Running MMLU 5-shot on Nemotron Nano Omni with a DGX Spark
Last updated June 18, 2026
This is the first proper LLM evaluation I've run end-to-end, and I learned a ton — both about how evals actually work under the hood and about the infrastructure quirks of running one against a model hosted on my DGX Spark. I scored nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4 on MMLU 5-shot and submitted the result to localmaxxing.com. This post walks through the result with interactive charts, a few example questions, and the setup that got me there.
Headline: 73.5% (95% CI 72.8–74.2, over all 14,042 questions). Random guessing is 25%, so for a sparse MoE model with only ~3B active parameters running at 4-bit, that's a genuinely strong score.
What MMLU actually is
MMLU (Massive Multitask Language Understanding) is 14,042 multiple-choice questions across 57 subjects — everything from abstract algebra to professional law to marketing — grouped into four broad categories (STEM, Humanities, Social Sciences, Other). It's a broad knowledge-and-reasoning test.
A couple of things that surprised me as a first-timer:
- "5-shot" means every question is preceded by 5 fully worked examples from the same subject, so the model learns the answer format before it sees the real question. Those few-shot prefixes make the prompts long (more on that below).
- The model never "writes" an answer. This is the part I didn't expect. The standard MMLU task is scored by log-likelihood: we feed the prompt ending in
Answer:and measure the probability the model assigns to each ofA,B,C,D. Whichever letter gets the highest probability is the model's pick. Because we're reading probabilities directly — not generating text — temperature and sampling settings are irrelevant, and the model's "reasoning" mode never even fires. The score is just the fraction of questions where the top-probability letter matches the answer key.
I ran this with EleutherAI's lm-evaluation-harness (v0.4.9.1, the version localmaxxing pins for this suite).
Where the model is strong and weak
Here's accuracy broken down by category. Social Sciences and "Other" are clearly its strong suits; STEM and Humanities trail.
