
Agents of Inference: Speed of Light -- Accelerating my Generative AI Agents project with NVIDIA NIMs, TensorRT and TensorRT-LLM
Last updated June 24, 2024
tl;dr
"Agents of Inference: Speed of Light" is an update to my original entry for the Generative AI Agents Developer Contest by NVIDIA and LangChain. This update focuses on how I accelerated local text, image and video generation using TensorRT, TensorRT-LLM and NVIDIA NIMs. You can read the original article about "Agents of Inference" here.
Here's my original project submission post on 𝕏 that introduces the idea of generating short 007-style films using agents, LLMs and stable diffusion:
Agents of Inference
— Brian Caffey (@briancaffey) June 17, 2024
🍸🤵🏼♂️⚡️🎥🎬#NVIDIADevContest #LangChain @NVIDIAAIDev pic.twitter.com/VT3rgzFbD6
Here's a link to the Agents of Inference code repository on GitHub.
NVIDIA NIM inference microservices
I thought NVIDIA NIMs was one of the most exciting announcements from GTC 2024. I'm a big fan of using docker containers everywhere, and the idea of standardizing NVIDIA tools and dependencies seemed to make a lot of sense. I had previously struggled to get TensorRT-LLM installed on Windows using example repos provided by NVIDIA.
A few weeks ago NVIDIA announced that NVIDIA NIMs can be downloaded and run anywhere. I was able to download this NIM for the meta/llama3-8b-instruct model:
