
Scraping, analyzing and generating companies, founders and job postings from YC's Work at a Startup
最終更新日: January 16, 2021
I always enjoy reading about new batches of YC companies. I came across YC's Work at a Startup (WaaS) recently while browsing HN and got pretty curious about all of the available data points on companies, jobs and founders.
This article will outline my process for collecting, cleaning, visualizing and analyzing the dataset.
After filling out my profile, WaaS recommended 750 matching YC startups which collectively list 1614 open positions. I think this is all of the available job openings and hiring companies, but I'm not sure.
Scraping data
I've used a few different tools to scrape data and automate web browsers. For collecting this data, I ended up just writing some JavaScript directly in the browser console and Ctrl+Saved the page HTML and assets (company logos and founder photos).
// expand each companies to see full details and all postings
const toggleDetails = document.getElementsByClassName("checkbox-inline")[0]
toggleDetails.click()
// automated scrolling, run this until it gets to the end
const scroll = setInterval(() => {window.scrollTo(0,document.body.scrollHeight);}, 3000)
// when it no longer scrolls, clear the interval
clearInterval(scroll)
// expand each job listing:
const jobs = document.getElementsByClassName("job-name")
for (let job of jobs) {
job.click()
}
// now Ctrl+S to save the HTML and images
Parsing the HTML
Next I'll parse the company data into a python list of dictionaries and then dumps it into a JSON file. This code is a little bit scrappy, here's the pseudo code:
# pseudo code for parsing data
html = open("data.html")
parsed_html = parseHtml(html)
companies = []
for company in parsed_html.find_all("company")
# company stats, founders and jobs
company_details = extract_company_details(company)
companies.append(company_details)
with open("output.json", "wb") as f:
f.write(json.dumps(companies))
To scrape the data I used my go-to library for this type of task: BeautifulSoup. There were a few tricky parts:
-
Job details (visa requirements, salary, equity) were all labelled with the same class and they were inconsistent (sometimes salary or equity or both were excluded, for example).
-
Equity was mostly a range of percentages such as
1% - 2%and sometimes a single percentage like1.5%. Some salary ranges had typos like$90k - $10k -
Years of experience required was also inconsistent with mixed types like
3+ Years,Any (recent grad ok)andSenior or Juniors, for example.
These were all pretty easy to account for, it just required some additional logic to handle default values for <div>s that were not included as well as mixed data types and representations where there were inconsistencies.
The resulting JSON structure for the big array of companies looks like this:
[
{
"company_name": "Startup A",
"logo": "logo.png",
"jobs": [
{
"title": "Software Engineer",
"skills": ["python", "javascript"],
"salary": {
"min": 90000,
"max": 110000,
"avg": 100000
}
}
],
"founders": [
{
"name": "Founder Name",
"linkedin": "https://linkedin.com/founder",
"education": "University A",
"image": "abc.png"
}
]
}
]
Analysis
Here are some of the biggest questions I wanted to answer along with some simple python I used for extracting data from the main dictionary/JSON object containing all companies and jobs. For the following code, assume I have read the JSON file back into a python dictionary.
What are the most in demand skills for YC Jobs?
I think skills are included mostly for engineering roles (not so much for sales, marketing, etc.). Here are the top skills:
skills = []
for company in company_list:
if company["jobs"] is not None:
for job in company["jobs"]:
if job["job_skills"] is not None:
for skill in job["job_skills"]:
skills.append(skill)
top_skills = Counter(skills).most_common()
print(top_skills)
I'll try to briefly describe what I know about each of these if I know what it means (without Googling!):
[
('JAVASCRIPT', 330), # I have been using JS a lot recently with Vue
('REACT', 323), # As a prefer to use Vue, I haven't used React in a while
('PYTHON', 312), # I'm a big Python fan, it was the first language I touched, happy to see it near the top!
