some more examples of results from different types of questions from the multi-modal Q&A bot.
The response to the following query did a good job of combining information gathered from the image description and image from related passages.




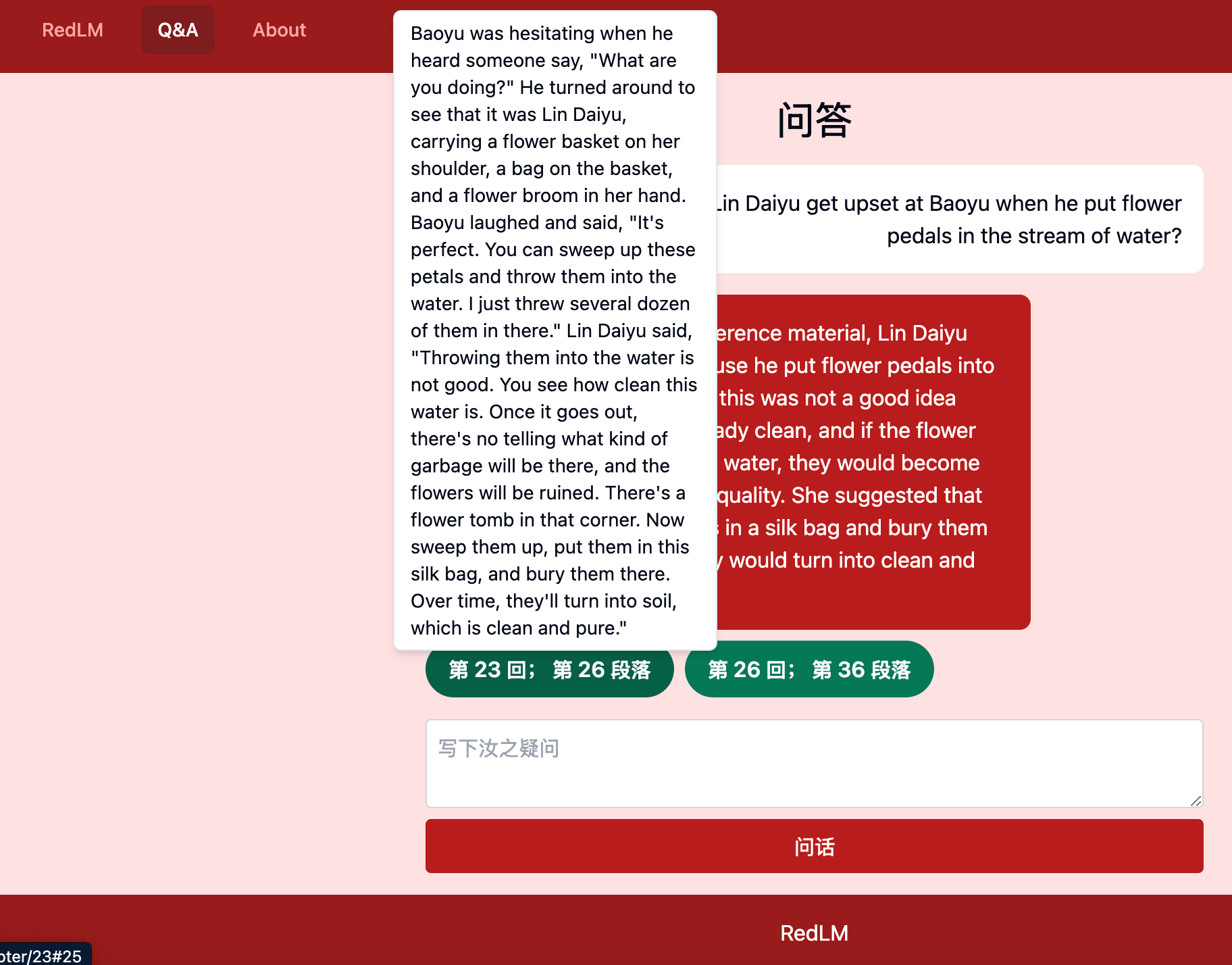
This is one of my favorite examples of the RedLM image Q&A bot in action. The query here in Chinese says: "What are these two people doing"? The answer incorporates a description of what is happening in the story (Jia Baoyu comes across Ou Guan while visiting a temple) and also describes the significance of what is happening (burning paper money as a form of Chinese ancestral worship). But this answer is not perfect and it demonstrates some of the difficulties I had with the prompt engineering for this project. The first part makes a lot of sense:
这段参考资料来自中国古典小说《红楼梦》,讲述了贾宝玉在探访寺庙时发现藕官在河边烧纸钱的情景。藕官是贾府中的一个戏子,她的行为可能代表了对去世亲人的哀悼或祭奥。贾宝玉询问她烧纸的原因,藕官透露了自己有私下的情感问题,并且提到了芳官和蕊官,暗示了她们之间可能存在某种秘密或情感联系。
This reference is from the classical Chinese novel Dream of the Red Chamber, describing a scene where Jia Baoyu discovers Ou Guan burning paper money by the river during his visit to a temple. Ou Guan is a performer in the Jia household, and her actions might represent mourning or honoring deceased loved ones. Jia Baoyu asks her why she is burning the paper, and Ou Guan reveals that she has private emotional issues, mentioning Fang Guan and Rui Guan, hinting that there might be some kind of secret or emotional connection among them.
But the second part seems to contradict the first part of the response:
相比之下,你描述的画作场景与《红楼梦》中的描述不同。画作描绘的是两个人在河边的场景,左边的人跪在地上,似乎在烧东西,右边的人站在旁边,似乎在观察或指导。根据你提供的描述,无法确定画中人物的具体行为,如可能是烧水、煮饭、烧药等。因此,这幅画可能是一幅现实主义作品,描绘了日常生活中的一幕。它可能没有像《红楼梦》中的情节那样深刻的情感或秘密背景,而是单纯地表现了人与人之间的关系和行为。此外,画中的背景、人物的表情和姿态等细节也会对画面的意义产生影响,需要结合具体的画作进行分析。
In contrast, the scene you described in the painting differs from the depiction in Dream of the Red Chamber. The painting shows two people by the river: the person on the left is kneeling on the ground, seemingly burning something, while the person on the right stands nearby, possibly observing or guiding. Based on your description, it's unclear what specific action the figures are engaged in, such as possibly boiling water, cooking, or burning herbs. Therefore, this painting might be a realist work, portraying a moment from everyday life. It may not have the profound emotional or secretive background found in the storyline of Dream of the Red Chamber, instead simply highlighting the relationships and actions between individuals. Additionally, details such as the background, expressions, and postures of the figures in the painting would also influence the scene's meaning and would require analysis based on the specific artwork.
LlamaIndex Developer Experience
Overall, I found the LlamaIndex documentation to be very helpful. Before using LlamaIndex for this project I had used LangChain to build a RAG POC, but I didn't get very good results. I love how the LlamaIndex documentation has a 5-line starter example for building a RAG system:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("Some question about the data should go here")
print(response)
Source: https://docs.llamaindex.ai/en/stable/#getting-started
I was able to expand this simple example to implement the text and image Q&A bots for RedLM fairly easily. The application I built is somewhat similar to the Full-Stack Web App with LLamaIndex included in their documentation.
Most of the early development I did on this project used the CustomQueryEngine. Later I tried using LlamaIndex Workflows to better organize the logic in the text and image-based Q&A bots. The same workflow RAGWorkflow is used to handle requests for both the text and image Q&A bot queries. Workflows also work seamlessly with asynchronous Python frameworks like FastAPI. Here's the API endpoint for the multimodal image-Q&A bot using a LlamaIndex Workflow:
@app.post("/mm-q-and-a")
async def mm_q_and_a_workflow(req_data: MultiModalRequest):
"""
This function handles Multimodal Q&A bot requests using a LlamaIndex workflow
"""
try:
# parse data from request object
image_b64 = req_data.image
prompt = req_data.prompt
chapter = req_data.chapter
# setup LlamaIndex Workflow and run it with data from request
w = RAGWorkflow(timeout=None)
result = await w.run(query=prompt, image_data=image_b64, chapter_number=chapter)
# return response
return QAQueryResponse(
response=result["response"].message.content,
metadata=result["metadata"],
image_desc=result["image_description"],
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
Using LlamaIndex Workflows also helped me add additional logic in a maintainable and standardized way. For example, I expanded the RAGWorkflow logic to include LLM-based re-ranking in order to ensure retrieval of the most relevant documents for my chatbot queries. This technique increases request latency, but this is an acceptable tradeoff for an application like RedLM.