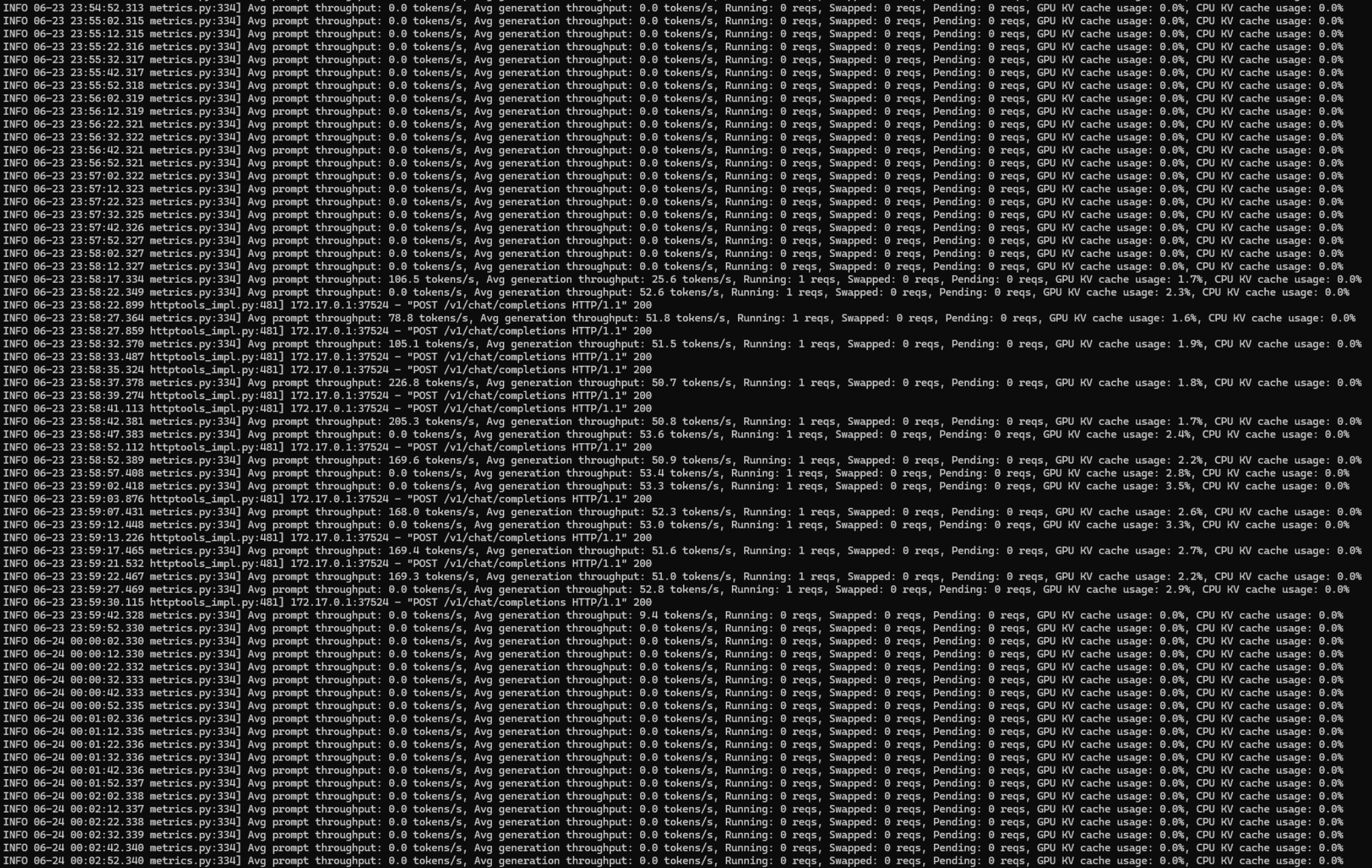
Here are the logs for my NVIDIA NIM Meta/Llama-3-8B-Instruct running in docker container on Windows Subsystem for Linux on my NVIDIA GeForce RTX 4090 GPU-powered PC. Notice that it generates over 50 tokens per second!
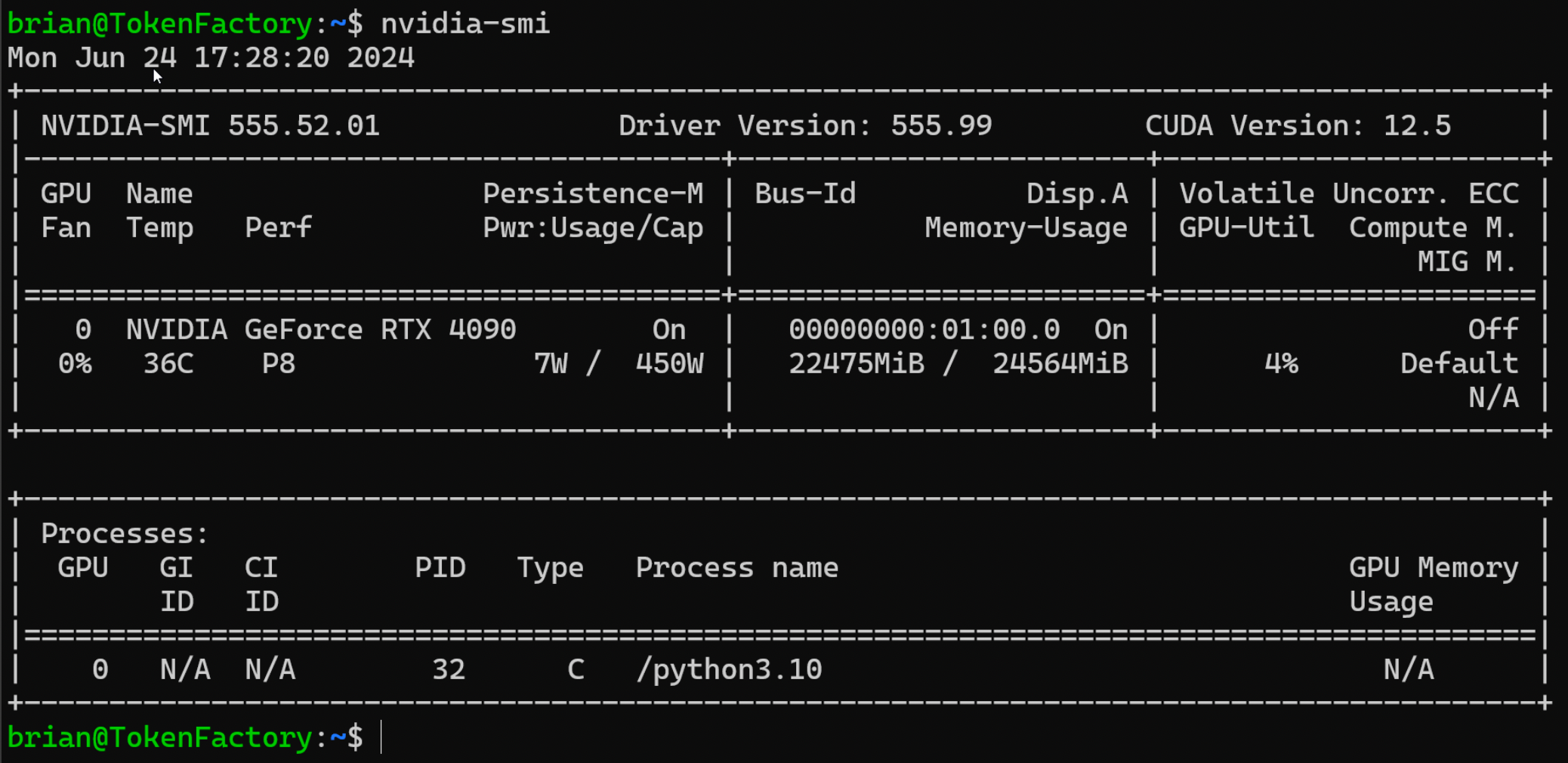
The one main hurdle I faced when running the NIM local was an error about no runnable profiles being available:
ERROR 06-23 15:41:21.19 utils.py:21] Could not find a profile that is currently runnable with the detected hardware. Please check the system information below and make sure you have enough free GPUs.
SYSTEM INFO
- Free GPUs: <None>
- Non-free GPUs:
- [2684:10de] (0) NVIDIA GeForce RTX 4090 [current utilization: 7%]
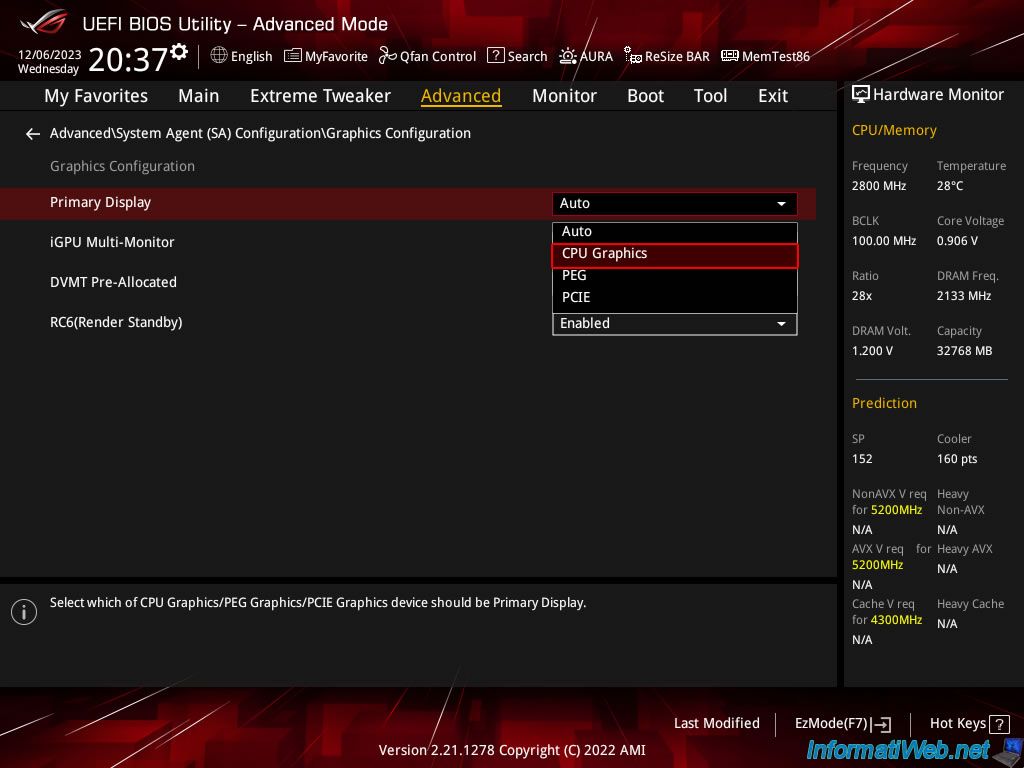
This seemed odd, and I found another user with the same issue on the NVIDIA Developer Forum. I was able to get around this by going into the EUFI/BIOS of my PC and switch to integrated graphics:
It was great to be able to run "Agents of Inference" using NVIDIA NIM because it is just as simple as running a docker container:
export CONTAINER_NAME=llama3-8b-instruct
export IMG_NAME="nvcr.io/nim/meta/${CONTAINER_NAME}:1.0.0"
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