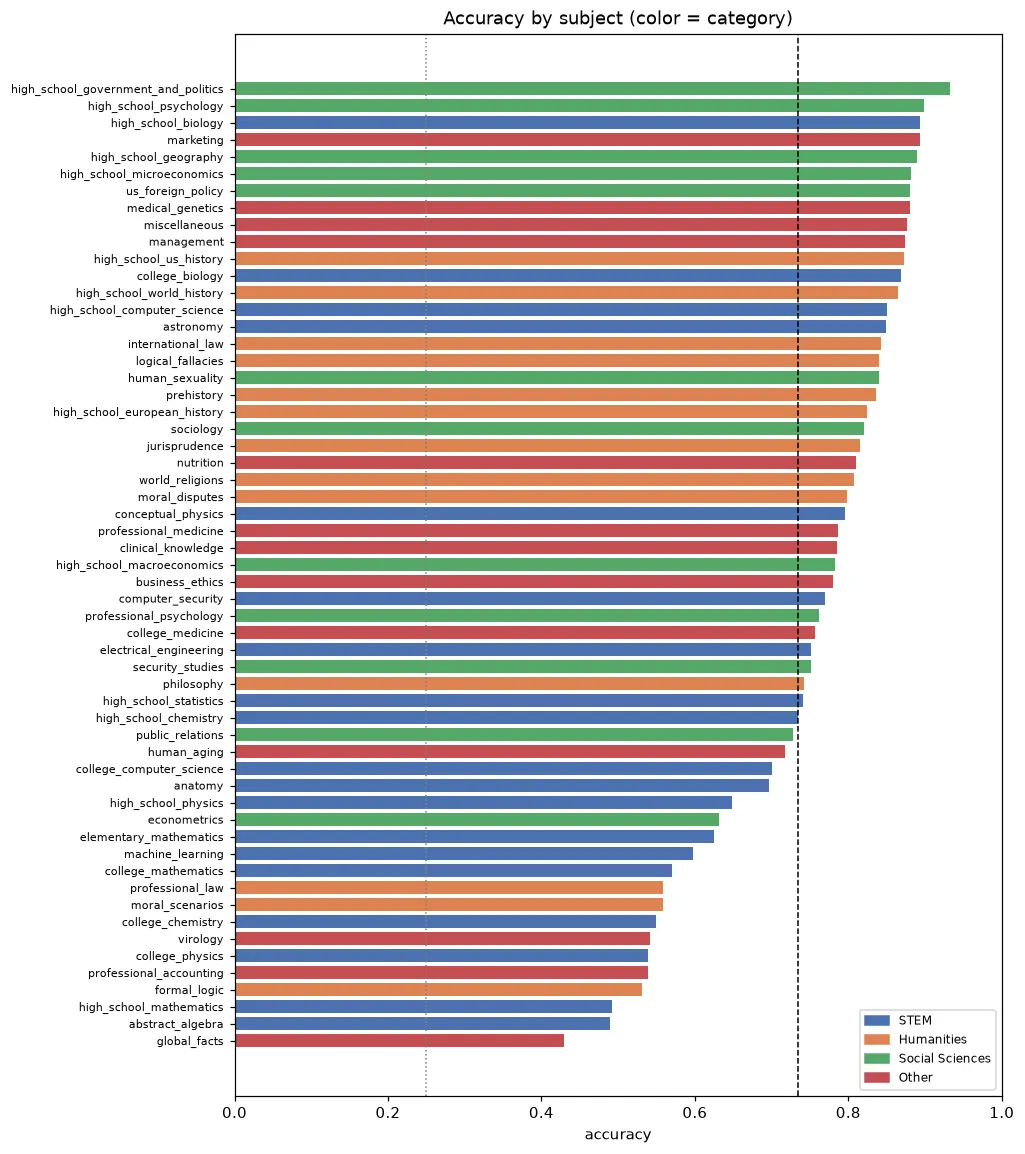
The category averages hide a lot of variance, though. Here's every one of the 57 subjects, sorted weakest to strongest and colored by category (■ STEM · ■ Humanities · ■ Social Sciences · ■ Other). Hover any bar for the exact accuracy and sample size:
The pattern is intuitive: it crushes broad, verbal, "general knowledge" subjects (high-school government & politics 93%, psychology 90%, biology 89%) and struggles with dense symbolic reasoning and niche trivia (global facts 43%, abstract algebra 49%, high-school math 49%, formal logic 53%). Humanities gets dragged down by formal_logic and professional_law, which are really logic/reasoning tests in disguise.
A few questions, up close
Numbers are abstract, so here are three actual questions to give a feel for what the model is being asked.
It nailed this one (high confidence, correct) — miscellaneous:
What kind of angle is formed where two perpendicular lines meet? A. obtuse · B. acute · C. right ✓ (model picked C) · D. invisible
A genuinely hard miss — abstract algebra:
Find the degree for the given field extension Q(√2, √3, √18) over Q. A. 0 · B. 4 ✓ · C. 2 (model picked C) · D. 6
That one requires actually reasoning about field extensions — and note √18 = 3√2 is not independent of √2, a classic trap. The model fell for it.
And one that taught me evals aren't ground truth — computer security:
Three of the following are classic security properties; which one is not? A. Confidentiality · B. Availability ✓ (answer key) · C. Correctness (model picked C) · D. Integrity
The model picked C. Correctness — and it's right. The classic security triad is Confidentiality, Integrity, Availability (the "CIA triad"), so "Correctness" is the one that isn't classic. The answer key says B (Availability), which is simply wrong. MMLU has a well-documented amount of label noise like this, and it's a good reminder that a few points of any benchmark score are just dataset errors. The model got "penalized" here for being more correct than the test.
How long are these prompts, anyway?