LLMRerank
LLM Rerank was an interesting technique to try out, and LlamaIndex provides LLMRerank to make the implementation as simple as possible. Here's my understanding of how it works:
- LLMRerank searches in the vector database for a high number of documents that are relevant to your query. This is done using cosine similarity, which essentially compares the vectors that represent the query and the documents.
- Next, LLMRerank goes through a process of assigning a numerical score to each document to score relevancy. It does this via a special prompt that requests relevancy score for each document in batches.
- For example, I configured
LLMRerankto initially fetch 4 documents from the vector database based on cosine similarity. Then in batches of 2, relevancy scores are assigned. Finally, the top 2 most relevant documents based on the LLM-given scores are used to make the RAG query. - Adding LLMRerank can require a number of additional queries based on how you configure the batch size and the number of documents you would like to compare. This will increase latency for your application and use more resources to make the extra calls.
Here's an example LLM query that LLMRerank uses to do assign scores:
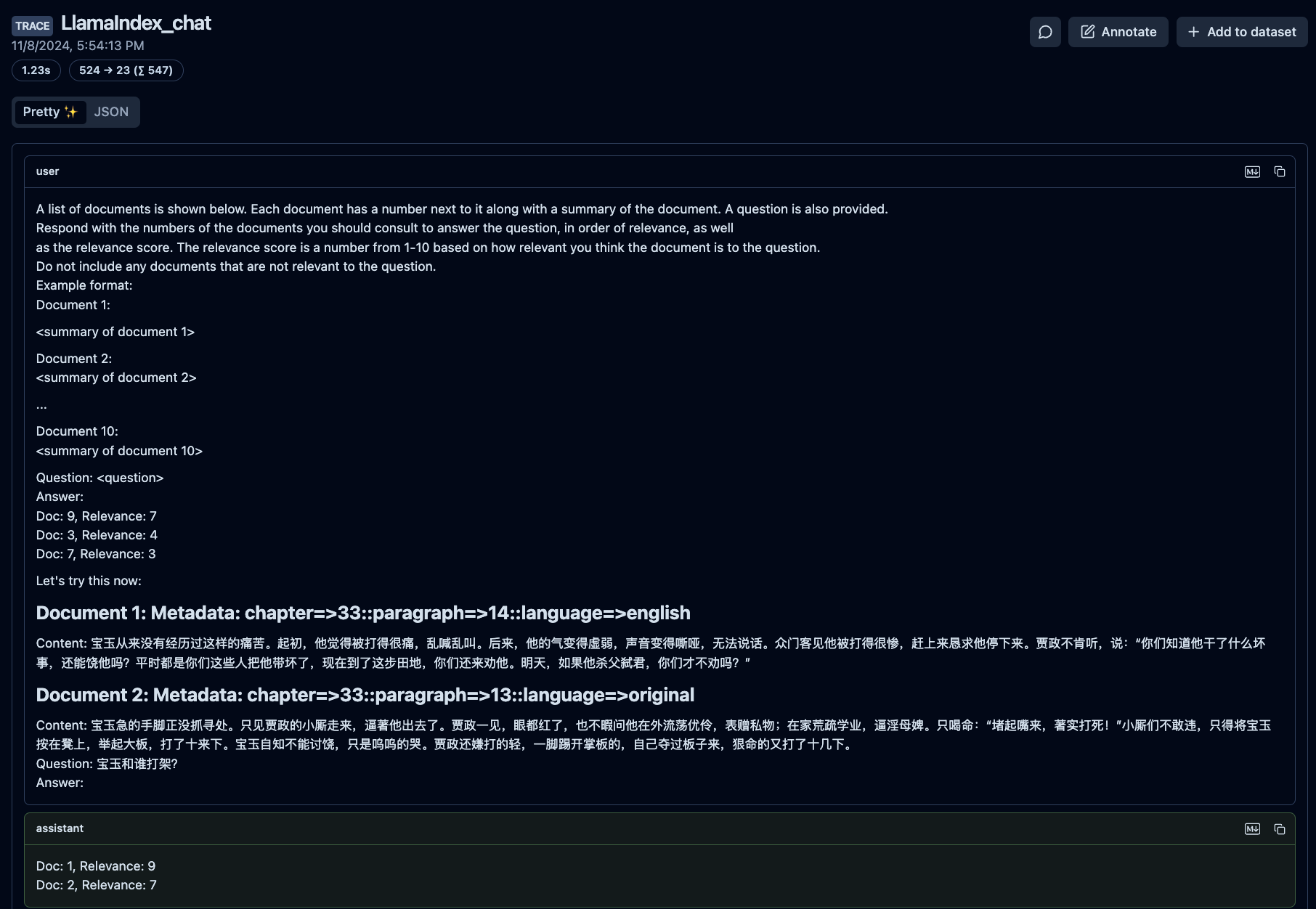
Here are logs from my application showing what happens inside the workflow.
Application for text-base Q&A query:
INFO: 💬Request for Q&A chatbot: query='宝玉和谁打架?'
INFO: 🔀Routing Workflow to next step
INFO: 💬Routing to QueryEvent
INFO: 🧮Query the vector database with: 宝玉和谁打架?
INFO: 🖥️Using in-memory embedding database
INFO: ⏳Loading index from storage directory...
INFO: ✅Finished loading index.
INFO: 📐Retrieved 4 nodes.
INFO: 🔀Doing LLMRerank
INFO: ℹ️ Chat Model Info:
INFO: 🟩Using NVIDIA Cloud API for inference
INFO: 🔘Chat Model: baichuan-inc/baichuan2-13b-chat
INFO: 🔢Reranked nodes to 2
INFO: 🤖Doing inference step
INFO: ⚙️ Getting query engine..
INFO: 🔎Getting response from custom query engine
INFO: 💬Text-based Q&A query
INFO: 🀄Text is Chinese
INFO: Using nodes from workflow...
INFO: 🔏Formatting prompt
INFO: Prompt is
这是相关的参考资料:
---------------------
宝玉从来没有经历过这样的痛苦。起初,他觉得被打得很痛,乱喊乱叫。后来,他的气变得虚弱,声音变得嘶哑,无法说话。众门客见他被打得很惨,赶上来恳求他停下来。贾政不肯听,说:"你们知道他干了什么坏事,还能饶他吗?平时都是你们这些人把他带坏了,现在到了这步田地,你们还来劝他。明天,如果他杀父弑君,你们才不劝吗?"
宝玉从来没有经历过这样的痛苦。起初,他觉得打得很痛,乱喊乱叫。后来,他的气变得虚弱,声音变得嘶哑,无法说话。众门客见他被打得很惨,赶上来恳求他停下来。贾政不肯听,说:"你们知道他干了什么坏事,还能饶他吗?平时都是你们这些人把他带坏了,现在到了这步田地,你们还来劝他。明天,如果他杀父弑君,你们才不劝吗?"
---------------------
根据上述的参考资料,回答下面的问题
问题:宝玉和谁打架?
Response...
宝玉和贾政打架。
My question here was basically asking "Who gets in a fight with Baoyu?" The reply says that his father, Jiazheng, gets in a fight with Baoyu, and the documents that are used here very similar, differing by only one character. One of the documents is supposed to be and English translation, but in fact there was a failure in the translation for this paragraph and it "translated" the Chinese by simply repeating it. A translation of this paragraph using GPT 4o describes a tense scene between protagonist Jia Baoyu and his father Jia Zheng:
Baoyu had never endured such agony before. At first, he felt the pain intensely and cried out loudly. Later, his breath grew weak, his voice turned hoarse, and he couldn't speak. The attendants, seeing how severely he was being beaten, rushed forward to plead for him to stop. Jia Zheng refused to listen, saying, "Do you know the misdeeds he's committed, and still you want to spare him? Normally, it's you people who lead him astray, and now that it's come to this, you still try to persuade him? Tomorrow, if he were to commit patricide or treason, would you still not advise him?"
