
Agents of Inference: My submission for NVIDIA's Generative AI Agents Developer Contest by NVIDIA and LangChain
Last updated June 17, 2024
Update
Version Note: This article was published in June 2024. The models and services referenced (Meta-Llama-3-8B-Instruct, build.nvidia.com services, Stable Diffusion) may have updated versions since publication. Check official documentation for the latest releases and breaking changes.
I recently posted another article about optimizing this project with TensorRT and TensorRT-LLM running on local NVIDIA NIM inference microservices, please have a look here: https://briancaffey.github.io/2024/06/24/agents-of-inference-speed-of-light-nvidia-langchain-generative-ai-agents-developer-contest-update
tl;dr
“Agents of Inference” is my entry for the Generative AI Agents Developer Contest by NVIDIA and LangChain. This project aims to integrate techniques for generating text, images and video to create an application capable of producing short thematic films. In this article, I will detail how I developed the project leveraging LangGraph—a library for building stateful, multi-actor applications with LLMs--and hybrid AI workflows using NVIDIA AI-powered tools and technologies running on RTX PCs and in the cloud.
Here's my project submission post on 𝕏:
Agents of Inference
— Brian Caffey (@briancaffey) June 17, 2024
🍸🤵🏼♂️⚡️🎥🎬#NVIDIADevContest #LangChain @NVIDIAAIDev pic.twitter.com/VT3rgzFbD6
Here's a link to the Agents of Inference code repository on GitHub.
NVIDIA's Generative AI Agents Developer Contest
AI agents are having a moment. They are the building blocks for building "applications that reason", and LangChain is a company that provides a comprehensive set of tools for developing, deploying and monitoring AI agents. I have struggled to understand how I can build or use agents in my own projects, and with the contest I have been able to just scratch the surface of what is possible with AI agents--but I think it is a promising paradigm for developing AI-driven applications.
Coming up with an idea
I love stable diffusion. I closely follow the development of the three leading applications for generating images with stable diffusion models: Stable Diffusion WebUI, InvokeAI and ComfyUI. Write a prompt, instantly see the result, tweak the prompt and generate again. This is the basic process by which I have previously used stable diffusion. It is a satisfying mental exercise that feeds the creative and imaginative part of my brain. My idea for this project came from wanting to automate this process: use large language models to build cohesive scenes and detailed prompts and then feed them into my stable diffusion programs via API. Using LangChain and LangGraph allowed me to rapidly prototype the idea and start generating short feature films in the style of my favorite British Secret Agent: 007.
Putting together the puzzle pieces
Here's how I set up an MVP for my project to get started. I set up a simple graph (a linked list, really) that included the following nodes. *Important: in this context, a node is an agent, and that agent is a simple Python function. It takes one parameter which is the state, a Python dictionary, that holds the output of LLM calls that the agents make. Not all nodes make LLM calls, some just run basic functions like initializing directories or calling external stable diffusion APIs.
- Casting Agent → come up with some characters
- Location Agent → come up with some locations
- Synopsis Agent → write a synopsis based on the characters and locations
- Scene Agent → write some number of scenes based on the synopsis based on the synopsis
- Shot agent → describe some number of camera shots for each scene based on the scene
- Photography agent → take each shot description and generate and image
- Videography agent → take each image generated by the photography agent and convert it to a 4 second clip using stable video diffusion
- Editor agent → compile the movie clips together
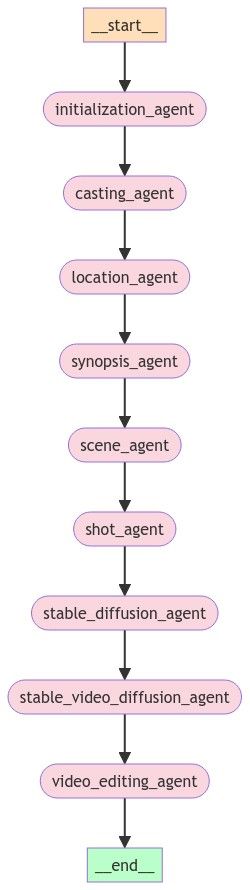
It may look simple, but there is a lot going on in this graph.