('AMAZON WEB SERVICES (AWS)', 200), # I like AWS a lot. I have really been enjoying using CDK to build infrastructure
('NODE.JS', 195), # I would to do more with node this year. I generally use Python for web apps
('POSTGRESQL', 132), # I have used Postgres ever since I started using Django and like it a lot
('TYPESCRIPT', 114), # this is another goal of mine for 2021, it seems like an inevitability
('JAVA', 79), # I have never used Java
('SQL', 74), # I usually don't write my own SQL queries; I view SQL through the lense of an ORM
('RUBY ON RAILS', 72), # I haven't used RoR
('CSS', 71), # I like CSS Frameworks. Recently I'm into Tailwind and Material UI. This site uses Tailwind
('HTML', 71),
('DOCKER', 66), # I am a big container fan! It is my preferred way to run software, locally and in the cloud
('KUBERNETES', 58), # I read the Manning book on k8s. I prefer ECS or Swarm, but I might try using it more
('GO', 58), # I haven't ever used Go, but it doesn't look too bad coming from Python
('REACT NATIVE', 58),
('C++', 55), # Also haven't used this, but I have a book on it
('GRAPHQL', 48), # I tried GraphQL and built a HN clone in Django. I prefer REST but I get the appeal (for frontend developers)
('GOOGLE CLOUD', 46), # I'm not a big GCP as I mostly use AWS and Digital Ocean but I would like to try Cloud Run
('RUBY', 44), # I haven't used it
('DJANGO', 44), # Django is my go-to tool for building web apps and APIs. I love the admin, ORM and DRF
('MACHINE LEARNING', 44), # I am familiar with some ML techniques but not very well practiced
('MONGODB', 43), # Have used it before, but I try to use the postgres JSONField for storing NoSQL data when possible
('IOS', 38), # I have an iPhone, but haven't used a Mac in a long time, mostly on Linux and Windows
('MYSQL', 36), # I tend to use Postgres, I don't think I've ever used this
('ANDROID', 35), # Not something I have worked with
('DATA ANALYTICS', 32), # I do a lot of this
('GIT', 30), # I'm very slowly trying to learn advanced git features. I have many abandoned "rebase-practice" repos
('ANGULAR', 29), # I tried it once for about an hour, I know that people love to hate it, I'm just not sure why
('SWIFT', 29), # This is apparently a very popular language and has use cases outside of mobile development, but I've never used it
('LINUX', 28), # I spend lot of time using Linux machines, mostly Ubuntu.
('SOFTWARE ARCHITECTURE', 24), # I like using diagrams.net to draw application infrastructure
('KOTLIN', 23), # I think this is a framework for Java/Android?
('TENSORFLOW', 22), # Google DL/ML library that I'll try to use later in this article
('DISTRIBUTED SYSTEMS', 22), # Using AWS, I guess I have technically designed distributed systems but I wouldn't call it one of my skills
('PHP', 22), # I almost learned it to support a WordPress site but opted to use JAMStack instead
('DATA WAREHOUSING', 22), # I have used Google BigQuery before which I think counts for this skill
('DEEP LEARNING', 20), # I'm going to try to use this later in this article
('DATA MODELING', 20), # To me this means writing Django models, or thinking about how to structure an API/json data, etc.
('C#', 19), # Micrsoft language used for different things including game dev with Unity
('FLASK', 19), # I'm familiar with it but mostly prefer Django's batteries included philosophy
('C', 19), # In learning about Linux I have read a bit of C, but never written any
('REDIS', 18), # Fast, in memory key-value store with multiple data types. I use it for a few different things
('MICROSERVICES', 18), #
('COMPUTER VISION', 17), # I once used OpenCV on my Raspberry Pi
('EXPRESS', 15), # I'd like to learn how to use this in 2021
('BASH/SHELL', 13), # I'm not very fluent in bash but
('OBJECTIVE-C', 13), # I haven't used this but I know it is popular for iOS development
('FIREBASE', 12), # I have played around with Firebase, but I haven't built anything with it
('SCALA', 11), # Functional programming language for JVM, I haven't used it
('SOFTWARE SECURITY', 11),
('UNITY', 11), # I used this once before to play around with VR development for HTC Vive
('R', 11), # I haven't used R before, and I would probably reach for a Python library for doing statistics or ML-related things
('KAFKA', 10), # I haven't used it but I'm familiar with the ideas behind Kafka.
('SPARK', 10), # I haven't used it and I'm not really sure what it is
('ELASTICSEARCH', 10), # I haven't used it before
('ETL', 10), # Extract, Transform and Load
('NATURAL LANGUAGE PROCESSING', 10),
('HEROKU', 10), # I used this when first learning about Django, haven't used it in a while
('NGINX', 9), # I use NGINX in most of my web apps as a reverse proxy
('JENKINS', 9), # I haven't used it, I am a big GitLab fan and will use that whenever possible
('RUST', 9), # I have read the Rust book and have played around with WASM
('IMAGE PROCESSING', 8),
('SERVERLESS', 8), # I currenty use Fargate and have also used Lambda and SQS and some other serverless AWS tools
('BLOCKCHAIN', 8),
('OPENCV', 8),
('CAD DESIGN', 7), # I am a big fan of SketchUp and I'm familiar with Blender as well, but I'm not sure if these qualify as CAD design
('JQUERY', 7), # It was the first library I worked with when I started learning javascript
('HADOOP', 6), # It is related to map-reduce, I haven't used it before and I don't really know what it is. I know it is related to HDFS
('.NET CORE', 6), # I haven't used it
('TCP/IP', 6), # I'm familiary with the basics
('ELIXIR', 6), # I don't know, I think it is a framework for Erlang
('INTERNET OF THINGS (IOT)', 5),
('SASS', 5), # I think it is a framework for CSS. I frequently see node-sass errors from npm
('OPENGL', 5),
('DYNAMODB', 5), # I am familiar with it but haven't used it
('GOOGLE APP ENGINE', 5), # I haven't used it before
('UNIX', 4),
('SPRING FRAMEWORK', 4), # A Java web framework that I haven't used
('CUDA', 4), # I have used it indirectly when I used nvidia-docker to used Tensorflow
('DART', 4), # I don't know what this is
('ERLANG', 4), # A language that handles concurrency very well
('RABBITMQ', 4), # Message queue, I have used it before but tend to use Redis as a message broker
('KERAS', 4), # A helper/wrapper library for Tensorflow
('SCSS', 4), # I think this is a language that compiles to CSS. CSS frameworks that I use use this
('ML', 4), # I've read some books and experimented but I'm not a regular practitioner
('MATLAB', 4), # A tool her programming with higher math
('SPRING', 4), # A Java web framework. Not sure if different from Spring Boot. Never used it.