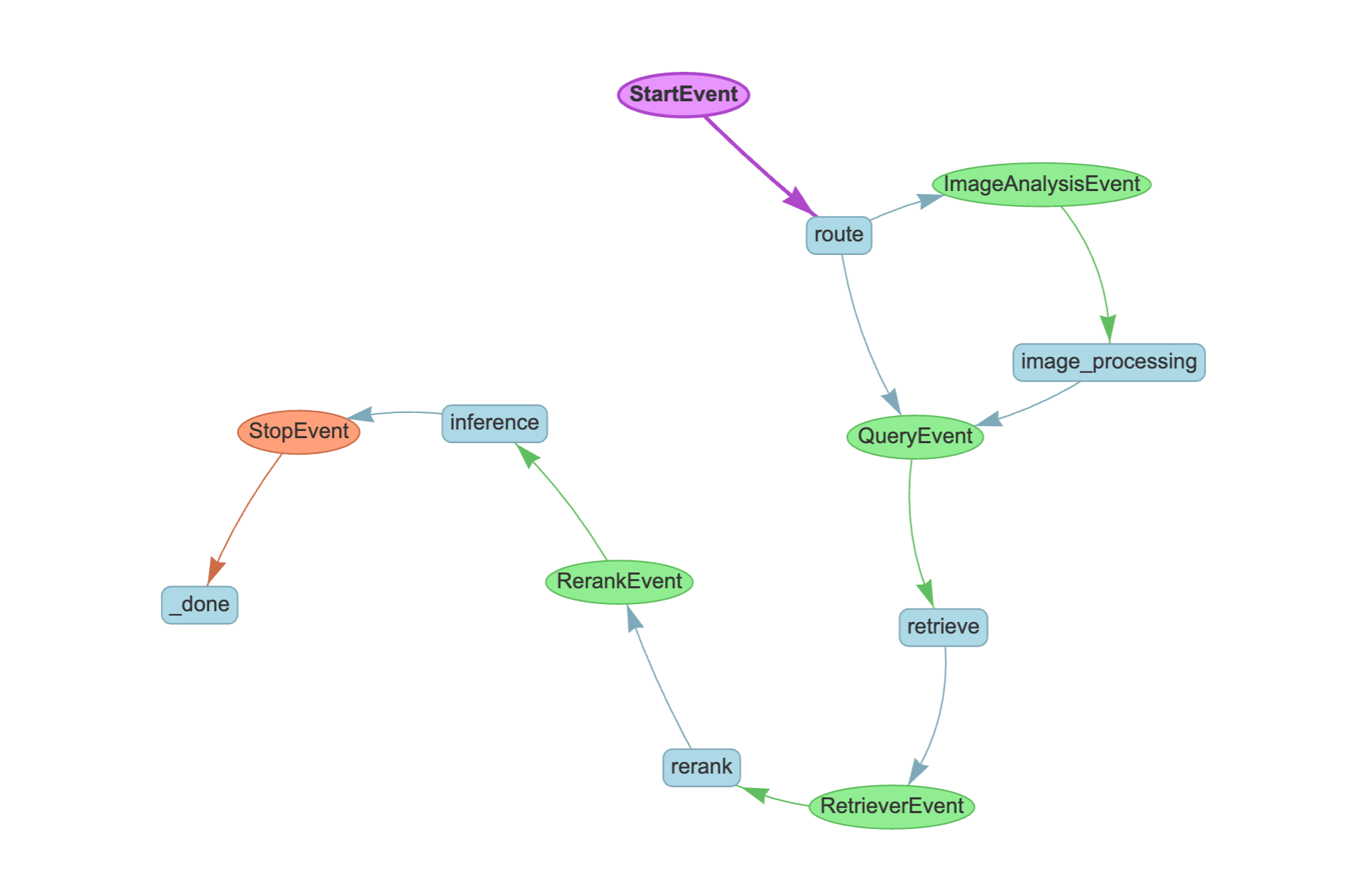
Another benefit of LlamaIndex workflows is the ability to create visualizations of each step, the branches between them and the overall flow of events and the functions that accept/emit them as arguments/return values. It took a little bit of getting used to the patterns used to create workflows, but the documentation for Workflows provided a good starting point that I could adapt for my application. Here's a visualization of the LlamaIndex Workflow that is used by the image and text-based Q&A bots:
Observability and Tracing with Langfuse
It is never too soon to add observability and tracing to a RAG application! I learned this the hard way after doing some refactoring of prompts and CustomQueryEngine logic.
Langfuse is an open source LLM engineering platform to help teams collaboratively debug, analyze and iterate on their LLM Applications. With the Langfuse integration, you can seamlessly track and monitor performance, traces, and metrics of your LlamaIndex application. Detailed traces of the LlamaIndex context augmentation and the LLM querying processes are captured and can be inspected directly in the Langfuse UI.
LlamaIndex supports lots of different observability and tracing solutions. I tried using Langfuse (YC W23) which is an open-source option that has a self hosted option.
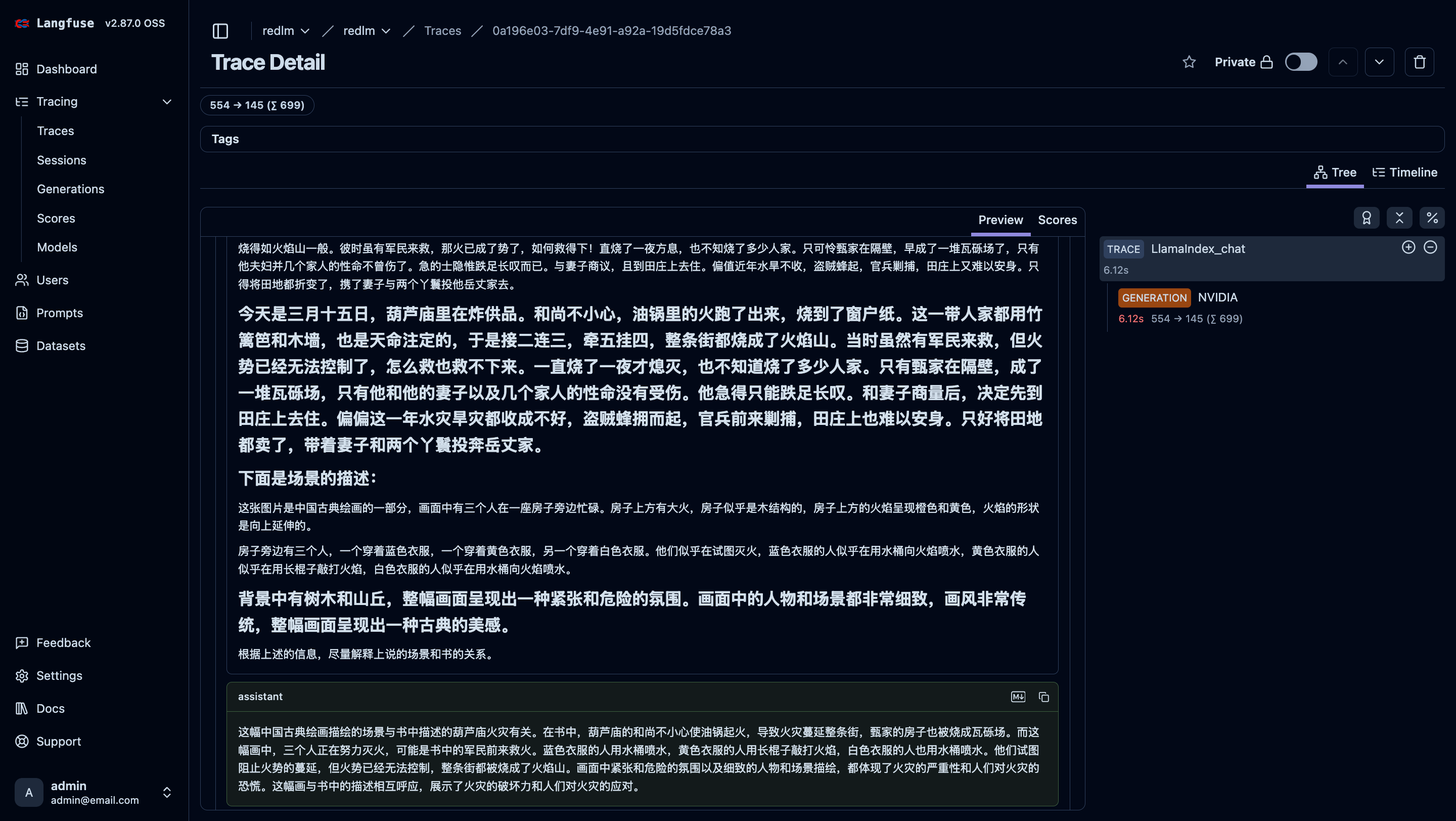
Langfuse came in handy when debugging the prompts for the image-based Q&A bot. This screenshot shows a trace of a multi-modal Q&A bot query about the fire at the Gourd Temple that occurs in Chapter 1 of the book.