Casting and Location
The first two agents in my graph are tasked with generating characters and locations that would appear in a British secret agent film. The prompts used for these agents are as follows:
casting: "Come up with four to five characters who will appear in an upcoming British spy movie. The list should include the main character who is male, the villain, an attractive female actress who eventually falls in love with the main character, and some other characters as well."
locations: "Provide three main locations that can be used in an international British Spy movie. The locations should include a variety of cities, remote environments, iconic landmarks, etc. The locations should make for good background scenes for an action movie with lots of stunts, chases, explosions, fights, etc. and other things you would find in an action movie. Be sure to include the country and a description of the environment where these places are."
These agents leverage the LangChain Expression Language (LCEL) to generate structured output based on Pydantic models. For
class Character(BaseModel):
"""
The type for character that the casting agent casts for a role in the movie
"""
full_name: str = Field(description="The character's name")
short_name: str = Field(description="The character's short name")
background: str = Field(description="The character's background")
physical_traits: str = Field(description="The physical traits of the character")
ethnicity: str = Field(description="The character's ethnicity")
gender: str = Field(description="The character's gender, either male of female")
nationality: str = Field(description="The character's nationality")
main_character: bool = Field(description="If the character is or is not the main character")
LCEL offers wonderful syntactic sugar, I can use this model in a parse and pip that into the output from the mode:
chain = prompt | model | parser
This results in our structured data:
cast:
- background: Former MI6 agent
ethnicity: British
full_name: James Alexander
gender: Male
main_character: true
nationality: British
physical_traits: Tall, dark hair, blue eyes
short_name: Jamie
I saved the state for all "Agents of Inference" invocations in the output directory of my agents-of-inference GitHub repo. I didn't commit the images and videos, but you can follow @AgentInference on X to see more of the results from my development process and future improvements, as well!
Synopsis Agent
With a cast of characters and locations selected, we need a synopsis to determine what happens. Here's the prompt:
synopsis: |
Generate a synopsis for a British spy agent movie in the style of the James Bond series. The synopsis should include the following elements:
Protagonist: A charismatic and skilled British secret agent with a code name (e.g., "Agent X") who works for a top-secret government agency (e.g., MI6).
Antagonist: A formidable villain with a grand, sinister plan that threatens global security. The antagonist should have a unique, memorable persona and a well-defined motivation.
Mission: Outline the high-stakes mission that the protagonist must undertake to thwart the antagonist’s plan.
Gadgets and Vehicles: Mention the cutting-edge gadgets and vehicles that the protagonist uses throughout the mission. These should be inventive and integral to the plot.
Action Sequences: Include a brief description of some thrilling action sequences, such as car, boat, plane chases, hand-to-hand combat, and daring escapes, and dangerous situations.
Big Reveal: There is a big reveal toward the end of the storyline that is surprising and the reveal helps to move the story along.
Climactic Showdown: Describe the final confrontation between the protagonist and the antagonist. This should be intense and action-packed, leading to a satisfying resolution. Should include details about the main character is victorious.
Setting: Ensure that the settings are diverse and visually striking, adding to the overall excitement and suspense of the story. This should involve multiple locations in exotic environments, the wilderness, in dangerous situations, on board planes, trains, boats and fancy cars, etc.
Tone and Style: Maintain the sophisticated, suave, and adventurous tone that is characteristic of the James Bond series. Include elements of intrigue, romance, and humor.
The synopsis to any good film is key, so I decided to use a feature of LangGraph that would allow a synopsis_review_agent to provide multiple rounds of feedback to the synopsis_agent to make it even better. Here's what the new graph look like after implementing the synopsis_review_agent using conditional graph edges:
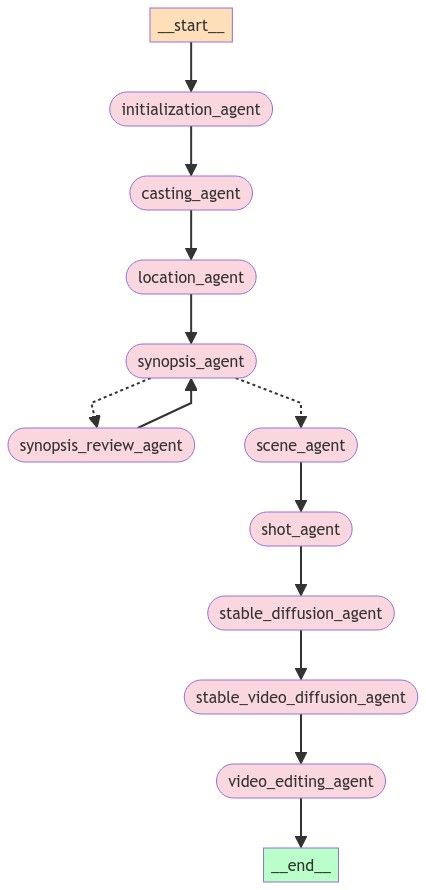
Conditional edges are a very powerful feature and I just used it in one part of my graph. Other parts of the graph could benefit from this as well, and they can allow for "human-in-the-loop" interactions which are becoming very popular in AI-powered applications.