('CASSANDRA', 4), # FB scalable database (NoSQL I think?) that does sharding really well
('HIVE', 3), # Not sure what hive is. I think it related to Hadoop
('PUPPET', 3), # Configuration management tool that I haven't ever used
('REDSHIFT', 3), # AWS version of Google BigQuery
('SQL SERVER', 3), # Not sure what this refers to, specifically.
('GROOVY', 3), # I think this is a Java framework?
('VERILOG', 3), # I've never heard of this.
('TORCH/PYTORCH', 3), # FB python deep learning library.
('CLOJURE', 3), # A LISP derivate, functional language
('MICROSOFT AZURE', 3), # I've used Azure AD and thats it.
('HBASE', 2), # I don't know what this is
('RDS/AURORA', 2), # I use RDS and experimented with Aurora but don't know when/why to use it
('FIRMWARE', 2), # What's between hardware and software
('ABAP', 2), # I don't know
('ARDUINO', 2), # I have one, but don't use it
('MICROCONTROLLERS', 2), # Arduino might be an example of what this is
('SOLIDITY', 2), # Don't know what this is
('UNREAL ENGINE', 2), # Unity competitor, used for game development
('COFFEESCRIPT', 2), # I think it is a dialect of JS, but I'm not sure
('LUA', 2), # I think this is what redis is written in, but I'm not sure how to descbribe what it is
('MACOS', 2), # I haven't used MacOS in a long time. I'm tempted to try M1, but I also want to buid a new PC...
('NEO4J', 2), # A graph database, I'm not sure what a typical use case is for this
('INFORMATION SECURITY', 2), # Unknown unknowns
('REINFORCEMENT LEARNING (RL)', 2), # Not sure what this refers to specifically
('DEVICE DRIVERS', 2), # Probably involves writing kernel modules
('EMBEDDED LINUX', 2), # Not sure if Raspberry Pi is an example of this or not
('ELASTIC STACK (ELK)', 1), # Useful for viewing log data (Elastic, Logstash and Kibana), haven't used it
('IIS', 1), # I don't know
('ORACLE', 1), # A big software company and a proprietary database (I think Django supports it)
('F#', 1), # A programming language that I don't know anything about
('SQLITE', 1), # A light-weight SQL-compatible file-based database
('HASKELL', 1), # A functional programming language that I don't know
('SCHEME', 1), # I'm not sure, it may be something related to LISP
('MS SQL', 1), # Never used this
('MARIADB', 1), # An open source SQL database
('MAVEN', 1), # I think it is a Java Framework
('SEARCH', 1), # I don't know what this refers to
('OCAML', 1), # I think I once read that high-frequency traders like to use this language, but I'm not sure why
('JULIA', 1), # A programming language used for math and statistics
('GPU PROGRAMMING', 1), # I haven't done this before, probably uses C++
('HACK', 1), # FB's version of PHP
('XAMARIN', 1), # I dont't know what this is
('CORDOVA', 1), # I think it is a tool for generating native apps from JS
('SAS', 1), # I don't know what this is
('ASSEMBLY', 1), # Low level language that gives instructions to CPU
('XML', 1), # A data format, I use it for this site's sitemap and RSS feed
('MEMCACHED', 1), # Used for caching. I haven't used it; I typically use redis where this might be an option
('LESS', 1), # I think is is related to CSS?
('AMAZON ECHO', 1) # I once built an open source Echo on a raspberry pi
]
The list above gives a count of the different skills in all job postings sorted by the most common skills. But what about the most common skills listed together with any given skill? This would allow us to answer questions like "what skills appear most frequently along with JavaScript?"