NVIDIA inference stack (TensorRT-LLM and build.nvidia.com)
The LLM API for TensorRT-LLM is a very nice developer experience compared with my earlier attempts with manually building inference engines. The roadmap for TensorRT-LLM looks promising, I'm looking forward to support for an OpenAI Compatible API and more models. NVIDIA NIMs using TensorRT-LLM are an easy way to run models as OpenAI compatible API servers, but the selection of models is still pretty limited. vLLM provides a strong alternative with a wide range of support models. NVIDIA NIMs for LLMs build on vLLM libraries and the TensorRT-LLM library, so it is helpful to have an understanding of both of these libraries to stay on the bleeding edge of performant inference engines.
The NVIDIA API catalog is a great way to test a variety of different models, especially large models that cannot fit into consumer hardware like RTX PCs or high-end MacBooks. I got to try out the new meta/llama-3.2-90b-vision-instruct model in my project by simply changing a value in my .env file, this is a great developer experience!
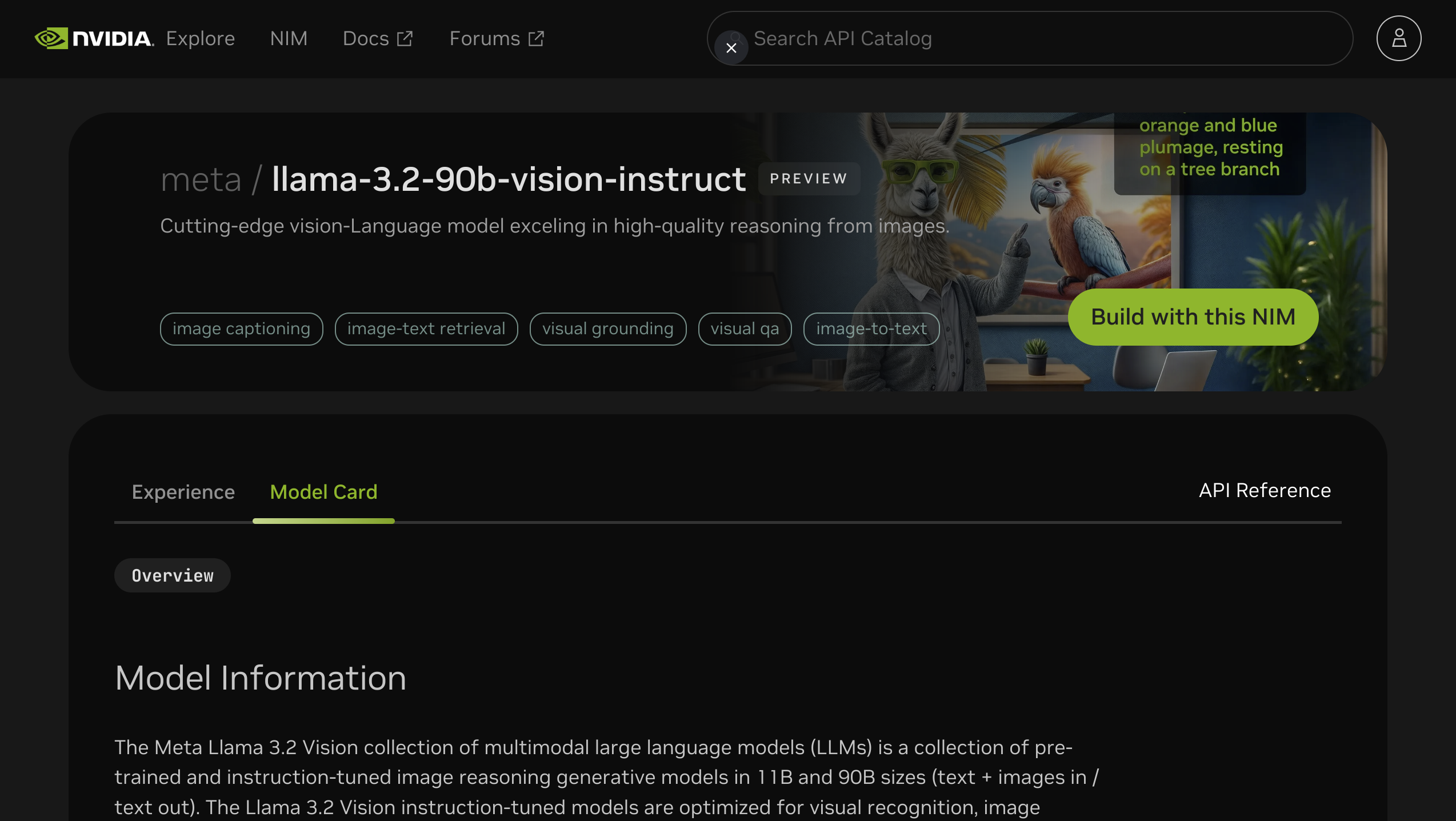
The NVIDIA API catalog doesn't have every model in every size, however. For example, it has the qwen/qwen2-7b-instruct model, but doesn't have the qwen/qwen2-7b-instruct model. Also, only some of the models are labeled as "Run Anywhere"; a lot of the models say "Self-Hosted API Coming Soon" meaning that they can't be downloaded an run locally as a container. To get around this, I ran inferences services locally using both vLLM's vllm/vllm-openai container and my own container running Qwen and other services.
My local inference stack (RTX)

Two of the RTX PCs in my home network: a1 and a3. a1 was the first PC I built by myself and was the beginning of my GeForce journey. Luckily I built it with an over-provisioned PSU, so it can use a 4090 FE card! The front panel doesn't fit, however.
One limitation of the NVIDIA API catalog is the number of free credits given for a trial account. Using 1 credit per API call, I would use up the 1000 credits very quickly when running scripts like translation or the RAG evaluation. The same would be true with rate limits of the OpenAI API. That's why running LLMs locally is still an important part of the development cycle for this type of project.