Before getting this to work, I was able to get a /chat/completions endpoint working with the Llama3 model on my fork of the trt-llm-as-openai-windows. I borrowed code for the TrtLlmAPI from the NVIDIA/ChatRTX repo and a function from llama-index called messages_to_prompt_v3_instruct which encodes messages with special tokens for chat. This was an interesting exercise and it taught me a lot about how LLMs do chat. I would like to continue working on this fork and see how to implement streaming endpoints for the Llama 3 model.
Here is how Llama 3 does the instruct prompting:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful AI assistant for travel tips and recommendations<|eot_id|><|start_header_id|>user<|end_header_id|>
What can you help me with?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Compare this with how it was done with Llama2 chat:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message_1 }} [/INST] {{ model_answer_1 }} </s>
<s>[INST] {{ user_message_2 }} [/INST]
You can read more about the difference between Llama 2 and 3 on the Model Card & Prompt formats page on Meta's Llama website.
LangSmith
I recently started using LangSmith. It is an awesome product and it ties in really well to doing prototype work like in my project "Agents of Inference". I wish I had started using it earlier in my development cycle! All you need to do is add an API key to your environment and your application automatically starts tracing LLM calls. It also works well with LangGraph and allows you to trace the execution path of your graph. Also it is good to be aware that there are other products similar to LangSmith like LangFuse. I also saw a really neat demo from Datadog at GTC showing an alpha version of their LLM tracing and observability product.
LangSmith can also be helpful when the wrong JSON shape is parsed. I had a lot of difficulty with this in my project. When I used the Q4_K_M gguf quantized Meta-Llama-3 8B-Instruct model I had no issues with output parsing. Switching to the TensorRT-LLM model provided by the NIM resulted in some parsing errors. The application would report that JSON could not be parsed because the result contained text like: "Here is the JSON that you requested". I was able to get around this by changing the prompt template from:
Answer the user query.
to
Don't include ANYTHING except for valid JSON in your response. Answer the user query.
This was the most frustrating part of development, and I'm still getting occasional errors that I just skip over. I'm also probably have not exhausted all of the tools that LangChain provides to avoid these types of errors. Don't assume that output parsing that works with one model will work with another! This is another good reason to use something like LangSmith when developing LLM-based applications.