We can find this with by doing:
skills_frequency = defaultdict(lambda: defaultdict(lambda: 0))
for company in company_list:
if company["jobs"] is not None:
for job in company["jobs"]:
if job["job_skills"] is not None:
job_skills = job["job_skills"]
skill_tuples = itertools.permutations(job_skills, 2)
for skill_tuple in skill_tuples:
first = skill_tuple[0]
second = skill_tuple[1]
skills_frequency[first][second] += 1
pprint.pprint(
{
key: sorted(value.items(), key=lambda kv: -kv[1])
for key, value in skills_frequency.items()
}
)
What are these companies working on?
Here's a wordcloud made from the short company descriptions:

import json
import random
from collections import Counter
from os import path
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from wordcloud import WordCloud, STOPWORDS
HTML_FILE = "waas_data.json"
with open(HTML_FILE, 'r') as j:
company_list = json.loads(j.read())
company_names = [company.get("company_name", " ").lower() for company in company_list]
company_description_list = [company.get("company_desc", " ").lower().replace(".", "") for company in company_list]
company_descriptions = " ".join(company_description_list)
wc = WordCloud(background_color="white", width=1920, height=1080, max_words=500, stopwords=STOPWORDS, margin=10,
random_state=1).generate(company_descriptions)
default_colors = wc.to_array()
plt.figure(figsize=(40, 40))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.savefig('company_description_wc.png')
plt.show()
Here's a breakdown of YC companies by category and sub category:
Salary, Equity and Years of Experience
Here's a scatterplot showing average salary and average equity for positions categorized by years of experience required.
Logos
Here's a look at about 600 of the 750 logos that were made available in the list of companies. The logos are sorted by their average hex color, which puts them on a gradient of dark to light:
import os
import PIL
from PIL import Image
from IPython.display import display, Image as IPyImage
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
%matplotlib inline
LOGO_DIR = 'data/waas_full_details_dump_files/'
yc_logos = [LOGO_DIR + x for x in os.listdir(LOGO_DIR) if x.endswith('.png')]
def average_img_hex(img):
"""
https://www.hackzine.org/getting-average-image-color-from-python.html
"""
img = Image.open(img)
# leave out images not in RGB/RGBA mode
if img.mode in ["LA", "P", "L"]:
return
# resize the image to 1 pixel and get the average hex value
img2 = img.resize((1, 1))
color = img2.getpixel((0, 0))
average_hex = '#{:02x}{:02x}{:02x}'.format(*color)
return average_hex
# sort images by average hex value
sorted_images = sorted(
[(average_img_hex(img), img) for img in yc_logos if average_img_hex(img) is not None],
key=lambda x: x[0]
)
images = sorted_images[:600]