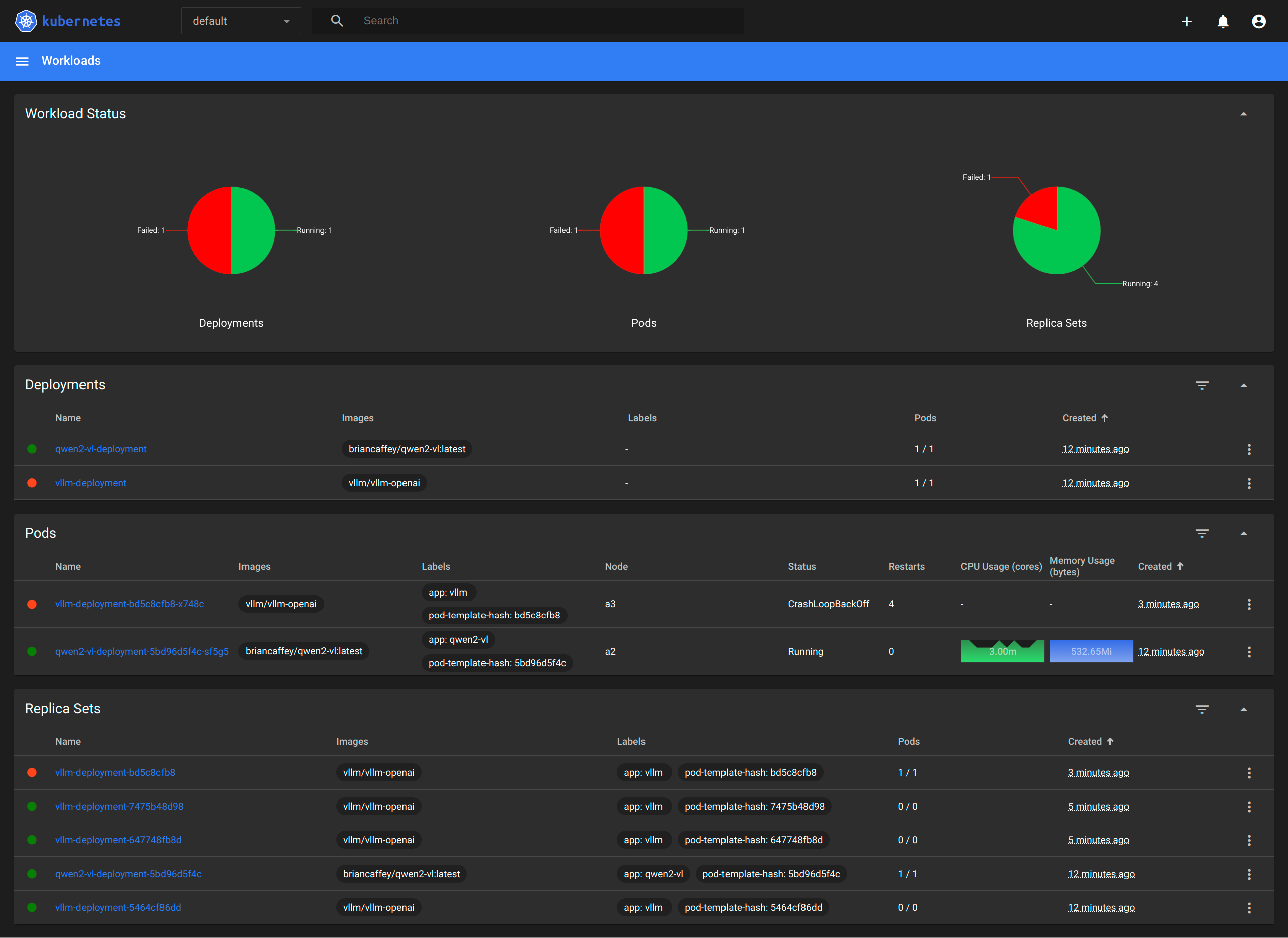
This project primarily uses two models: a large language model and a vision language models. Running the Yi-1.5-9B-Chat model from 01.AI takes up just about all of the GPU memory on one of my RTX 4090 PCs, so I had to run the vision model on another PC. In a previous project, I used Kubernetes to manage lots of different inference services: LLMs, ComfyUI, ChatTTS and MusicGen for making AI videos and I found it to a nice way to manage different containerized inference services.
brian@a3:~$ microk8s kubectl get no -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
a1 Ready <none> 4d4h v1.30.5 192.168.5.182 <none> Ubuntu 24.04.1 LTS 6.8.0-45-generic containerd://1.6.28
a2 Ready <none> 11d v1.30.5 192.168.5.96 <none> Ubuntu 24.04.1 LTS 6.8.0-45-generic containerd://1.6.28
a3 Ready <none> 11d v1.30.5 192.168.5.173 <none> Ubuntu 24.04.1 LTS 6.8.0-45-generic containerd://1.6.28
In the RedLM GitHub repo I included kubernetes manifests that show how to run the LLM and VLM across two different computers. I used Kustomize as a way to replace dynamic values in the YAML files for different resources. The kubernetes set up is experimental; the LLM and VLM can more reliably be run with docker run commands.
I had a lot of driver issues when trying to get kubernetes to run the vLLM container for the Yi LLM. I struggled with the following error message when trying to run the vllm LLM service:
RuntimeError: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW
I tried uninstalling and reinstalling different versions of the NVIDIA drivers and CUDA but kept seeing the same message once the server would try to start up in the vLLM container logs. Rebooting my PC didn't work either. I saw a recommendation to turn off secure boot in BIOS. I didn't turn it on, but having nothing else to try I went into the BIOS settings and found that there were some keys configured in the secure boot section. After I deleted these keys and reboot, everything seemed to work normally. I'm not sure why my PC was in secure boot mode, though!
AI Models used in this project
I selected LLMs that run efficiently on RTX PCs, are available in the NVIDIA API catalog, and offer strong bilingual support in Chinese and English, ensuring compatibility, performance, and linguistic flexibility. Here are the models that I ended up using with RedLM:
01-ai/Yi-1.5-9B-Chat and nvidia/yi-large
I used 01-ai/Yi-1.5-9B-Chat for most of the LLM inference while developing RedLM on my RTX PCs. This model family performs well on both Chinese and English benchmarks, and has a variety of model sizes. I was able to try using the 01-ai/yi-large model from the NVIDIA API catalog when using remote cloud inference. I used the vllm/vllm-openai:latest container to run this locally.
There are also vision models in the Yi series, such as 01-ai/Yi-VL-34B, but I didn't use these models in my project.
baichuan-inc/baichuan2-13b-chat
This model is available in the NVIDIA API catalog, and it was the main model I used when testing remote inference. It performs well in a variety of tasks and scores highly on the the Chinese Massive Multitask Language Understanding (CMMLU) benchmark.
Qwen/Qwen2-7B
This model was used for summary and translation of the source text. It was supported by the TensorRT-LLM LLM API and I didn't have any issues building the TensorRT-LLM model with it on the EC2 instance used to do the completion inference for translations.
Qwen/Qwen2-VL-2B-Instruct
This was the vision language model (VLM) that I used locally when developing on RTX. I was impressed at how well it could describe images given the small parameter count of the model (2 billion parameters). The small size of this model made it easy to run in my RTX PC cluster.
There is an open GitHub issue for TensorRT-LLM support for Qwen2-VL at the time of writing.
I wrote a simple FastAPI server using the Hugging Face transformers library based on example code from this model's documentation (see services/qwen2-vl in the RedLM GitHub repo for more details). I packaged this service into a container in order to run it in my local kubernetes cluster along with other inference services.
meta/llama-3.2-90b-vision-instruct
This model came out while I was working on the project, and I decided to use it instead of the adept/fuyu-8b model that was previously one of the only vision language models in the NVIDIA API catalog. The meta/llama-3.2-90b-vision-instruct model has strong Chinese language skills, so it was a good model to use when doing remote inference for the image Q&A bot.
nvidia/NVLM-D-72B
I didn't use this model in my project, but it came out recently and looks awesome! Hopefully this model will be available on the NVIDIA API catalog soon. It is trained on the Qwen2-72B-Instruct text-only model, so it likely also has very strong support for Chinese language.
Today (September 17th, 2024), we introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2). Remarkably, NVLM 1.0 shows improved text-only performance over its LLM backbone after multimodal training.
The success of Black Myth: Wukong
I originally got the idea to build this project after seeing the release of Black Myth: Wukong. This game is a blockbuster success from a Chinese developer that tells the story of the Monkey King's adventure in the Journey West universe. Journey West (西游记) is another one of the "Four Great Works" of Chinese literature. It tells the story of the legendary pilgrimage of the monk Xuanzang (also known as Tang Sanzang) to India, accompanied by his three disciples-Sun Wukong (the Monkey King), Zhu Bajie (Pigsy), and Sha Wujing (Sandy). The group travels from China to India to retrieve sacred Buddhist scriptures, facing numerous challenges, demons, and supernatural beings along the way.