ComfyUI TensorRT
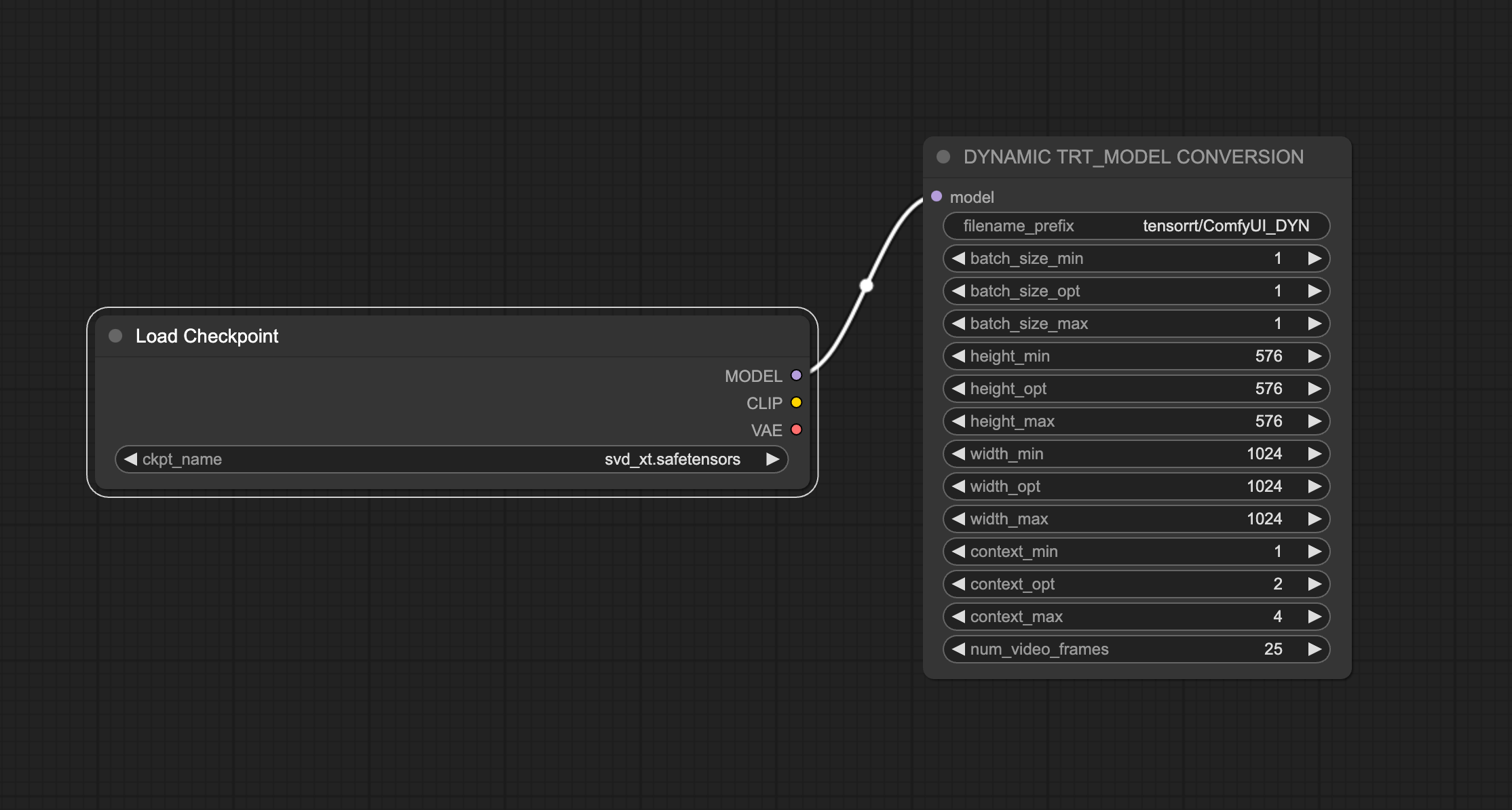
My goal with "Agents of Inference" was to be able to test out how small upstream prompt changes can impact the quality and consistency of a series of generated images and videos. Iteration speed is very important! I was able to significantly speed up image and video generation by using the ComfyUI TensorRT custom nodes. These nodes allow you to build engines with specifications for parameters that can be either static or dynamic. I had better luck with building dynamic engines. I was able to build and use engines for Stable Diffusion SDXL and Stable Video Diffusion XT.