fig, axes = plt.subplots(20, 30, figsize=(30, 15), sharex=False, sharey=False)
for img, ax in zip(images, axes.flat):
ax.imshow(mpimg.imread(img[1]))
ax.axis('off')
plt.savefig('yc.png')
plt.show()
There are a lot of logos that have a similar design to Stripe's logo. Rose/peach/pamplemousse colored logos also seem to be popular.
Founders
Let's take a look at the founders. I came across the deepface PyPI project an was impressed at how accurately it can classify face data.
Here's a sample of YC Founder headshots:

Here's how I used the deepface library to add race, gender and age data for each of the headshot images:
IMG_DIR = 'data/waas_full_details_dump_files/'
# headshots are all .jpg files, so we can get all headshots like this:
founder_headshots = [x for x in os.listdir(IMG_DIR) if x.endswith('.jpg')]
founder_count = len(founder_headshots)
img_paths = [IMG_DIR + x for x in founder_headshots]
results = {}
for idx, img in enumerate(img_paths):
print(f"analyzing {idx}/{founder_count}")
try:
img_key = img.split("/")[-1]
obj = DeepFace.analyze(
img_path=img,
actions=['age', 'gender', 'race', 'emotion'],
enforce_detection=False
)
obj.update({"img": img_key})
results[img_key] = obj
except ValueError as e:
print(e)
with open("founder_images.json", "w+") as f:
f.write(json.dumps(results))
There are more steps needed to transform this data to make it compatible for use with a histogram showing age, race and gender. Check out the Jupyter notebook linked at the end of this article to see the code used to make this data transformation. Here's a simple way to count founders grouped by race and gender:
race_and_gender_count = defaultdict(lambda: 0)
for result in list(results):
obj = results[result]
gender = obj["gender"]
race = obj["dominant_race"]
# use (race, gender) tuple as defaultdict key and increment
race_and_gender_count[(race, gender)] += 1
sorted(race_and_gender_count.items(), key=lambda x: x[1], reverse=True)
[(('white', 'Man'), 771),
(('asian', 'Man'), 217),
(('latino hispanic', 'Man'), 134),
(('indian', 'Man'), 117),
(('middle eastern', 'Man'), 111),
(('black', 'Man'), 84),
(('white', 'Woman'), 52),
(('asian', 'Woman'), 17),
(('latino hispanic', 'Woman'), 13),
(('indian', 'Woman'), 4),
(('black', 'Woman'), 1)]
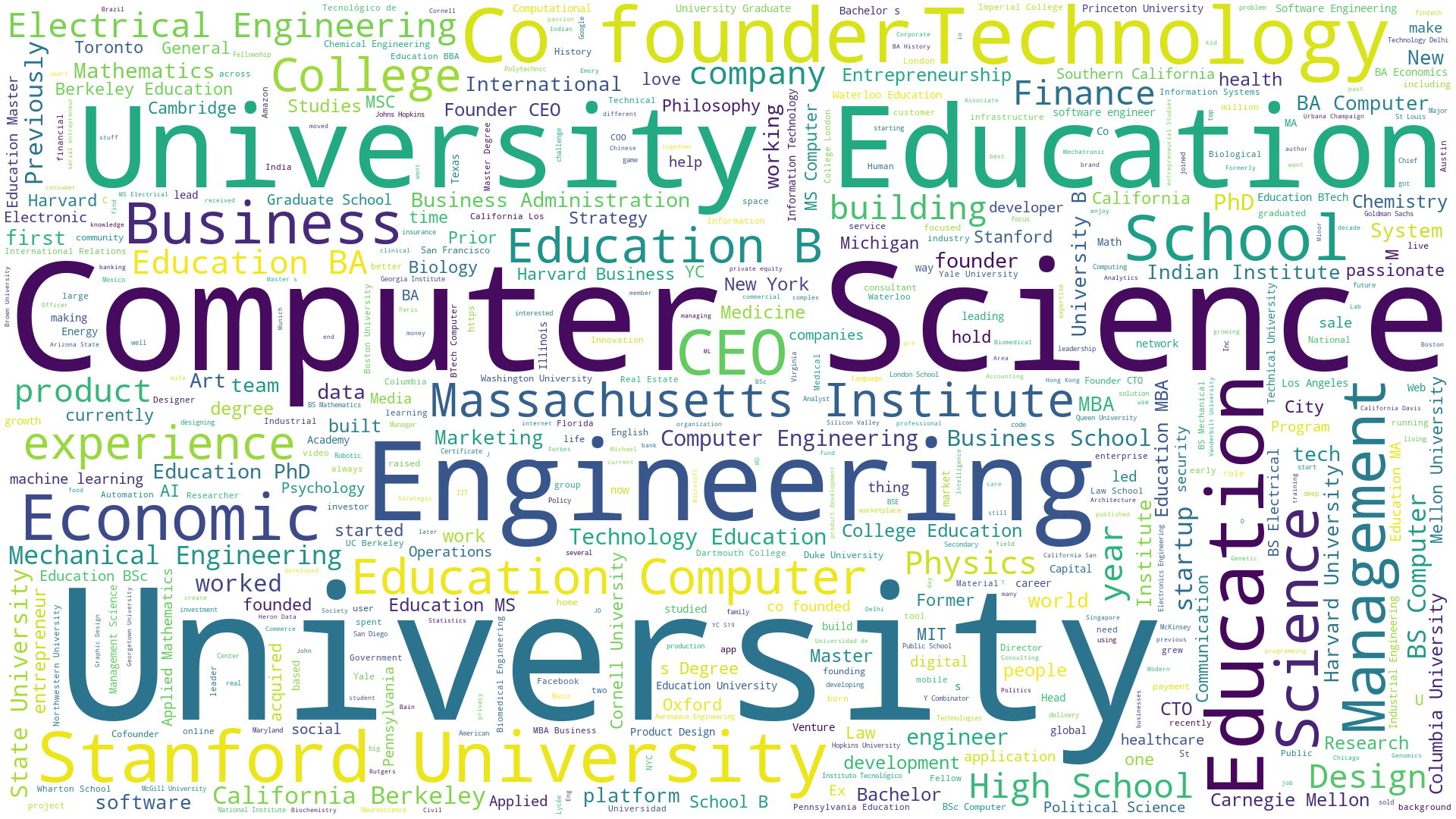
Founder background wordcloud
Here's a wordcloudsshowing founder background, education and experience. The code for this is similar to the wordcloud shown previously for company descriptions.
Generating YC Startup Companies
Finally, I'll try to generate some plausible descriptions of YC companies based on the descriptions of companies scraped from WaaS. I have read about big advancements made in text generation with GPT-3, but otherwise I'm not familiar with text-generation or any other generative models.