The novel blends elements of adventure, mythology, and spiritual allegory, with Sun Wukong's mischievous nature and extraordinary powers adding humor and excitement. Through their journey, the characters grow and overcome personal flaws, ultimately achieving enlightenment and spiritual success. The video game adaptation has set world records for numbers of concurrent players, and it has rewritten the narrative around what is possible with single-player, offline games in the gaming industry.

Three renditions of Journey West: Songokū (The Monkey King) polychrome woodblock (surimono) (1824) by Yashima Gakutei (1786-1868), Black Myth: Wukong video game by Game Science (2024), Journey to the West TV series by CCTV (1982-2000)
RedLM video
RedLM: An AI-powered application for Redology
— Brian Caffey (@briancaffey) November 9, 2024
🪨✨📜🔎🖼️
A project for the #NVIDIADevContest #LlamaIndex @NVIDIAAIDev @llama_index pic.twitter.com/BUaBBbsLGl
I created the video for this project using Blender.The Blender sequencer editor is a great non-linear video editing tool for simple video projects like this one. I used the following formula to create the project video for RedLM:
- Background music: I used the AI music generation service called Suno with the prompt "mystical strange traditional Chinese music from the Qing Dynasty". Here's the link to my Suno playlist called "Qing Dynasty Music" where you can find the original song and some other good songs that I generated using this prompt. My Qing Dynasty Music Playlist on Suno
- Outline: For this project, the main sections are the introduction, then explaining each part with a short demo: translation, text-based Q&A, evaluation for text-based Q&A, image-based Q&A, and finally a short outro. I wrote an outline and then ChatGPT helped with filling out the content.
- Narration: I used ElevenLabs to narrate the main part of the video using a clone of my voice using the ElevenLabs Voice Lab. The Chinese voices were generated on my computer with an open-source text-to-speech model called ChatTTS.
- Images and videos: I gathered images and screen captures of different parts of the project including code snippets, paintings of the book, flow diagrams and screen recordings of the application.
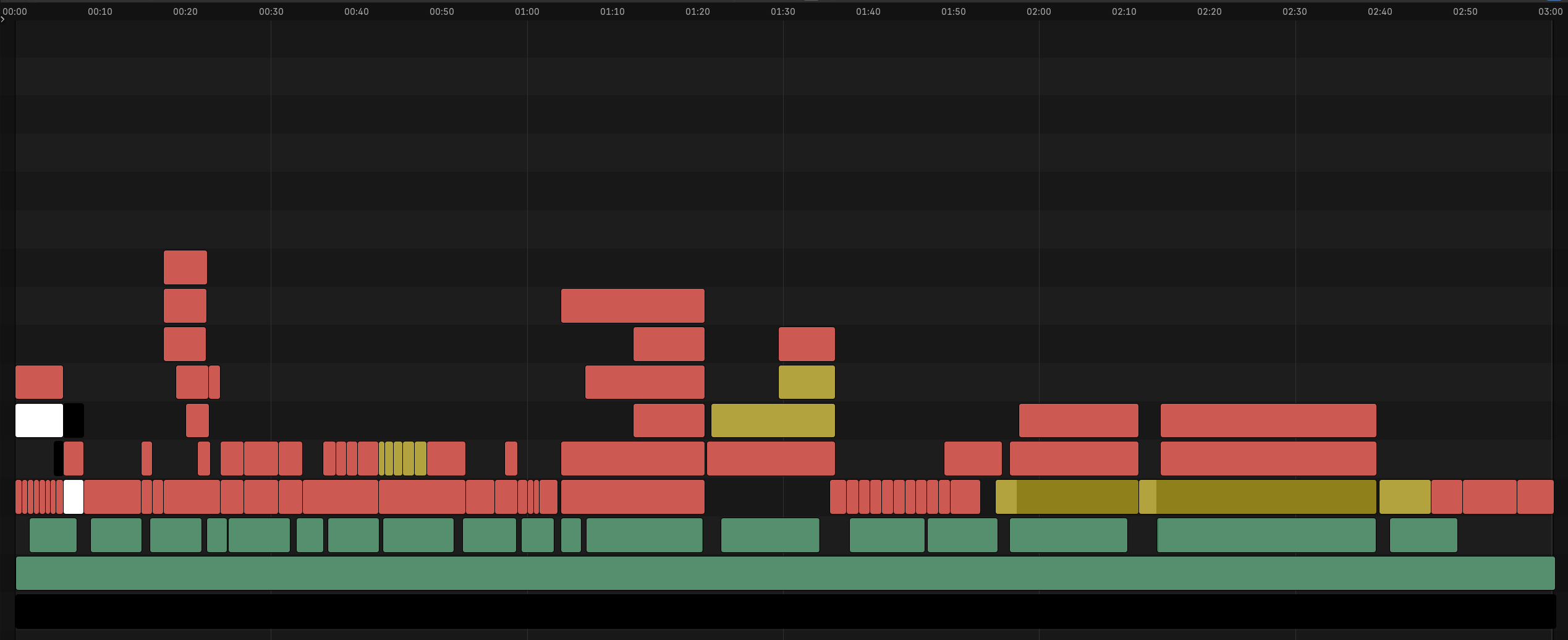
The video is composed of different "strips". The green strips represent the music and voice clips. Red strips are images and yellow strips are videos. Here is what the final cut of the video looks like in Blender's Sequencer view:
ChatTTS is one of the most impressive open-source models I have seen for generating conversational speech with prosodic elements (pausing, laughter, etc.) It is developed by a Chinese company called 2noise. Earlier this year I made a small contribution to this project with an API example using FastAPI to show how to run a standalone API using the model. Another example in this project provides a comprehensive example application built with gradio:
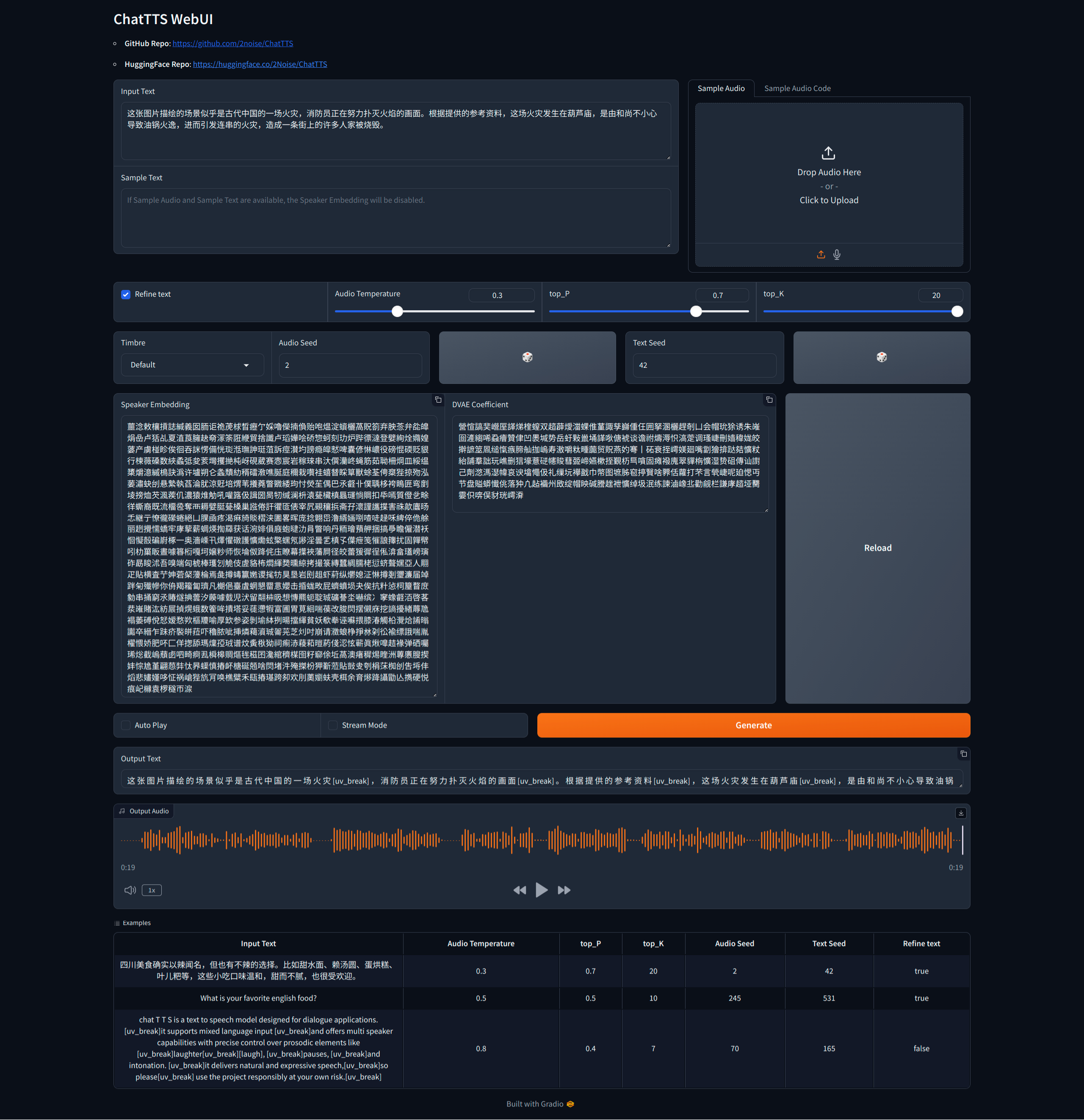
I was planning on streaming the narration audio for Q&A answers using my ChatTTS API service, but I didn't get around to doing this. Instead, I just used the Gradio application to generate the Chinese narration for Q&A and image Q&A examples included in the video.