Because of the 5-shot prefix, the prompts aren't short. Here's the token-length distribution (measured with the model's own tokenizer):
Mean is ~702 tokens, but the long tail matters: the dense history and law subjects push the longest 5-shot prompt to 3,111 tokens. This bit me before I started — lm-eval's default max_length is 2048, which would have silently truncated ~2.7% of prompts (concentrated in exactly those long-context subjects) and quietly cost me points. Bumping max_length to 4096 captured 100% of prompts with zero truncation.
Does length actually hurt accuracy? A little, but it's mostly a confound — the longest prompts belong to the hardest subjects:
How confident is it — and is that confidence trustworthy?
Since scoring is probabilistic, I can measure confidence as the gap between the top choice's log-probability and the runner-up's. A well-behaved model should be more confident when it's right. It is — the "correct" mass sits clearly to the right of "incorrect":
That separation is exactly what you want to see: when the model is unsure (small gap), it's much more likely to be wrong. It "knows when it knows."
Is it biased toward any answer letter?
A classic failure mode is favoring a position (e.g., always leaning "C") regardless of content. Comparing how often each letter is the correct answer versus how often the model picks it, the bias here is mild — a slight lean toward A/B and away from D:
And when it's wrong, what does it confuse for what? The diagonal is correct picks; off-diagonal shows the (fairly uniform) confusions:
The setup: a DGX Spark, k3s, vLLM, and an off-box eval client
The infrastructure was half the adventure. The model runs on my DGX Spark (GB10 Grace Blackwell, 128 GB unified memory) as a vLLM pod inside a k3s cluster, served NVFP4-quantized with FP8 KV cache. The eval client (lm-eval) ran on my Mac, hitting vLLM over the LAN via the OpenAI-compatible /v1/completions endpoint.
A few hard-won lessons:
- Use the completions endpoint, not chat. Log-likelihood / MCQ scoring needs prompt log-probs (
echo+logprobs), which chat-completion APIs don't expose.local-completionsagainst/v1/completionsis the way. - Run the eval client off the Spark. vLLM pins ~103 GB of the 128 GB unified memory. My first instinct — run lm-eval on the Spark itself — pushed it into a swap death-spiral that throttled vLLM to 25 seconds per request. Moving the client to my Mac (the GPU work stays on the Spark; only orchestration + tokenization moves) fixed it instantly.
- The tokenizer must match the server. I pointed lm-eval at the model's own tokenizer so the context-length bookkeeping for log-prob scoring lined up byte-for-byte with vLLM. Mismatches there silently corrupt scores.
- Checkpoint long runs. The Spark rebooted ~90 minutes in.
--use_cachemeant the completed requests were banked, and a resilient wrapper resumed from the cache and finished the remaining work without losing anything.
The actual command, for the curious:
lm_eval --model local-completions \
--model_args model=nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-NVFP4,\
base_url=http://<spark>:8000/v1/completions,tokenizer=<local-tokenizer>,\
num_concurrent=16,max_length=4096,tokenized_requests=False \
--use_cache ~/mmlu_cache --cache_requests true \
--tasks mmlu --num_fewshot 5 --output_path ~/mmlu-full --log_samples
End to end, the full 14,042-question run took roughly two hours of GPU time on the GB10 at a sustained ~6,500 prompt-tokens/sec.
Takeaways
- 73.5% on MMLU 5-shot is a strong result for a ~3B-active, 4-bit model — competitive with much larger dense models from a year ago.
- Its profile is "broad knowledge generalist": excellent at verbal/social subjects, weaker at symbolic math and logic.
- Evals are not ground truth — label noise is real, and a model can be marked wrong for being right.
- The plumbing matters as much as the model: endpoint choice, where the client runs, tokenizer alignment, and checkpointing all materially affect whether you get a clean number.
The run is submitted to the localmaxxing MMLU 5-shot leaderboard. All 14,042 per-question records (prompt, choices, the four log-likelihoods, prediction, confidence) are retained, so every chart above is reproducible from the raw data.