My initial goal was to do this using a simple example that I could replicate locally using Tensorflow. Googling for text generation with python tensorflow led me to this tutorial: https://www.thepythoncode.com/article/text-generation-keras-python. I was able to run the example, but the results were not very good, at least not as good as the results used in the example of generating text from a model trained on the text of "Alice in Wonderland". This is probably because I ran 10 epochs instead of 30, but I didn't want to wait hours before getting results for each iteration.
Another Google search led me to this article on Max Woolf's Blog which I was able to get started with in just a few minutes. I combined the text from the 2 sections of the longer company descriptions: description and technology.
Here's the link to the Google Colab (anyone can view and comment):
https://colab.research.google.com/drive/1u9b-FVGgUGcfifLy7bUXgoPe-pZ81rm3?usp=sharing
Google Colab gives you access to an environment with a GPU suitable for working with GPT2. Here's an overview of the code used to train GPT2 on the company descriptions:
%tensorflow_version 1.x
!pip install -q gpt-2-simple
import gpt_2_simple as gpt2
from datetime import datetime
from google.colab import files
This installs gpt-2-simple and gives us access to the Google Drive connected to the Google account used to sign in to Google Colab.
The GPU can be inspected with:
!nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 51C P8 10W / 70W | 0MiB / 15079MiB | 0% Default |
| | | ERR! |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 51C P8 10W / 70W | 0MiB / 15079MiB | 0% Default |
| | | ERR! |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Next we download the GPT-2 model:
gpt2.download_gpt2(model_name="124M")
Then we mount Google Drive with the following command:
gpt2.mount_gdrive()
With our file (waas.txt) uploaded to Google Drive, the following
file_name = "waas.txt"
gpt2.copy_file_from_gdrive(file_name)
Now the model needs to be fine-tuned:
sess = gpt2.start_tf_sess()
gpt2.finetune(
sess,
dataset=file_name,
model_name='124M',
steps=1000,
restore_from='fresh',
run_name='run1',
print_every=10,
sample_every=200,
save_every=500
)
Here are some results from my first attempt at using Google Colab. Training the model will output a sample after every 200 steps. I have included only the first sample from the training, but you can see the output from each step in the Colab notebook.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/gpt_2_simple/src/sample.py:17: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
Loading checkpoint models/124M/model.ckpt
INFO:tensorflow:Restoring parameters from models/124M/model.ckpt
0%| | 0/1 [00:00<?, ?it/s]Loading dataset...
100%|██████████| 1/1 [00:00<00:00, 1.00it/s]
dataset has 128333 tokens
Training...
[10 | 28.79] loss=3.60 avg=3.60
[20 | 50.75] loss=3.30 avg=3.45
[30 | 73.39] loss=3.25 avg=3.38
[40 | 96.80] loss=3.18 avg=3.33
[50 | 121.40] loss=3.12 avg=3.29
[60 | 145.52] loss=3.10 avg=3.26
[70 | 169.15] loss=2.56 avg=3.16
[80 | 193.06] loss=2.46 avg=3.07
[90 | 217.28] loss=2.59 avg=3.01
[100 | 241.38] loss=2.49 avg=2.96
[110 | 265.33] loss=2.34 avg=2.90
[120 | 289.30] loss=2.52 avg=2.86
[130 | 313.46] loss=2.37 avg=2.82
[140 | 337.69] loss=2.38 avg=2.79
[150 | 361.84] loss=1.92 avg=2.73
[160 | 385.94] loss=2.25 avg=2.70
[170 | 410.01] loss=1.73 avg=2.63
[180 | 434.10] loss=1.66 avg=2.58
[190 | 458.18] loss=1.25 avg=2.50
[200 | 482.22] loss=1.47 avg=2.44
======== SAMPLE 1 ========
to improve the usability of our Services and to provide better
offline features through offline messaging. Our Platform
connects users from across the country to collect data on
non-US citizens abroad, and then gives US citizens a secure and
authentic online presence while keeping their identities
private. Our mission is to enable Americans to be more secure
in online world. We do this by putting a damper on online
threats while preventing online attacks and slowing down the
spread of cyberthreats. Backed by a world class Series A and B
investments from leading technology firms, including Shas
Ventures and Y Combinator, we\'re an organization that believes
in doing what is right. We\'re built to last and provide an
experience that\'s built to last.\xa0We\'ve partnered with some
of the world\'s top law enforcement institutions including the
Washington DC Metropolitan Detention Center, National Domestic
Relations Task Force, Lambda Legal, Lambda Legal National Labs,
NIMBYs Angels of San Francisco and Rally Labs provide legal
technology & community education, as well as legal assistance/
cure treatments. We\'re a tech firm that\'s built to last ‘lots
of years 🙏. We\'ve solved some really really hard problems in
the past, and haven\'t forgotten.We\'re a team of passionate
engineers, machine learning researchers, and business
executives from Y Combinator and Naval Institute. We\'ve just
closed our Series B and C funding, and\'s back at it with two
more large-scale brothels and a bona fide law firm dedicated to
bringing brothels to the people. Join us on this next chapter
in our journey, and help us build the next Clark County jail.