RedLM Deep Dive video with NotebookLM
NotebookLM is a new application from Google that is a truly magical application of retrieval augmented generation.
NotebookLM is a research and note-taking online tool developed by Google Labs that uses artificial intelligence, specifically Google Gemini, to assist users in interacting with their documents. It can generate summaries, explanations, and answers based on content uploaded by users.
I used NotebookLM to generate a "Deep Dive" podcast episode using only this article. I was pretty impressed with what it was able to produce, and I wanted to share it as part of this project, so I used Blender and some Python scripts to put together a simple and engaging visualization.
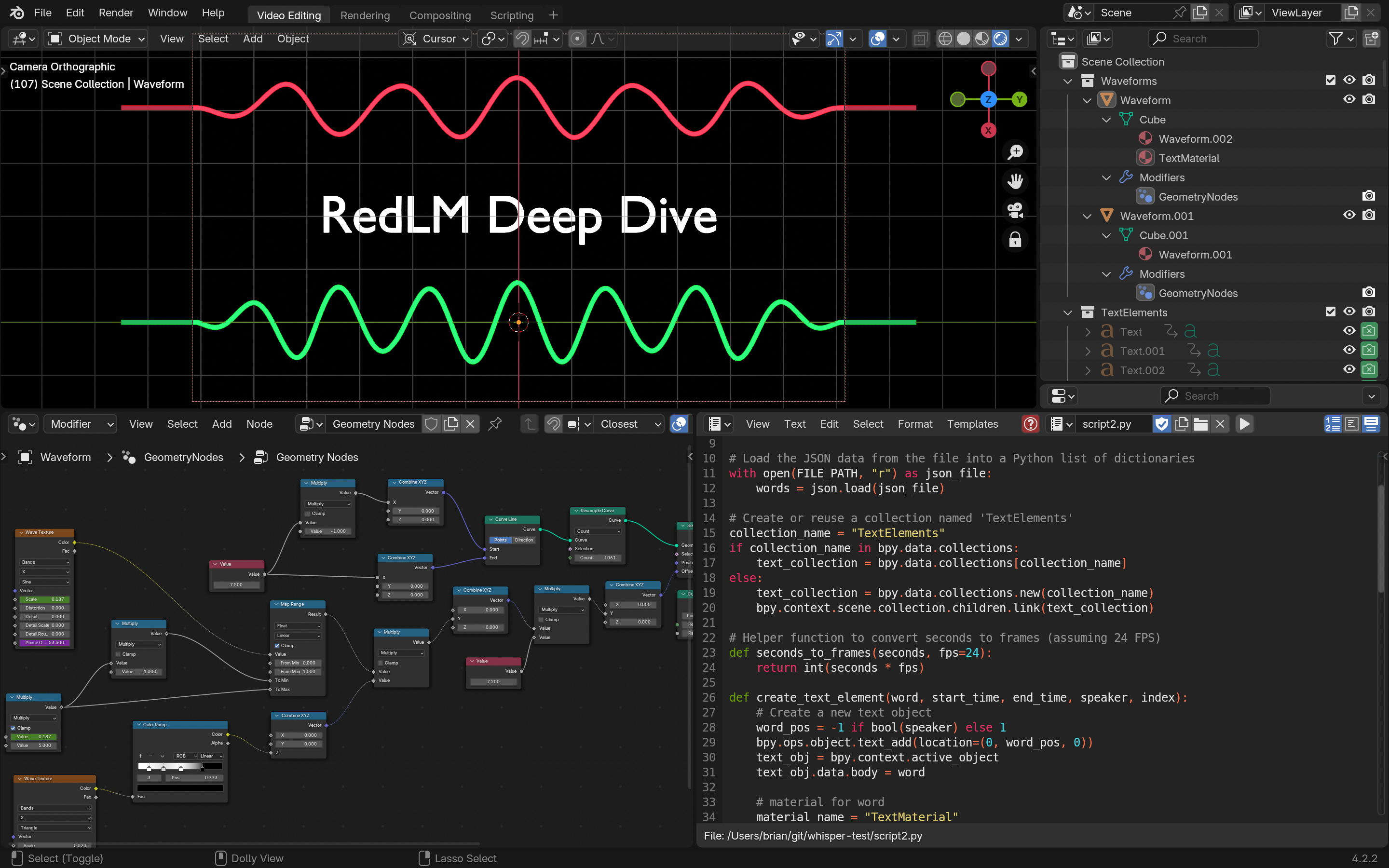
The openai/whisper-base model was used to get time stamps for the start and end of each spoken word using Automated Speech Recognition (ASR). A speaker segmentation library called pyannote/audio was used to perform speaker diarization. This is an interesting algorithm that can segment any number of distinct speakers in an audio recording using a series of models and a discrete-time stochastic process known as the Chinese restaurant process. This gave a list of time intervals with a speaker ID, and I used the intervals to attribute a speaker ID to each word. Then I segmented the audio into two files using this data and used the files to generate audio waveforms using Blender's geometry nodes. Another script was used to animate each word of as it is spoken in one of two positions for each speaker.
Final thoughts
I'm glad to have had the opportunity to join three NVIDIA developer contests this year. I like the idea of a "developer contest" that takes place over several weeks compared to hackathons that take place over just a few days. Having more time allows you to learn about a new tool or framework at a deeper level and think about how to apply it in a creative project.

I also like how this contest is not team based. Working on this project I was able to do a lot of high-level thinking, write out features as detailed prompts, and then delegate the code writing to LLMs as if I was giving tasks to teammates.
NVIDIA's contests are "global developer contests", but the contests so far are not open to developers in India and China. This is probably due to local rules and regulations governing how contests, prizes and taxes work. It is too bad; I would love to see what types of applications would come from participants in these countries. Also, there are also a lot of really interesting developments happening in the LLM space in both China and India!
The LLMs I used in this project were developed by leading Chinese AI companies, and they are competitive with LLMs from Western countries on LLM benchmarks despite having access to fewer GPU resources. Qwen recently released a new model called Qwen2.5-Coder-32B that has outperfomed leading models at coding tasks.

Kaifu Lee mentioned in a Bloomberg interview that the scarcity of GPU resources in China will force Chinese engineers to innovate in new ways to gain an advantage. One example of this we saw recently was when Chinese hardware hackers doubled the usable memory of the RTX 4090D (a variant of the RTX 4090 card with lower processing power to comply with US export regulations for China - the D stands for Dragon, apparently!)