Scene and shot agents
With our perfected synopsis, we are ready to put more agents to work. The scene agent builds out the basic structure of the storyline. It provides a structured list of the main sections of the movie. The shot agent then loops over the scenes and creates a number of different shots for the given scene. This was an effective way to have consistent thematic content for shots within a scene. Here are the prompts I used for the scene and shot agents:
scenes: |
Create a list of detailed scenes for an exciting and entertaining British spy film. The scenes should be comprehensive and include all scenes necessary for a complete film. Each scene should include the following elements:
Location: Describe the location and setting of the scene, including any notable landmarks, time of day, and general atmosphere.
Characters Involved: List the main characters present in the scene, with a brief description of their roles and appearances.
Description of What Happens: Provide a detailed account of the action, and key events that take place in the scene.
shot: |
You are a film director working on a new British spy film and your writers have provided you with a scene. Your task is to come up with four to five shots that will be filmed during the scene. The shot descriptions needs to be specific and should include a variety of closeup shots on characters, environment shots that consider the scene location and shots of specific items or other things that are featured in the scene. Each shot should also have a title. The description should be a brief densely worded block of text that captures the important elements of the scene. Consider the style of camera angle, lighting, character expressions, clothing, and other important visual elements for each shot. Be very descriptive. The description will be used to generate an image of the shot. Also, there should be at most one actor for each shot that contains people. Don't use the name of the character, instead use a physical description of the character based on their physical traits described below if needed. Also consider what the actor is wearing in the description.
Stable Diffusion and Stable Video Diffusion agents
The stable diffusion agent makes an API call to a local instance of the Stable Diffusion WebUI API, saves the generated image and saves a reference to that image in the state:
- description: A medium close-up shot of Ethan Jameson's face, with a concerned expression,
as he reads the message from Natalie Jackson. The lighting is dim, with only a
single lamp on his desk casting a warm glow. His eyes are narrowed, and his brow
is furrowed in concentration. He is wearing a dark blue suit and a white shirt.
image: 000.png
title: Ethan's Concerned Expression
video: 000.mp4

With the perfectly prompted image in hand, we can use Stable Video Diffusion to bring it to life. I prompted phind to come up with a FastAPI service that would accept an image in a post request and return a short video created with stable video diffusion using the diffusers library.
Stable video diffusion can generate about 4 seconds of text at 7 frames per second. This isn't great, but I was able to use ffmpeg to do frame interpolation bringing the frame rate to a much smoother 14 fps using motion compensated interpolation (MCI):
ffmpeg -i output/1718453390/final.mp4 -crf 10 -vf "minterpolate=fps=14:mi_mode=mci:mc_mode=aobmc:me_mode=bidir:vsbmc=1" output/1718453390/final.14fps.mp4
Finally, the editor_agent uses moviepy to join the clips together into a single video.
Development environment
I struggled to optimize the meta-llama/Meta-Llama-3-8B-Instruct with TensorRT-LLM, so I ran LLM inference on a combination of older Llama2 TensorRT-LLM models, and Meta-Llama-3-8B-Instruct on LM Studio (which I found to be painfully slow compared to TensorRT-LLM).
If you provide an NVIDIA_API_KEY in the .env file, LLM calls will be made using the meta/llam3-70b-instruct model on build.nvidia.com/meta/llama3-70b. In fact, build.nvidia.com also provides stable diffusion and stable video diffusion inference via API. This would be very convenient in the event that my RTX PCs become compromised.
My RTX 4090 GPU with 24 GB of memory was able to run lots of different inference servers concurrently (LLM, Stable Diffusion WebUI, ComfyUI, InvokeAI, Stable Video Diffusion FastAPI service), but I generally stuck to doing one type of inference at a time, otherwise things would grind to a hault or crash. I also experimented with ChatTTS, a new text-to-speech model.
I developed this project on a MacBook Pro, and I used my RTX PC as if it were a remote service providing inference for text, images and video. This is a helpful mindset when working with hybrid AI workflows that leverage inference services both on local machines and in the cloud.