We\'re looking for guys who can quickly learn leadership roles
and fill in for leaders, not executives. We like to take what
we learn and apply it to real problems. ReactJS, Node, Django,
Postgres, and a sprinkle of AWS. ReactInfrastructure serves
Express-like functions in the cloud. Our customers are law
firms and other third-party service providers, largely
comprised of tech startups. Our customers are generating
billions of dollars in revenue through our platform every
year. Come join us and help us transform this dynamic into a
platform-as-a-works. Rippling uses the following
technologies:React Native JavaScriptFast, clean,
nativeCSS3Deterministic executionReact NativeScriptWeb appLync,
typescriptArchitecture-as-a-systemResponsible for maintaining
and expanding the Ethereum and Bitcoin infrastructure. We\'re
based in New York City, and are backed by the VC-leading
venture firms in the space. Our flagship product, Rippling, is
an intuitive phone-in-a-person phone banking solution that
integrates an RFID reader and password manager, as well as
password managers dedicated to managing assets and managing
cards. Users can create portfolios and trade on the Rippling
marketplace, or access the technology to create their own
portfolios on the Bitcoin and Ethereum markets. Simply put,
Rippling is 21+ year old inventors. We\'ve reinvented banking
by making money available today through an open API. Banks now
have an easy path to secure assets, including a digital wallet
and code backed by an AllinAir’s digital asset portfolio. We
are a small team of computer scientists building tools that
improve customer experience, reduce wait times for businesses,
and increase transparency in banking. Our platform runs on very
little electricity, minimal mechanical power, and is 100x more
robust 20 than traditional DPG/PGD systems. The system stores 1
watt of energy and 8 watts of power per watt signal in a
standard APS-C (Advanced Plasmon Super Capacitor Stacker).
Cells in our cell-resistant cell-glide-based sprays secrete a
protein that is targeted to trigger cell death, called a T
cell. This triggered death is what causes breast cancer.
Stacking together our diverse array of biological and chemical
biology and chemical pathologies, and building in new energy
efficiency technology to power our smart consumer products,
we\'re taking our users on an exciting journey toward modern
energy efficiency. We are a team of computer scientists located
in Barcelona, Spain, and we are focusing on the extremely first
and foremost research and development applications in renewable
energy. Current RCP is the largest R&D and R&E net for the 21st
century, automating substantial paperwork and providing
essential modern services. With the exception of emergency
services and work, we are unaffected by the most common types
of CO2 emissions including man-made nitrous oxide, human-made
CO2, and volatile organic compounds. Current RCP delivers the
highest quality, highest efficiency possible, including
equipment, software, waste management, and notification
systems, all in a modern, integrated and convenient way. By
using RCP, consumers, businesses, civil society, researchers
and others around the world can save money on power bills,
reduce emissions and waste, receive timely assistance from the
energy sector and be
[210 | 517.61] loss=1.62 avg=2.40
[...]
[1000 | 2448.17] loss=0.07 avg=0.47
Saving checkpoint/run1/model-1000
WARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/training/saver.py:963: remove_checkpoint (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file APIs to delete files with this prefix.