NVIDIA recently concluded its AI Summit in Mumbai. I was intrigued by the fact that Hindi has unique challenges that have have limited the development of Hindi LLMs compared to the development of English and Chinese LLMs. In a conversation with Jensen Huang, Indian industrial titan and CEO of Reliance Industries Mukesh Ambani spoke about his aspirations and ambition for India to overcome these challenges and develop a Hindi LLM. In a viral moment Mukesh Ambani shared that through devotion to attaining knowledge through the Hindu Goddess of knowledge Sarawati, India will be met by the Goddess of prosperity, Lakshmi.
NVIDIA recently released a small language model for Hindi at the AI Summit in Mumbai called Nemotron-4-Mini-Hindi-4B. Hindi LLMs could enable applications to explore important works of literature from India. I don't know that much about India literature, but a comparable work of literature in size and cultural significance might be the Ramayana.
The Ramayana is an ancient Indian epic that tells the story of Prince Rama's heroic quest to rescue his wife, Sita, who has been kidnapped by the demon king Ravana. Set in a world of gods, demons, and celestial beings, the story explores themes of duty, loyalty, and the triumph of good over evil. Guided by wisdom, strength, and the support of devoted allies like Hanuman, the monkey god, and his brother Lakshmana, Rama's journey is a deeply spiritual tale, celebrated for its poetic beauty and moral depth. The Ramayana continues to inspire and captivate audiences across cultures.
The Ramayana story journeyed to Thailand centuries ago, transforming into the Ramakien, a Thai adaptation that retains the essence of the original Indian epic while adding distinctive Thai cultural elements. Introduced through trade, diplomacy, and cultural exchange between India and Southeast Asia, the story became deeply woven into Thailand's art, literature, and performance traditions. Thai kings, particularly King Rama I, adapted and documented the Ramakien, giving it a prominent place in Thai history. Lavishly detailed murals surrounding the Temple of the Emerald Buddha in Bangkok's Grand Palace depict the Ramakien in over 178 panels that totaling over 2 kilometers in length. On a recent visit to the Grand Palace, I imagined having an application that could link the detailed murals to elements of the story in Hindi, Thai, English, Chinese or any language.

The Dream of the Red Chamber, originally titled The Story of the Stone, is one of China's greatest literary works and a masterpiece of world literature. The novel begins with a frame story centered on a magical stone, left over from the Chinese creation myth where the goddess Nuwa mends the heavens. Longing to experience the human world, the sentient stone persuades a Buddhist monk and a Taoist priest to reincarnate it as a boy. This boy, Baoyu, is born into a wealthy and influential family-a character partly based on the author, Cao Xueqin, and his own aristocratic upbringing. Through Baoyu's life, friendships, and romantic relationships, the novel delves into his family's gradual decline, mirroring the instability of China's own noble families in the late Qing dynasty. The story also portrays the era's customs, social structures, and beliefs, offering readers a richly detailed exploration of life in Qing China.
It was a lot of fun to work on this project with tools from LlamaIndex and NVIDIA. With AI technology, GPUs are now essentially sentient stones, and I was able to share this important touchstone of the human experience with my computers using LlamaIndex and open source language models. In turn, RedLM shared with me delightful insights into world of Dream of the Red Chamber.

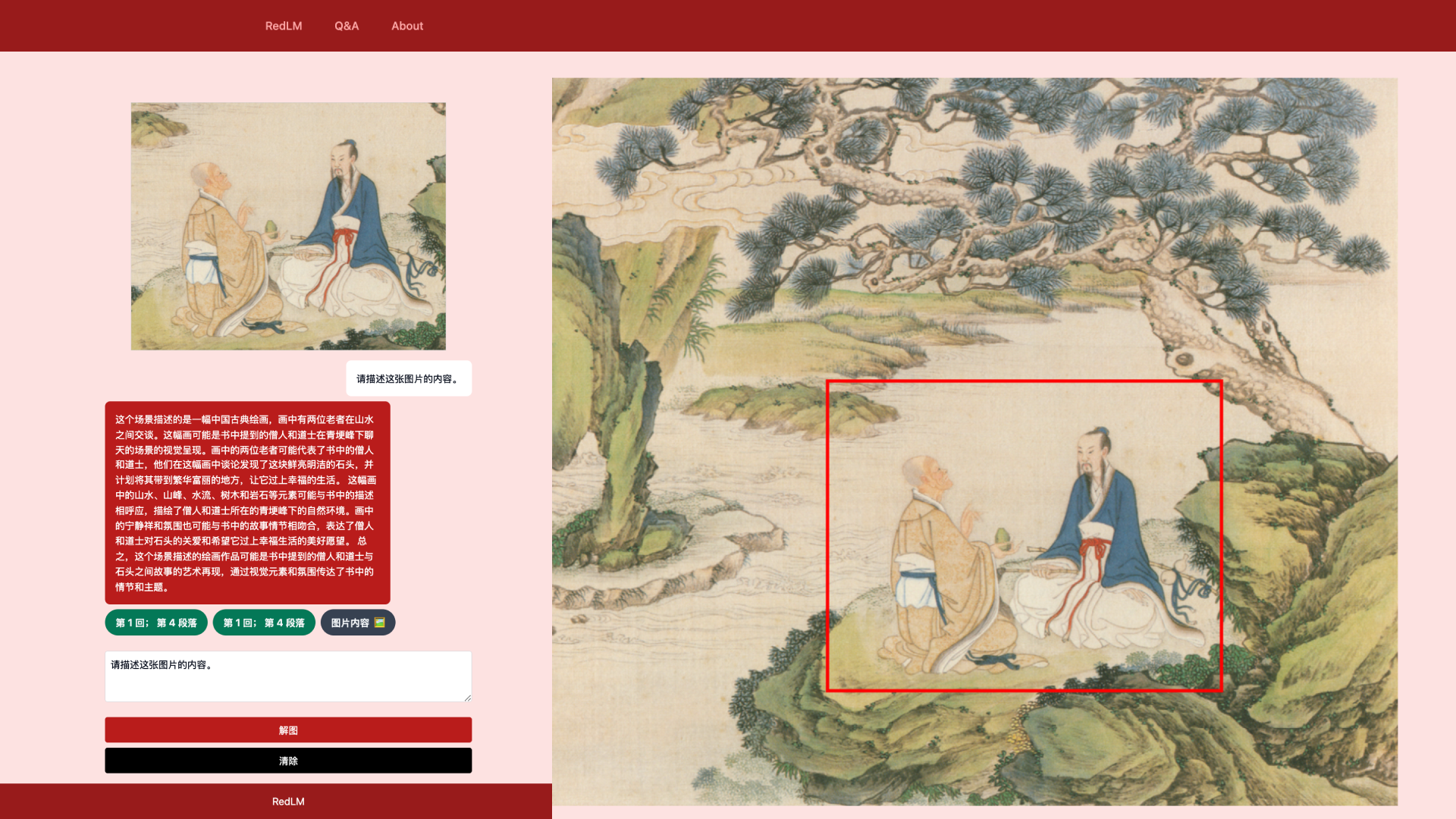
This scene describes a piece of traditional Chinese painting, depicting two elderly figures conversing amidst mountains and rivers. The painting likely visually represents the scene from the book where a monk and a Taoist are chatting at the foot of Qinggeng Peak. The two elderly figures in the painting may represent the monk and Taoist from the book, discussing their discovery of a bright and pristine stone, and planning to take it to a bustling, splendid place for a happy life. The painting's elements-mountains, peaks, flowing water, trees, and rocks-might echo the book's descriptions, illustrating the natural environment at the base of Qinggeng Peak where the monk and Taoist reside. The painting's tranquil and harmonious atmosphere may also align with the storyline, expressing the monk and Taoist's care for the stone and their wish for it to live a happy life. In summary, this painted scene might be an artistic portrayal of the story between the monk, the Taoist, and the stone from the book, using visual elements and ambiance to convey the narrative and themes within the story.