Building a TensorRT engine for ComfyUI can be done using the following workflow:
The engines can then be used in custom workflows like the following:
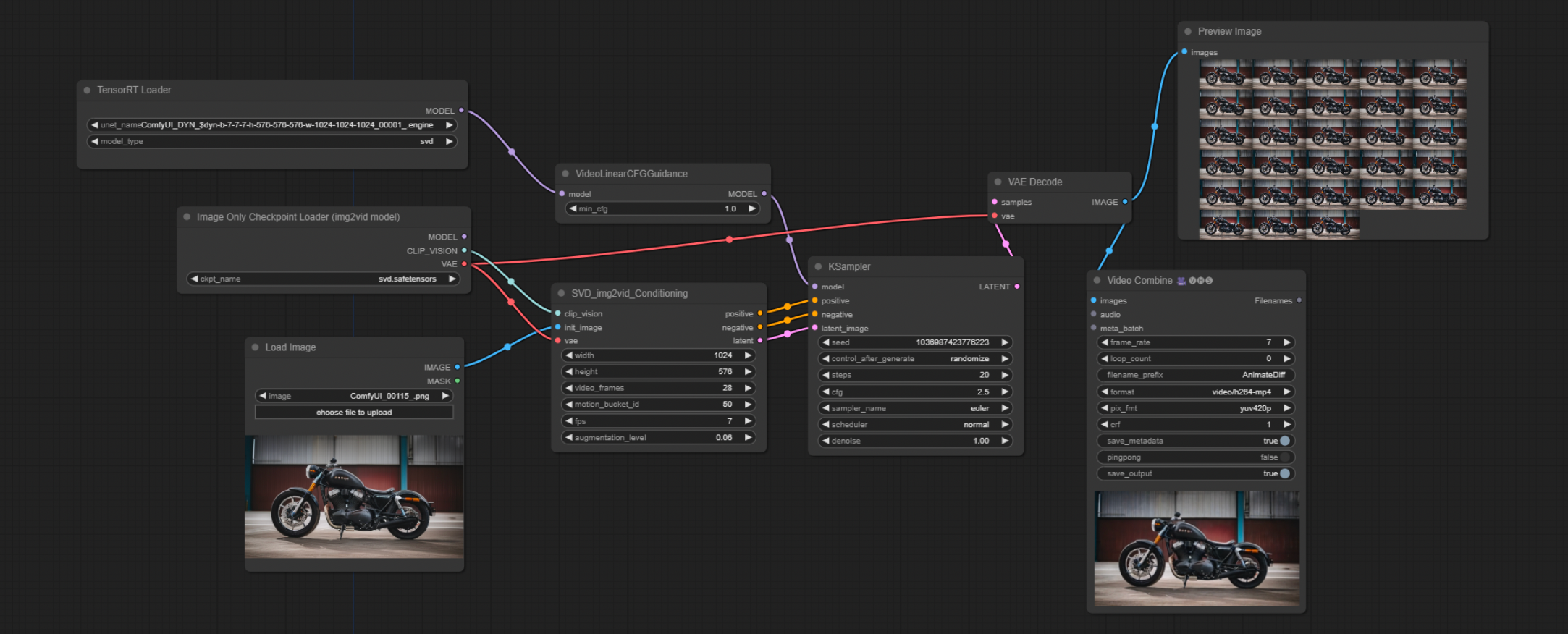
Once these workflows are configured and are working as expected, you can export them in API format (JSON) and use them to make API calls to the ComfyUI backend. The agents for stable diffusion and stable video diffusion made API calls in this way and it worked pretty well.

Using 50 iterations, I was able to generate 1024x576 images in 3 seconds or about 19 iterations per second (it/s). Videos
ComfyUI is still early in development and it refers to itself as "alpha software" even though it has a large adoption by a very active community already. I'm excited to see what is next from the developers of ComfyUI.
Speed of Light
"Speed of Light" is a term that I learned from a stable diffusion talk at GTC.
SOL analysis reveals how your code performs, and device utilization compared to relevant maximums.
Adding TensorRT and TensorRT-LLM to inference services on my RTX PC helped increase the throughput of text, image and video generation for my "Agents of Inference" project. I'm looking forward to learning more about profiling and optimization techniques for both LLMs and Stable Diffusion workloads.
Thanks again to NVIDIA and LangChain for organizing this contest! It was a lot of fun to learn about builing agents with LangChain and LangGraph and the latest developments from NVIDIA in Generative AI.