How it works
To run the program, you need to install python dependencies and then run an OpenAI compatible LLM and Stable Diffusion WebUI server with the --api flag. You also need to run the Stable Video Diffusion service. Apologies for any hardcoded local IP address in the source code. Deadlines, you know! With everything configured, you can run the following command:
~/git/github/agents-of-inference$ poetry run python agents_of_inference/main.py
## 📀 Using local models 📀 ##
## 🎭 Generating Cast 🎭 ##
## 🗺️ Generating Locations 🗺️ ##
## ✍️ Generating Synopsis ✍️ ##
## going to synopsis_review_agent ##
## 📑 Reviewing Synopsis 📑 ##
## ✍️ Generating Synopsis ✍️ ##
## going to synopsis_review_agent ##
## 📑 Reviewing Synopsis 📑 ##
## ✍️ Generating Synopsis ✍️ ##
## going to scene_agent ##
## 📒 Generating Scenes 📒 ##
## 🎬 Generating Shots 🎬 ##
## Generated 5 shots for scene 1/5 ##
## Generated 5 shots for scene 2/5 ##
## Generated 5 shots for scene 3/5 ##
## Generated 5 shots for scene 4/5 ##
## Generated 5 shots for scene 5/5 ##
000/0025
A medium shot of a bustling Tokyo street, with neon lights reflecting off wet pavement. Jim Thompson, dressed in a black leather jacket and dark jeans, walks purposefully through the crowd, his piercing blue eyes scanning the area. The sound design features the hum of traffic and chatter of pedestrians.
Generated image output/1718426686/images/000.png
001/0025
A tight close-up shot of Emily Chen's face, her piercing brown eyes intense as she briefs Jim on the situation. Her short black hair is styled neatly, and she wears a crisp white blouse with a silver necklace. The camera lingers on her lips as she speaks, emphasizing the importance of the information.
Generated image output/1718426686/images/001.png
Generated video output/1718426686/videos/000.mp4
== stable video diffusion generation complete ==
Generated video output/1718426686/videos/001.mp4
== stable video diffusion generation complete ==
Demo Video for Contest Submission
Agents of Inference
— Brian Caffey (@briancaffey) June 17, 2024
🍸🤵🏼♂️⚡️🎥🎬#NVIDIADevContest #LangChain @NVIDIAAIDev pic.twitter.com/VT3rgzFbD6
Making this video was a lot of fun. The "Agents of Inference" highlight reel includes some of the most interesting, exciting and fun clips that I found in the dozens of short films it created. It is important to note that a lot of the content is not very good. Misunderstood prompts, color confusion (prompt includes green eyes, but other things in the scene are also conspicuously green), unrealistic or noisy motion from Stable Video Diffusion--these are some of the issues you will find in the films. Generating AI images sometimes feels like panning for gold: you go through a lot of sediment to get a few good flakes.
Also, I added a few short animations that I made with Blender. The final scene shows the NVIDIA Omniverse orange humanoid from the barrel of a pistol. I think we are rapidly approaching a future where agents can generate full-scale theatrical movies by generating OpenUSD code, directly or indirectly. Maybe for the next NVIDIA Developer contest!
Shortcomings of my project
My goodness, how embarrassing. There are quite a few shortcomings that can be easily identified looking over the output and the source code. Here are a few:
Character variety
When generating characters I would frequently see one named Dr. Sophia Patel who is apparently a brilliant cryptologist. Other characters would often have different names or backgrounds, but I saw Dr. Sophia Patel more often than not.