Here's a sample generated using the trained model:
We are a small team of MIT-trained researchers and entrepreneurs based in Palo Alto, California. We're creating a new form of transportation for people and gear. Based in the heart of downtown LA, our downtown L.A. location will be the last remaining obstacle preventing people from making, selling, and visiting the Smithsonian. We're building a disruptive technology that impacts the way people interact in the world in a positive way. Token Transit is digitizing much of the way we travel for real. We are building it to work for everyone, digitizing billions of things we buy and sell every day. Our platform connects real users and non-users in a global network. Our first product, UNITY, made it from scratch and is in mixed state. We are helping to develop the first truly international distributed logistics network powered by an AI and a IoT. Our mission is to revolutionize how companies move containers, trucks, and other loads across borders. Our technology is being architected and being implemented by experts across the globe. Our annual revenue:$150M/year. How we work We are a small, fast growing company with a core team based in San Francisco, CA. Our software is being used by thousands of customers worldwide. We are building our technology platform in two key areas: (1) automated supply chain forecasting for companies and (2) internal analysis of company data to help leaders analyze and improve production. Our YearEnd blog is currently looking for Senior Electricians & Candidates. If you're excited about this exciting challenge, please apply. Burrow is a daily driver app for mobile that works on any device. With Burrow, your driver is on your phone to show your friends where you are going, which destinations you are on, and more. You can also add your phone to a list and get in-depth insights into the driving itself. We love to tie in-stream data, visualised by React Native, to the driving experience. We also take a data-driven approach to managing our customer list, managing our teams and our operations framework. Our API serves a large amount of native API functions, and using Cockroach to access these functions through microservices allowed us to interface with the relevant services (e.g. DynamoDB, Picnic and our own API). We also inserted a lot of debugging and monitoring functionality into the ecosystem. Our API serves a large amount of data - including relational and non-relational data - about where you are and what you've wanted to do the longest, what you've got, and where you are now. We also manage a lot of the operations of the platform and provide some of the data integrations with your existing relational and non-relational data. Technologies we use NodeJS, React, Apollo, Postgres, Heroku, Docker, and Tensorflow: Fluttertable, Datapoint, Pandas, Keras, Numpy, Scipy, Scikit, SciPy, scikit-learn AI-ron at MERN Automation is a Google-backed NARability company that is committed to being the leading platform for accurately measuring and diagnosing agricultural production. We have built proprietary software and software automation systems to make it easy for any government to track agricultural production and prices. Our primary technologies today are:Tables, Entry Points into Global Food Production, Pipeline and Grain Market, and GenomicData.utility.Upstream is revolutionizing how U.S. agriculture is produced and sold. We are serving the agronomists, farmers, market researchers, and data scientists in the USA. WWrendy is on a mission to enable breakthrough scientific research in agricultural technology. We are growing cassava in our bioreactors, improving crop health and producing more durables than we need to feed ourselves. We use machine learning to identify cancer-causing microbes in seeds and in consumer durables to make food more accessible and more sustainable. We are building an entirely new technical infrastructure for agricultural diagnostics: tractors, biores, and tractors-all with a singular goal of improving yields and feed the world. We have humble beginnings as a grocery delivery service and have since grown to serve millions of people every year. We are a tight-knit team of MIT-trained researchers, technologists, and businesspeople, who have built an industry-leading technology platform that uses sensors and software to analyze crop production data to create intelligent and efficient food products. Our mission is to help all farmers have a more sustainable crop, by using microbial discoveries to improve the health and prosperity of their communities. We're a well-funded, well-funded, yuletide startup. We're looking to grow and affordably upgrade our tech stack every year. We use less expensive tools and techniques to analyze and build comprehensive datasets on crop production and food safety to help farmers grow more food and avoid over-production. Rails / React / AWS We build, manage, and cybersecurity insurance through an on-premise platform. We
From this first attempt there are already a few ideas for YC startups:
We are helping to develop the first truly international distributed logistics network powered by an AI and a IoT. Our mission is to revolutionize how companies move containers, trucks, and other loads across borders. Our technology is being architected and being implemented by experts across the globe.
We have built proprietary software and software automation systems to make it easy for any government to track agricultural production and prices.
Next we can try improving the output by using some additional features of gpt-2-simple. One important setting is the size of the model. There are three released sizes of GPT-2:
124M(default): the "small" model, 500MB on disk. This is the one used on my first try355M: the "medium" model, 1.5GB on disk.774M: the "large" model, cannot currently be finetuned with Colaboratory but can be used to generate text from the pretrained model (see later in Notebook)1558M: the "extra large", true model. Will not work if a K80 GPU is attached to the notebook. (like774M, it cannot be finetuned).
We can try again using the 355M model. The large and extra large models won't work for our use case of finetuning the model on our sample text.
This would be a great time to plug my startup, but I don't have one. Instead, here are 10,000 startup ideas I generated with GPT-2 trained on the 335M model using the YC company descriptions for finetuning:
gpt2.generate_to_file(sess,
destination_path=gen_file,
length=150,
prefix="we are building the world's first",
temperature=0.7,
nsamples=10000,
batch_size=20,
)
Credits, Links and Learning Resources
Here's a link to Max Woolf's blog which has a lot of helpful resources on using GPT-2. Max is the author of gpt-2-simple which is the Python package used in the Google Colab (Max is the author of that Google Colab as well):
Here are some resources for learning more about text generation. I came across Jay Alammar's blog which has a lot of great visualizations:
Jay also has a great YouTube channel:
Here's the link to the source markdown file for this article: https://github.com/briancaffey/briancaffey.github.io/tree/master/content/2021/01/16
Here's a link to the repo containing all of the scraped data and Jupyter notebooks used for exploring the data: https://gitlab.com/briancaffey/yc-waas-data
Here's the link to the Google Colab used for generating company descriptions with GPT-2 and gpt-2-simple: https://colab.research.google.com/drive/1u9b-FVGgUGcfifLy7bUXgoPe-pZ81rm3?usp=sharing#scrollTo=8DKMc0fiej4N
Thank you for reading!