Character consistency
The characters are not consistent. This is a notoriously difficult problem to solve, but I made a lot of progress on it during this contest. I experimented with calling the ComfyUI API to run a custom workflow built with the ComfyUI graph-based workflow tool for face transfer:
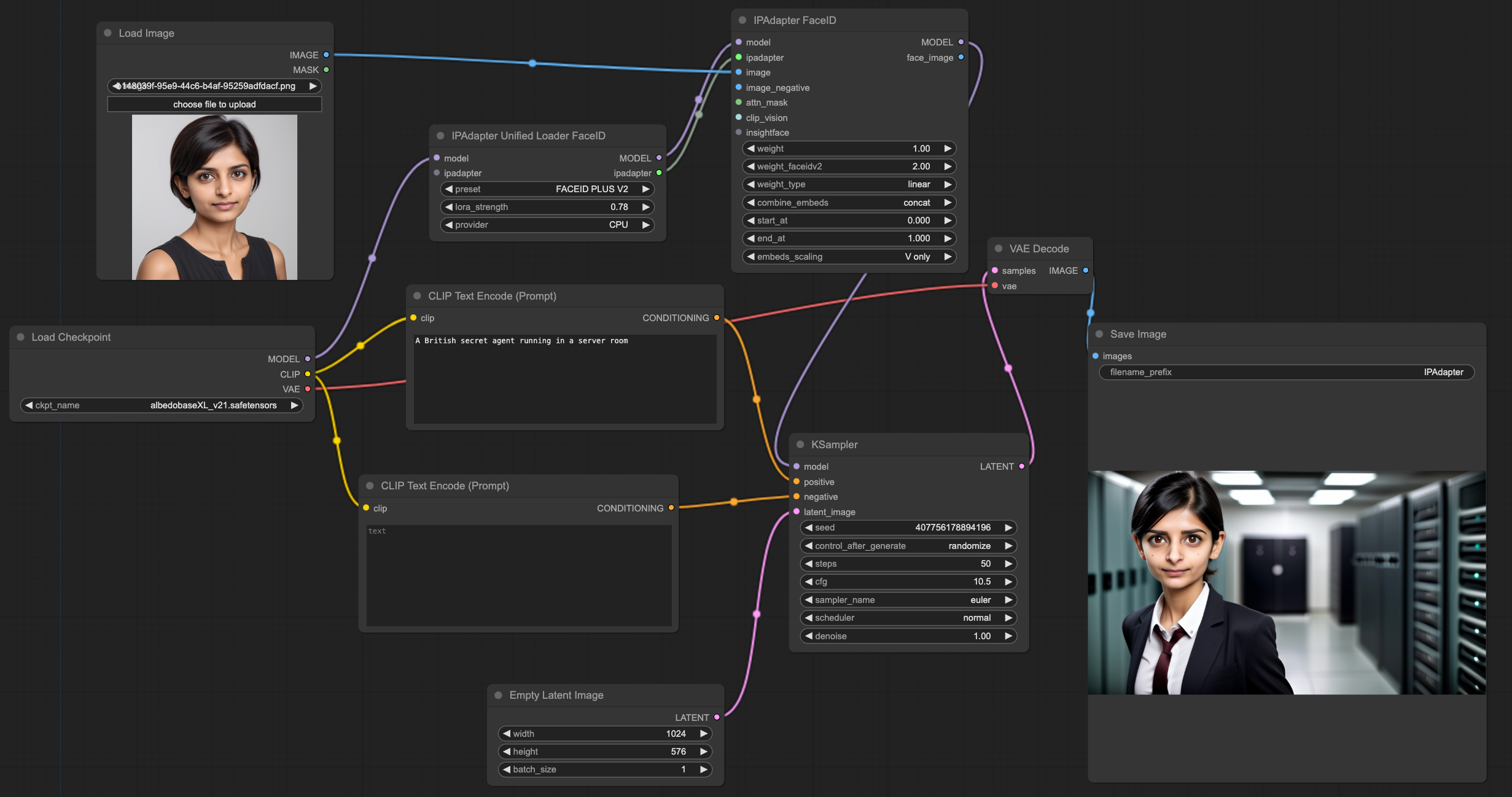
Using ComfyUI would be nice, but it wouldn't be as easy to tap into cloud APIs if my workflow heavily relied on ComfyUI server with custom models.
Understanding LangChain
I started out with the idea I would store all LLM calls to a local JSON to serve as a cache, allowing me to avoid regenerating responses from early in the workflow. This worked well, until I tried to serialize an Annotated list (required for cycles such as the one used with synopsis_review_agent). I ended up wasting a lot of time trying to figure this out, and I came across some built-in LangChain features for storing state in memory and in Sqlite. I'm sure there are other areas where I used the wrong pattern, but I turned over a lot of stones and look forward to continuing development with LangChain.
What's next?
Thank you to NVIDIA and LangChain for organizing this contest. It was a great way to explore a powerful toolset for automated content generation using AI agents.
Video models like Dream Machine and Sora have made some big splashes on the internet and the results are remarkable. However, I'm still almost more interested in finding the limitations of quality content using open-source models on consumer hardware like RTX GPUs.
I would also have loved to generate my own music for these films. I am a Suno poweruser and love the songs I have generated on that site. Will the gap between video and music generation on private, payed services and local machines? Or does it just need time to catch up? Hopefully a future installment of "Agents of Inference" will integrate music and voice, and can't wait to hear it!